标题:谷歌等|BEYOND THE IMITATION GAME: QUANTIFYING AND EXTRAPOLATING THE CAPABILITIES OF LANGUAGE MODELS(超越模仿游戏:量化和推断语言模型的能力)
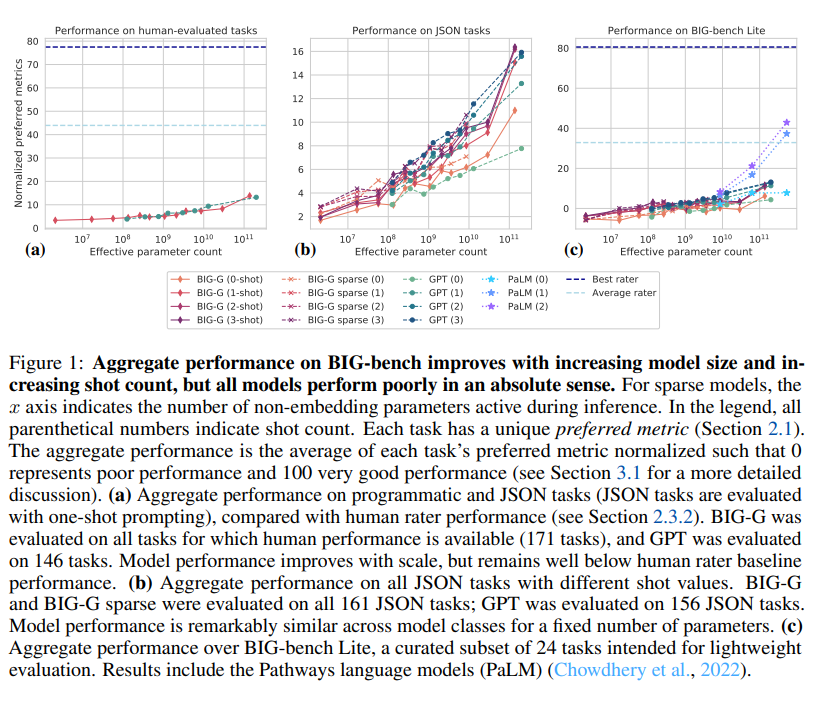
简介:随着规模的不断增强,语言模型既展示了定量改进,也展示了定性改进能力。作者引入了超越模仿游戏基准测试(BIG-bench),由204个任务组成,主题包括绘图问题、语言学,儿童发展,数学,常识推理,生物学,物理,社会偏见,软件开发等。BIG-bench专注于超出当前语言模型能力的任务。作者评估OpenAI的GPT模型的行为,谷歌内部密集变换器架构,以及BIG-bench上的开关式稀疏变换器,跨越数百万到数千亿个参数的模型尺寸。调查结果包括:模型性能和准确率都随着规模的提高而改善,但绝对值较差(与评分员的表现相比);性能在模型类之间非常相似,尽管具有稀疏性的好处;逐步和可预测的任务通常涉及大量知识或记忆组件,而在关键规模通常涉及多个步骤或组件,或脆性指标;在上下文不明确的设置中,社会偏见通常会随着模型规模的增加而增加,但这可能会通过提示调整进行改进。
论文下载:https://arxiv.org/pdf/2206.04615v1.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢