


论文链接:https://arxiv.org/abs/2204.07683
代码链接:https://github.com/tsun/SSRT
导读
在本文中,作者提出了一种新的UDA解决方案SSRT (Safe Self-Refinement for Transformer-based domain adaptation)。该方案从两个方面提升域适应性能。首先,作者为SSRT配备了transformer骨干网络。作者发现transformer与简单对抗域适应方法的结合在DomainNet数据集的基准测试中有很好的表现,甚至超过了基于卷积神经网络目前最好的结果,展现出transformer优异的可迁移特征表征能力。其次,为了降低模型崩溃的风险,提高大间隔领域间知识迁移的有效性,作者提出了一种安全的训练机制。具体来说,SSRT利用对目标域数据添加扰动来改进模型参数。由于transformer的模型容量较大,且此类任务预测结果可能有很多噪声,作者设计了一种安全训练机制,以自适应地调整学习参数。作者在几个常用的UDA 基准数据集上评估了SSRT性能,取得了Office-Home上85.43%,VisDA上88.76%和DomainNet上45.2%预测准确率的最好表现。
贡献
无监督域适应 (Unsupervised Domain Adaptation, UDA) 是指利用信息丰富的源域样本来提升目标域模型性能的一种范式,通常与预训练的卷积神经网络一起应用于视觉任务中。在中等规模的分类基准数据集上,例如Office-Home和VisDA,目前UDA方法能取得较好的预测精度;然而在像DomainNet这样的大型数据集上往往表现欠佳,最佳平均准确率仅为33.3% [1]。 基于以上观察,作者将研究重点放在两个方面:
首先,从特征表示方面,作者尝试将vision transformer [2] 集成到UDA中。Vision transformer成功地应用在很多视觉任务中,但其在UDA中的应用研究还很欠缺。作者发现,将ViT-B/16 [2] 与简单对抗域适应(adversarial DA)方法相结合,在DomainNet上可以达到38.5%的平均准确率,优于目前基于ResNet-101 [3] 的最好结果。这表明vision transformer的特征表示具有优异的分辨力和跨域可迁移性。
其次,从域适应方面,需要一个更可靠的模型更新策略来保护学习过程不因较大的域间隔而崩溃。由于vision transformer大模型容量增加了对源域数据过拟合的可能性,因此需要利用目标域数据进行模型正则化。在UDA中,常见的做法是利用目标域数据模型预测结果进行自我训练或强化聚类结构。但当域间隔很大时,其监督信息中可能有很多噪声。因此,需要一种安全的训练机制以避免模型崩溃。
基于上述讨论,在本文中,作者提出了一种新的UDA解决方案SSRT (Safe Self-Refinement for Transformer-based domain adaptation)。SSRT以vision transformer作为网络骨干,利用对目标域数据添加扰动来改进模型参数。具体地说,作者在目标域数据的隐层token序列中加入一个随机偏移,并最小化模型在原始数据和扰动后数据上预测类别概率的KL散度,相当于对相应的隐层施加了一个正则化。此外,由于UDA任务之间差异很大,即使源自同一个数据集,对于大多数任务有效的学习配置 (例如,超参数) 在某些特定任务上也可能会失败。因此,作者在目标域数据上使用模型预测结果的多样性指标来检测模型崩溃。一旦发生崩溃,模型就会恢复到以前存档的状态,并自动调整学习配置。通过这个安全的训练机制, SSRT避免了在域间隔较大的任务上出现显著的性能下降。
方法
2.1 方法框架
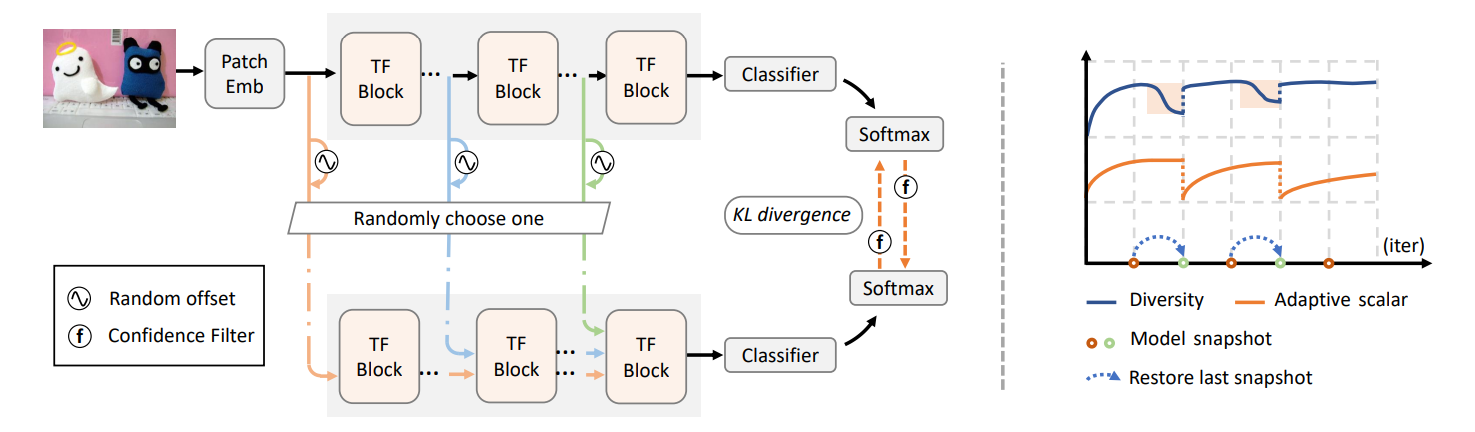
图1. SSRT框架
图1介绍了作者提出的SSRT框架。如图所示,该网络由vision transformer骨干网络和分类器组成。Patch Embedding将每个目标域图像转换为一个token序列,其中包括一个特殊的类别token和图像token。紧接着,该序列通过一系列transformer block进行变换。最后分类器接收类别token并输出预测类别标签。作者随机选择一个transformer block,并在其输入token序列上添加一个随机偏移,利用原始数据和扰动后数据对应的预测概率分布差异更新模型。
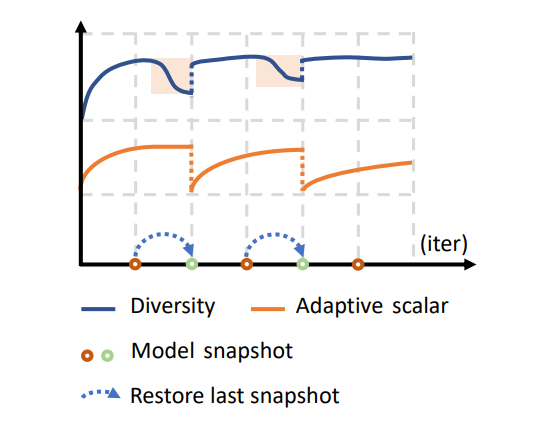
图2. 安全的训练机制
图2展示了安全训练机制具体流程:基于当前的模型预测结果多样性指标自适应地调整学习参数。
2.2. transformer的多层扰动
实验发现,对相对靠近分类器的层施加扰动训练效果更好,但模型崩溃的风险也更高。因此,作者从多个层中随机选择一个进行扰动,这相比只扰动某一层更鲁棒。给定目标域图像 xx ,设 b^l_xbxl 为其第 ll 个transformer block的输入token序列,则 b^l_xbxl 可以看作是该图像在一个隐空间中的特征表示。由于其维度较高,且目标域数据在特征空间中分布有限,因此对其施加任意方向的扰动是低效的。作者利用另一个随机选择的目标域图像的token序列构造偏移量,扰动之后的特征表示为:
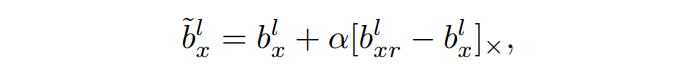
其中α 是标量,[⋅]× 表示梯度不反向传播。
2.3 双向的模型自我更新
令 px 和 p~x 分别表示原始数据和扰动后数据的模型预测概率向量,则损失函数为
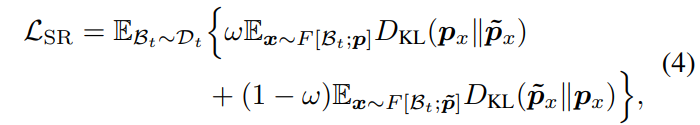
其中 ω 服从伯努利分布B(0.5),F 基于预测概率置信度筛选样本,定义为:
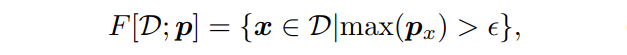
LSR 使用置信样本的预测结果更新模型,并约束模型在隐空间中的预测值具有光滑性。值得说明的是,在作者的框架中,梯度同时反向传播到KL散度的两个输入概率。
2.4 基于自适应调整的安全训练机制
当模型发生崩溃时,模型预测结果的多样性也会下降。作者通过检测训练过程中此事件的发生,自适应地调整学习参数。具体地,作者将训练过程划分为以T轮为周期的很多个连续区间,并在每个区间结束时候保存模型状态。算法中的扰动大小和损失函数权重通过一个系数 rr 调节,定义为
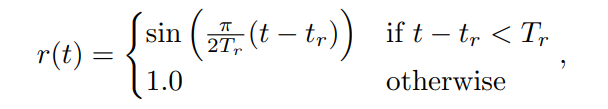
rr 在一个 T_rTr 周期内从0逐渐增长到1。在每个区间结束时,安全机制会检测该区间内有没有多样性下降事件发生。如果有,则重置 rr 并将模型恢复到上一个保存的状态。那么如何检测多样性下降呢?对于某一轮中的一批目标域样本,作者将模型预测的不重复类别数作为该轮多样性的衡量标准。进一步地,作者将区间分割为不同尺度的子区间,并检查相邻子区间平均多样性值是否有显著下降。详细步骤列在算法1和算法 2中。其中div定义为
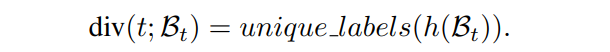


简单来说,安全训练机制的目的就是在面对不同任务时,可以根据任务难度和当前模型训练状态自适应调节学习设置。从图3可以看出,对于qdr→clp,使用或未使用该机制性能相当,而对于clp→qdr,使用安全训练机制则可有效地避免了模型崩溃。
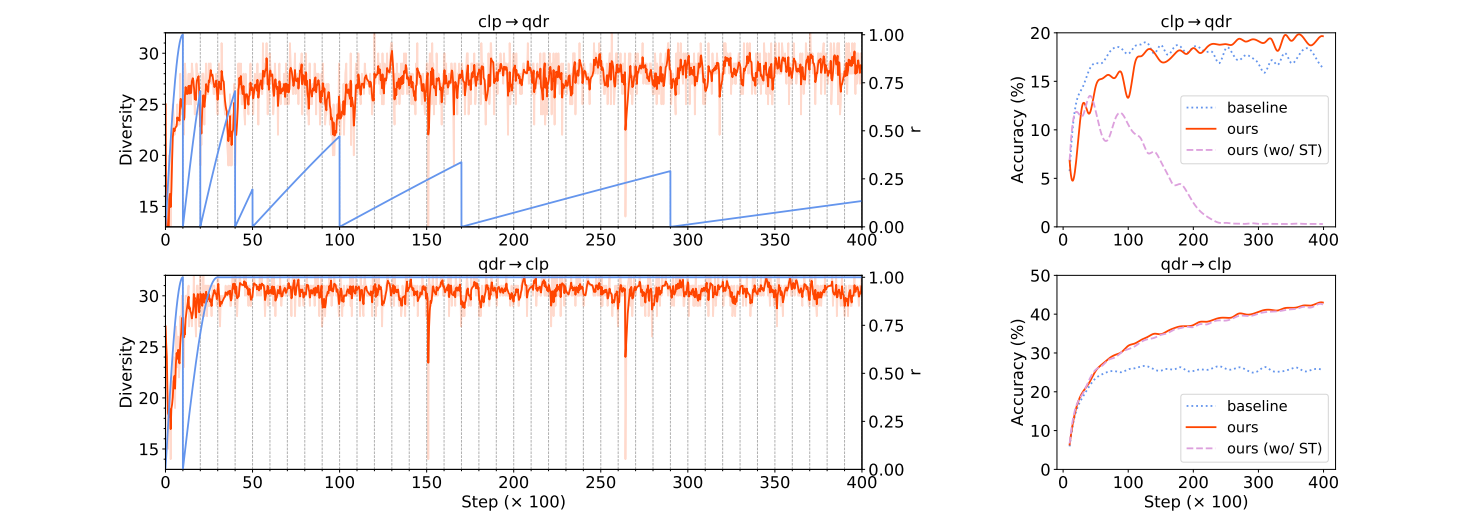
图3. 安全训练机制对训练过程及测试集准确率的影响
实验
3.1 在标准数据集上的表现
作者在四个标准的域适应数据集上评估方法性能,包括Office-31,VisDA-2017,DomainNet,和Office-Home。表1列出了DomainNet上不同方法的测试集准确率。总的来说,基于transformer的结果要比基于ResNet的结果好得多,验证了transformer特征的可迁移能力。SSRT取得了45.2%的最好结果,证明了其有效性。更多数据集的实验结果可以参阅原文。
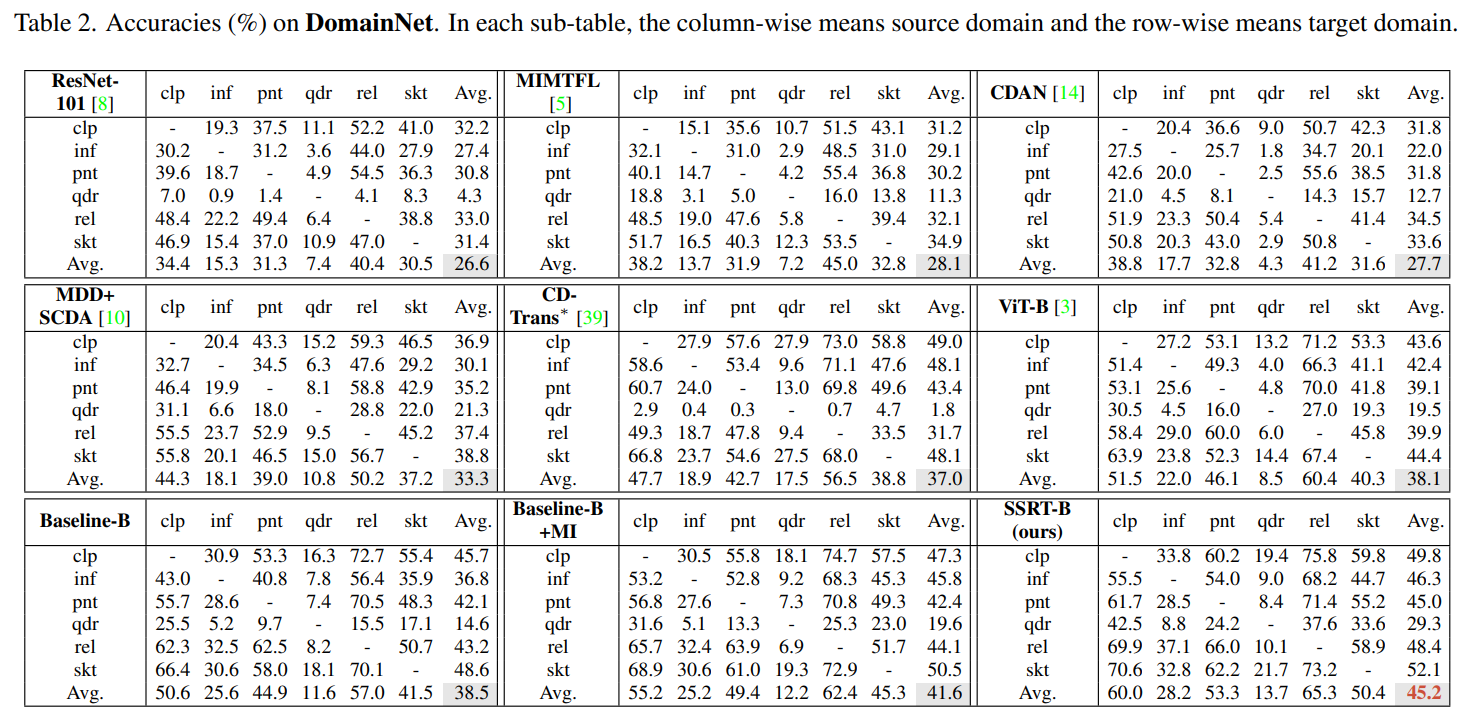
DomainNet上不同方法的测试集准确率
3.2 多层扰动的效果
图4比较了在不使用安全训练机制的情况下,对不同单层施加相同大小扰动训练得到的模型性能。可以看到,最佳层次因任务而异。在一项任务表现好的层,在另一项任务上却可能失效。作者从 {0,4,8} 层中随机选择一层进行扰动,相比而言,只扰动其中一层在DomainNet上训练得到的模型测试集准确率分别下降了1.0%, 1.5% 和1.5%。

图4. 只在不同单层施加相同大小扰动的对比结果
3.3 模型鲁棒性分析
图5展示了通过扰动训练对模型测试阶段鲁棒性的影响。虚线表示模型在目标域测试数据上的真实准确率,柱状线条表示在测试数据不同层施加扰动后模型预测结果准确率的下降程度。 可以看出SSRT相比基准方法具有更强的鲁棒性。即使施加比训练阶段见到的更大的扰动(\alpha=0.4α=0.4),模型预测结果仍然相对准确。
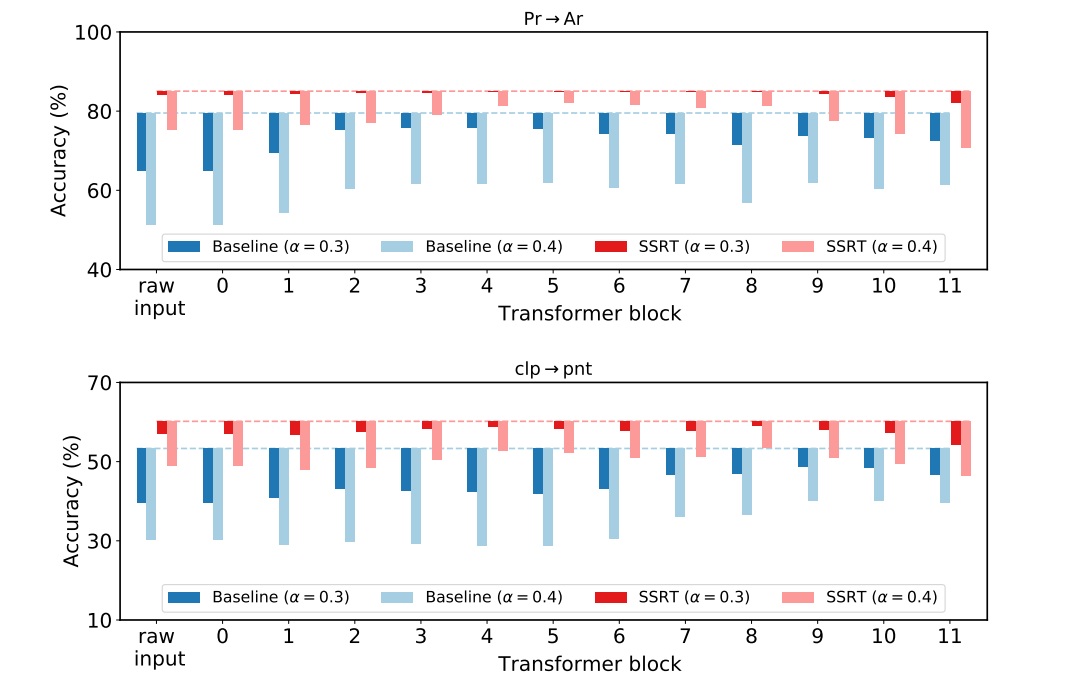
图5. 测试阶段模型鲁棒性分析
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢