
来源知乎
作者:小川Ryan
不知道是因为上了年纪(x),还是因为周围的同学研究的方向更多样化了,发觉自己对于研究选题这件事变得比以前更包容了,从之前的一直关注某个或者某几个研究方向到现在觉得只要细心观察,很多方向都会有一些值得研究的科学问题。随着关注的问题的逐渐变多,也有了一些自己的感受
国内的研究和国外的研究
每次会议放榜之后都会有不少的PR文,很有意思的是国内的PR文画风相当多都是“我组共有n篇文章被国际顶级xx会议接收”,“我组xx成果登顶xx榜单,显著超过人类表现”,好像人类都是脑子长到三岁以后就不发育了
但twitter上的画风就很不一样了,除了一些公司release大模型的时候,许多researcher在上面excited地分享自己的新发现,尽管这些新发现在很多人看来也并没有什么用
事实上这也涉及到国内和国外研究风格的差异,国内的研究大部分还是在琢磨怎么提升性能,获得经济效益;而国外的研究者做的工作就显得更various一点,并且许多researcher都很善于提问题,他们会去探讨数据和模型中可能存在的社会偏见,尝试揭示模型何时容易fail:
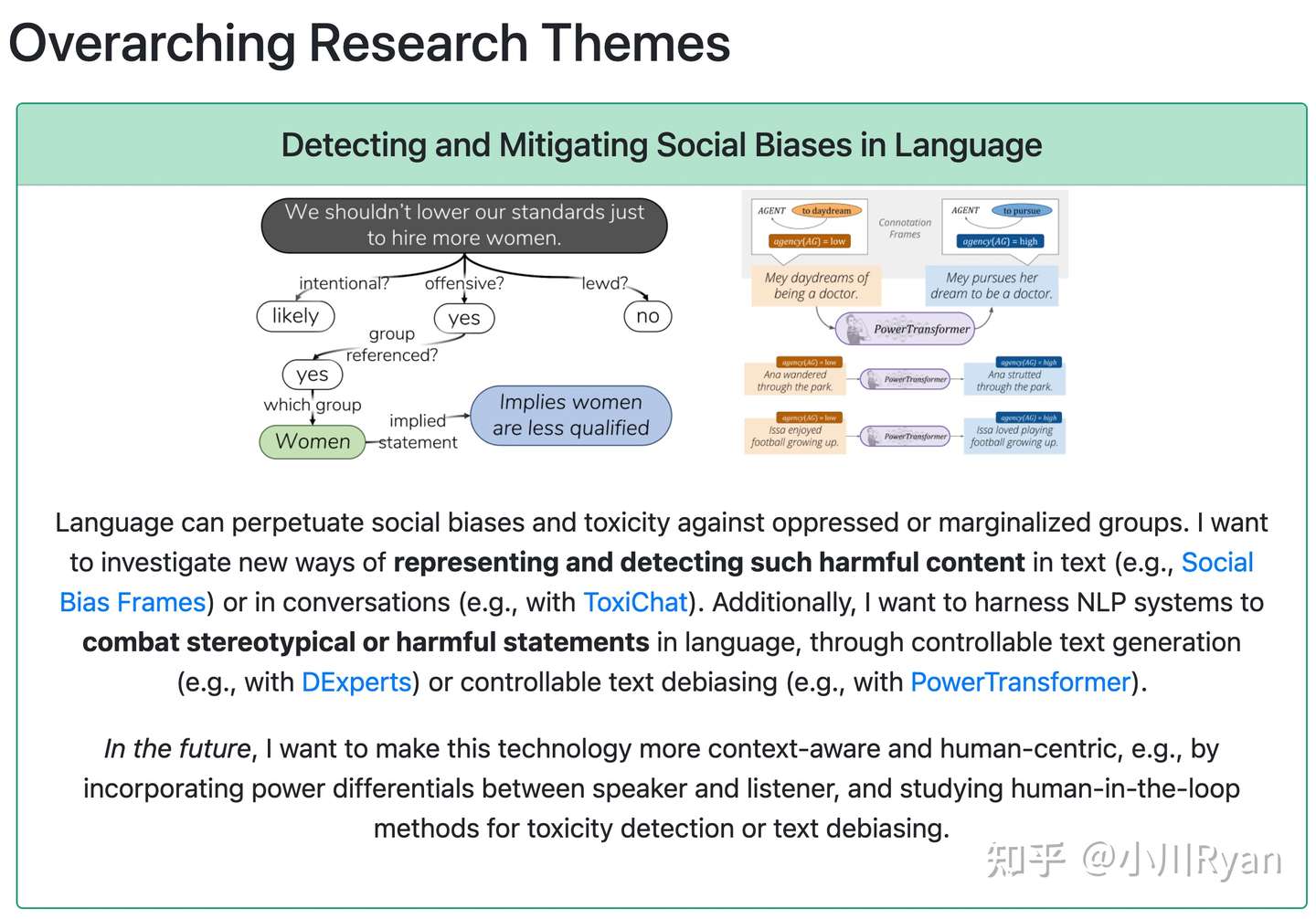
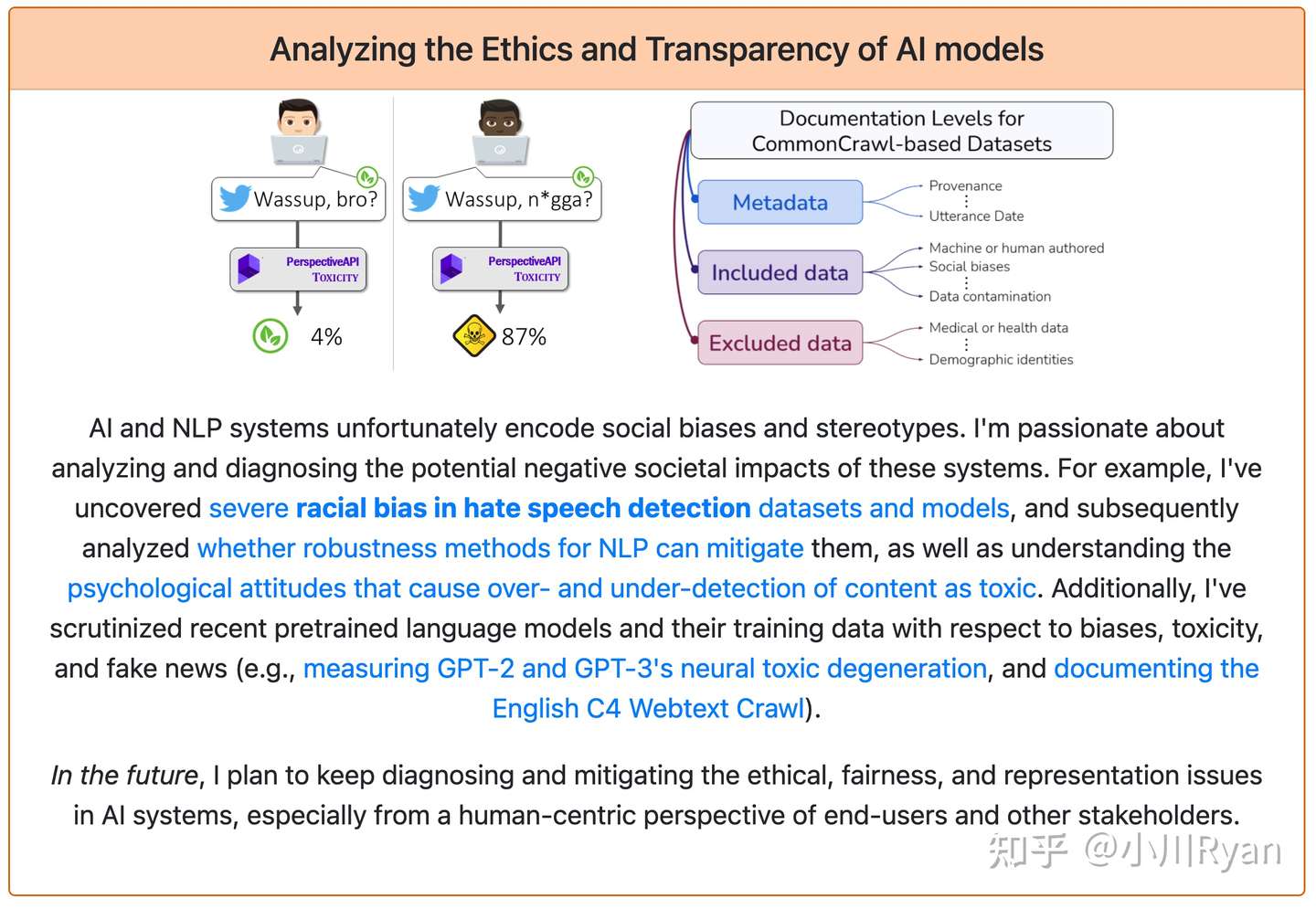
甚至专门去研究标注者的行为:

而这样的工作大多数周期可能都比较长,有些甚至非常handcrafted,可以说是“吃力不讨好”,但角度总是非常清奇,给人带来冲击感;然而即便是这样的工作他们甚至会投一部分到短文或者workshop上去,换到国内就是我的导师已经三天没打我了(当然这个涉及到评价体系差异)。
当然也并不是说国内没有这样的工作,我们也能看到国内的研究者们做出越来越多的有启发性的工作,但比例依然小很多。
黑盒荫蔽下的伪研究
深度模型的不可解释性始终是个notorious的问题,毕竟影响实验结果的要素实在是太多了(机器设备、数据划分、训练trick、随机种子...),总会有主观客观的因素使得不少论文的实验并没有完全控制变量,因而许多旨在提升性能的工作或许作者自己都没弄明白为什么会有提升,而论文里的几个picked cherries并不足以证明提升主要来自于最初的motivation。
甚至于不少novelty本身已经非常有限的工作,错误率降低(tips.我说的不是准确率提升)得微乎其微也声称是取得了considerable improvement
此处引用 AI software clears high hurdles on IQ tests but still makes dumb mistakes. Can better benchmarks help?中的一段访谈:
The pursuit of high scores can lead to the AI equivalent of doping. Researchers often tweak and juice the models with special software settings or hardware that can vary from run to run on the benchmark, resulting in model performances that aren’t reproducible in the real world. Worse, researchers tend to cherry-pick among similar benchmarks until they find one where their model comes out on top, Vanschoren says. “Every paper has a new method that outperforms all the other ones, which is theoretically impossible,” he says.
不过好在随着近几年会议的bar越来越高,这样的论文也越来越少了
什么样的研究才是好研究
这是个没法儿下定义的问题,但不同的时代背景下好的工作或多或少都有一些共性可循
大模型
大模型的上限在哪儿还没有能够完全揭示,而几乎每次有新的大模型release的时候,尤其是当表明实验用了多少机器资源时,都会有人站出来评论说这是靠钞能力在灌水,简洁的模型设计和预训练任务给了大家一种“我上我也行“的错觉,但事实上,乘以大模型想要解决的问题的规模和它本身要投入的工作量,大部分的研究都是好的研究,当然也包括一系列的为了更快更好的轻量化的工作、统一不同任务的、模态的、场景的工作。
关注benchmark的工作
人们争论了很多年 先有鸡还是先有蛋,但先有challenging的benchmark才能揭示更多问题、设计出更强的模型几乎不需要争论;一批批的benchmark推动着领域的进步,然后落下历史帷幕
每一段平台期都需要提出一些现在看上去非常困难,但几年后会被解决得比较好的任务,如今也是同样的道理。
除了关注任务本身,评价指标的多样性也非常值得重视,不同的应用场景大家的需求不同,全面的评价指标不仅能防止研究者的过拟合,也能对各类模型的表现有一个更全面的认识
提到这儿就想起来有一个对应的比较有意思的研究:
HuggingFace提出来的Dynabench: https://dynabench.org/#contributed-tasks,不停地会有标注者向其中的每个任务增加一些其认为模型容易弄错的样本,同时会从准确率、内存耗用、公平性、鲁棒性等多个维度来评价一个模型
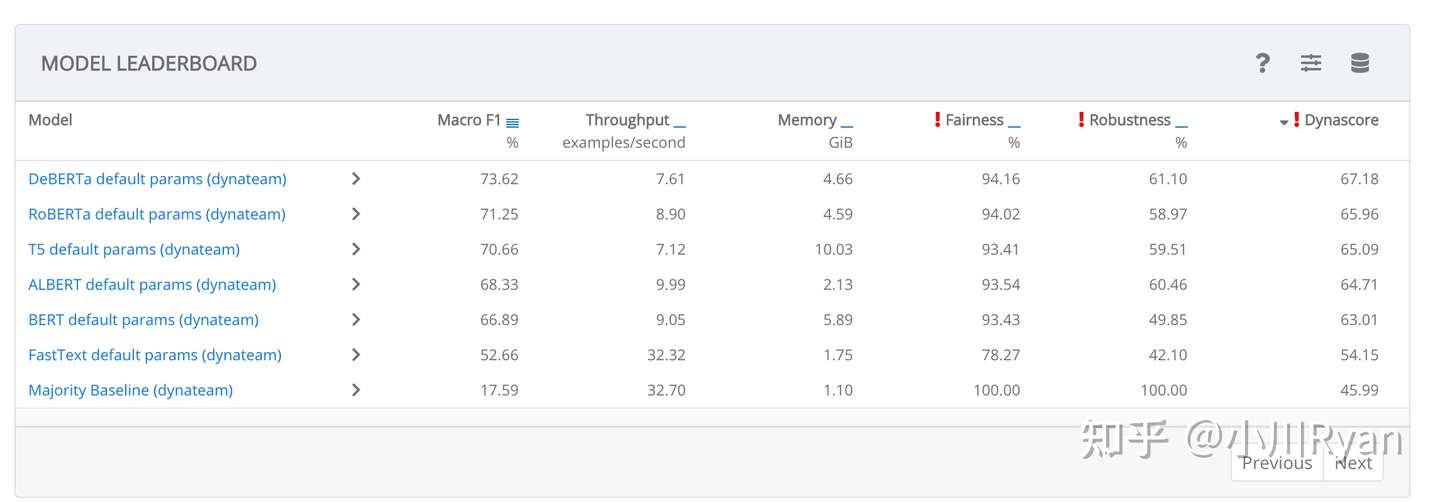
但不知道是否是因为提出一个benchmark没有提出一个炫酷的模型成就感那么大,大家对于benchmark的关注度还是要远小于对于模型方法的关注度
怎样获得性能提升
在有了benchmark的基础上,一个任务在初期的时候解决方法可能是百花齐放的,不久就会有研究者提出一种好的归纳偏置、得到大家的认可之后成为这个任务的经典模型,例如统治序列标注任务许久的BiLSTM + CRF,阅读理解任务中的BiDAF,以及屡试不爽的预训练任务MLM。
然而得益于大模型强大的表征能力,许多任务所需要的归纳偏置也呈现出简单化的趋势:上述的BiLSTM + CRF和BiDAF效果都不如BERT + MLP了。但正是由于这些知识的可证伪性,使得他们本身属于真正好的研究工作。因为如果有哪种方法能一直占据某个任务几十年,那很大概率只能说明这个领域的研究活力不够,或者这个任务本身难度过于大了。
不过总会有一些新提出的任务和比较难的任务还有没有非常好的归纳偏置,例如许多涉及超长文本的任务,这些也都是研究机会。
“挤水“的研究
对于许多难度较小的benchmark,模型短期内取得的大幅度提升很有可能是含有水分的,因此很多领域都有不少工作去尝试揭露模型通过哪些浅显的bias或者shortcut来取得分数上的提升、而不是进行真正的推理,进而对现有的benchmark或者方法进行改造,这些工作无疑也都是很好的研究。
当然也有一些工作试图减少上面提到的黑盒带来的弊端,例如OpenML套件: OpenML Benchmarking Suites,提出将多个benchmark和数据处理、效果评估等流程绑定起来,防止有人刻意进行过拟合。
除此之外还有很多热衷开源实验框架的小组,例如清华NLP组 提出的OpenXXX系列工具包,本意可能是为了研究社区更方便地进行实验,但实际上大家使用这些工具包的同时也统一了很多实验设置,因此也一定程度地起到了这样的作用。
For Social Good的研究
这类研究也是我们国内的研究者关注得比较少的方向,例如数据中可能存在的社会偏见、模型训练和推理带来的能耗问题,隐私保护问题、医学信息处理、生物信息等等。关注度低的主要原因大概也是研究这些方向并不能带来直接的经济效益(当然降低模型能耗节约下来的电费也是不可小觑的),但从长远来看是很有可能产生可观的社会效益的。
道阻且长,共勉
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢