
Google、斯坦福大学、北卡教堂山分校、DeepMind合作的论文“ Emergent Abilities of Large Language Models”。作者中除了Jeff Dean外,还有DeepMind的Oriol Vinyals(论文引用15万+)和斯坦福的Percy Liang这样的大神。值得一提的是,排在第一的作者Jason Wei是2020年达特茅斯本科毕业就加入Google Brain的年青人。
摘要
提升语言模型的规模,已被证明可以在广泛的下游任务中以可预测的方式提高性能和样本效率。本文则讨论了一种不可预测的现象,我们称之为大型语言模型的涌现能力。如果它不存在于较小的模型中但存在于较大的模型中,我们认为这种能力是涌现的。 因此,不能简单地通过推断较小模型的性能来预测涌现能力。 存在这种涌现意味着更大的规模可以进一步扩大语言模型的能力范围。
这项研究的背景是,虽然按照所谓“规模定律”(Scaling law),随着模型变大,解决很多任务的性能都能可预测地提升,但是仍然有一些任务不是这样(参见Anthropic的论文)。
论文中将涌现(emergence)这一概念追溯到诺贝尔物理奖得主Philip Anderson(2020年以96岁高龄去世)1972年的论文“More Is Different” :
Emergence is when quantitative changes in a system result in qualitative changes in behavior.
(涌现是指系统的量变导致行为的质变。)
值得注意的是,很多涌现相关的文献(比如Holland的同名书)更强调系统变化时“整体大于部分之和”这一方面。
文章重点考察了小样本提示任务中各种模型的涌现能力。
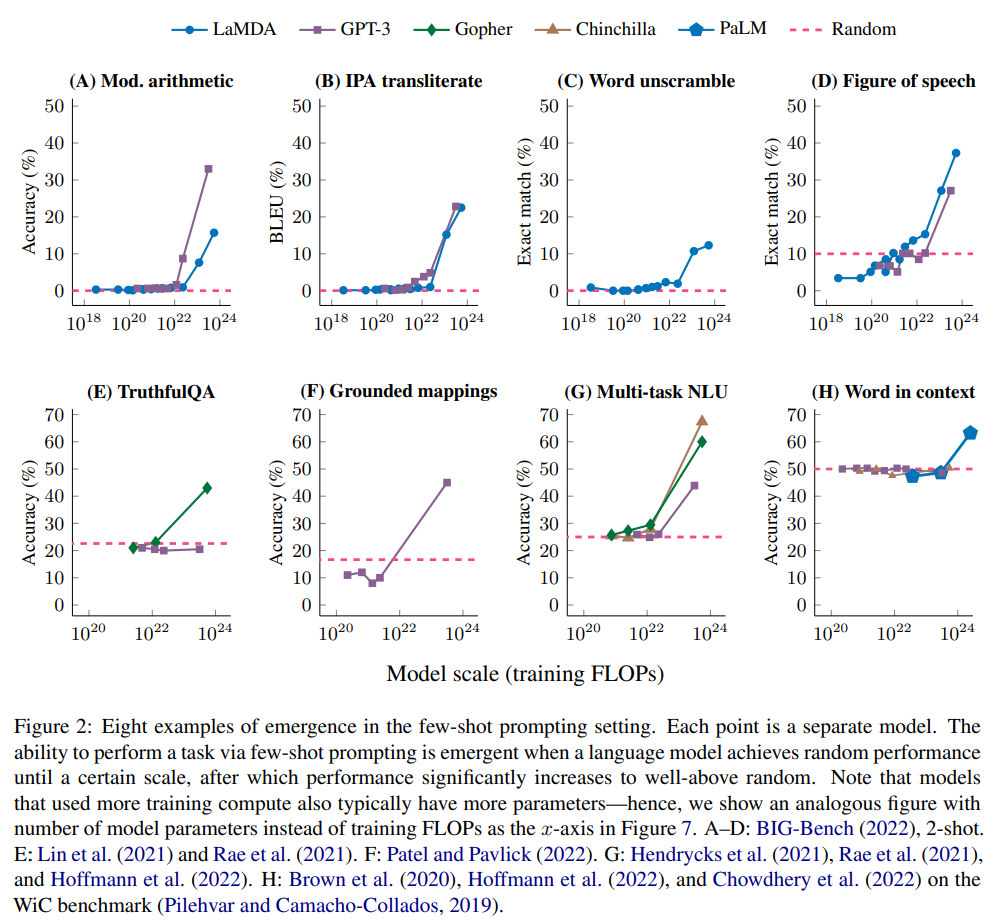
然后讨论了其他增强提示策略,包括多步推理(Multi-step reasoning)、指令微调和程序执行等,存在模型规模不够大就无效或者有害的现象。
论文最后的结论部分说:
这些能力是语言大模型最近发现的结果,它们如何涌现以及更大规模是否能够促使更多涌现能力,将是 NLP 领域未来的重要研究方向。
另外可以参考机器之心的文章: https://mp.weixin.qq.com/s/lNbACINCpRi0F6-NS2ZcmQ
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢