
作者:Jack FitzGerald, Shankar Ananthakrishnan, Konstantine Arkoudas,等
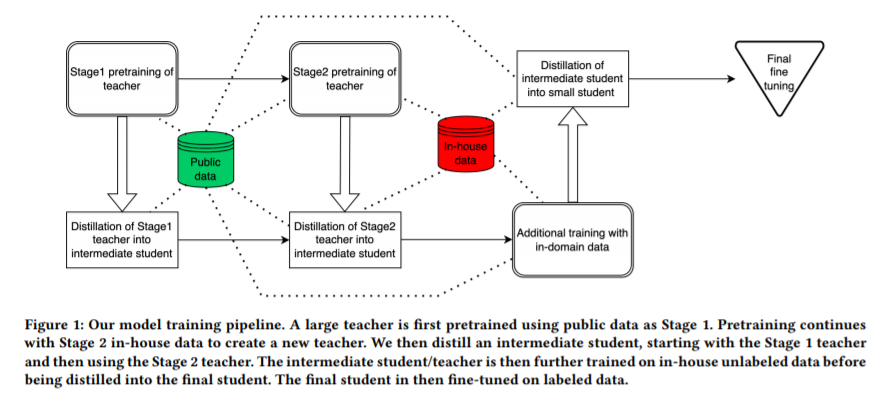
简介:本文主要展示大规模的预训练编码器实验的结果。在实验中作者的该编码器非嵌入参数计数范围从 700M 到 9.3B,随后将其提炼成参数范围从 17M-170M 的较小模型, 并将其应用于虚拟辅助系统的自然语言理解(NLU)组件。虽然作者使用70%的口语形式数据进行训练,但当在书面形式跨语言自然语言推理(XNLI)语料库上进行评估时,作者的教师模型的表现与XLM-R和mT5相当。作者使用系统中的域内数据对作者的教师模型进行第二阶段的预训练,相对于意图分类错误率提高了3.86%,相对于插槽填充错误率提高了7.01%。作者发现,与仅接受公共数据训练的2.3B参数的教师模型(第1阶段)相比,即使是从作者的第2阶段教师模型中提取的170M参数模型,其意图分类也有2.88%的改进,插槽填充错误率也有7.69%的改进,强调了域内数据对于预训练的重要性。当使用标记的NLU数据进行离线评估时,作者的17M参数二级蒸馏模型的性能分别比XLM-R Base(85M参数)和蒸馏Bert(42M参数)好4.23%-6.14%。最后,本文展示了一个全虚拟辅助实验平台的结果,实验发现使用作者的预训练和蒸馏管道训练的模型:在全系统用户不满的自动测量方面比从85M参数教师蒸馏模型的性能好3.74%~4.91%。
论文下载:https://arxiv.org/pdf/2206.07808
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢