
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:现实世界视频的端到端以物体为中心学习探索、完全可控神经3D人像、人为线索的极限视角几何、面向参数及内存高效迁移学习的梯侧微调、强化学习的大规模检索、Python统一生成式自编码器库、视频预测和填充的扩散模型、从经过训练的神经网络重建训练数据、掩码Siamese卷积网络
1、[CV] SAVi++: Towards End-to-End Object-Centric Learning from Real-World Videos
G F. Elsayed, A Mahendran, S v Steenkiste, K Greff, M C. Mozer, T Kipf
[Google Research]
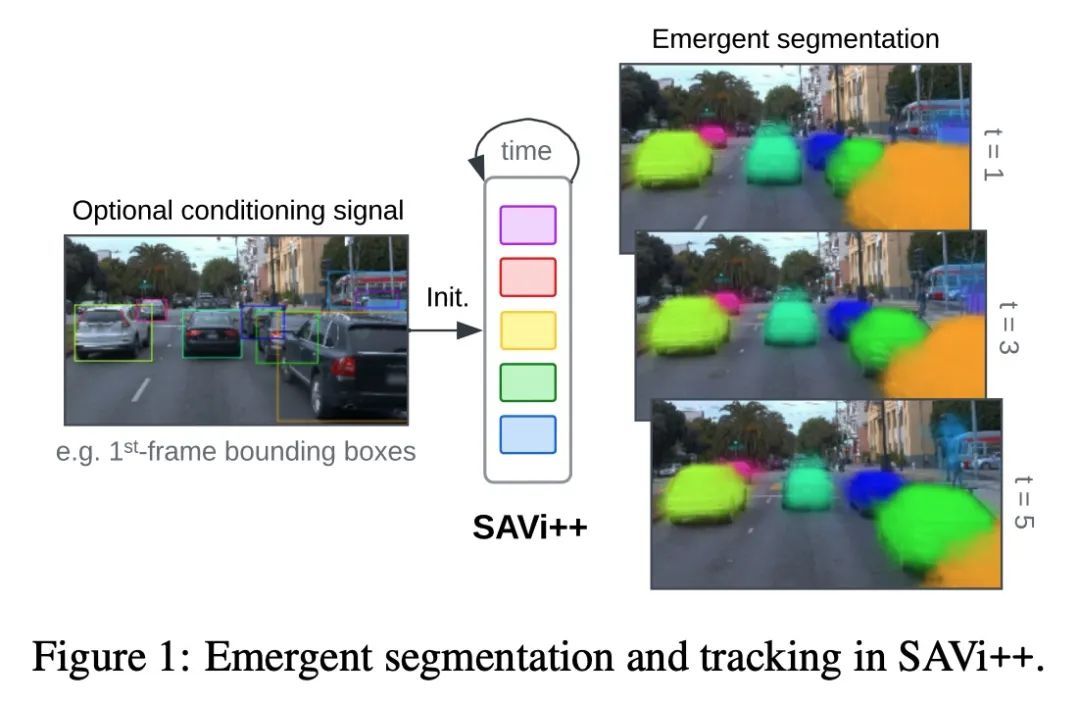
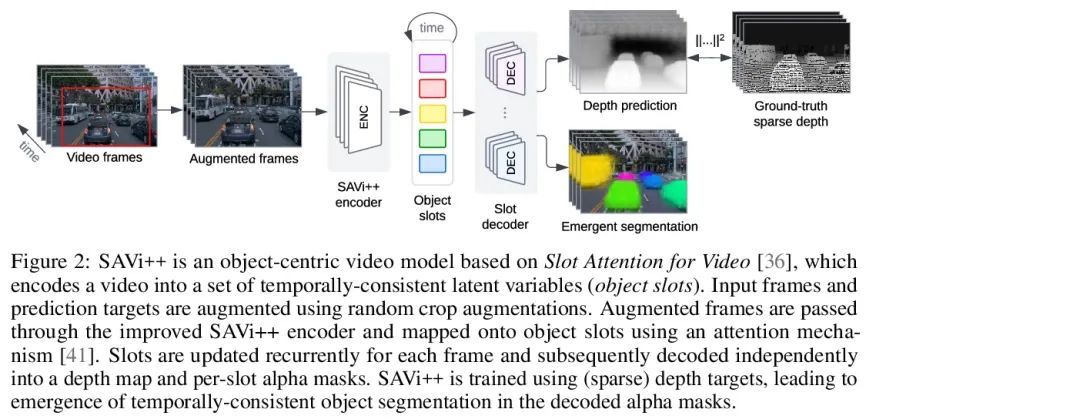
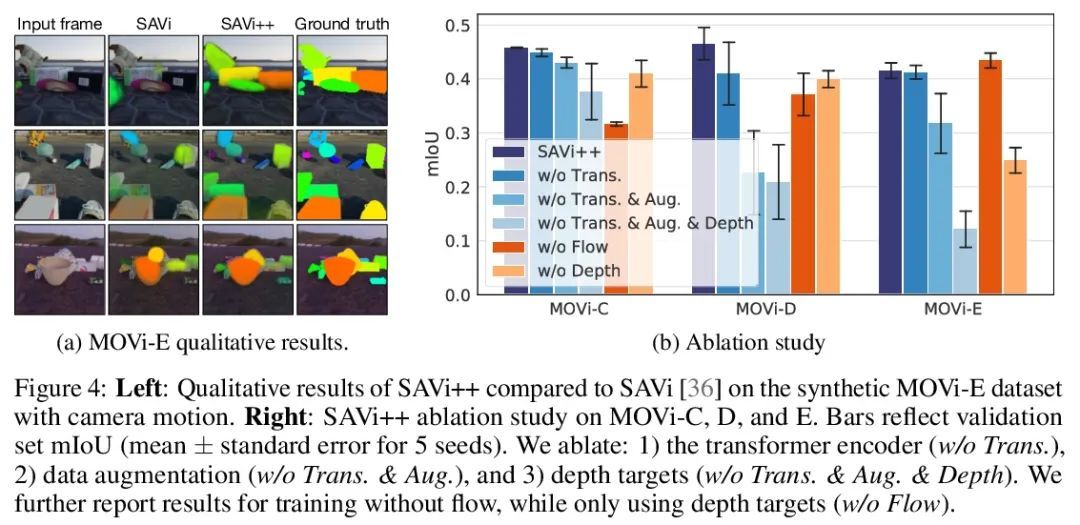
SAVi++: 现实世界视频的端到端以物体为中心学习探索。视觉世界可以用不同的实体和稀疏的相互作用来解析特征。事实证明,除非提供明确的实例级监督,否则在动态视觉场景中发现这种组成结构对端到端计算机视觉方法是具有挑战性的。最近,基于槽的模型利用运动线索在学习表示、分割和跟踪物体方面显示出巨大的前景,但它们仍然无法扩展到复杂的现实世界多物体视频。为了弥补这一差距,本文从人类发展中获得灵感,并假设深度信号形式的场景几何信息可以促进以物体为中心的学习。本文提出SAVi++,一种以物体为中心的视频模型,它被训练成从基于槽的视频表示中预测深度信号。通过进一步利用模型扩展的最佳实践,训练SAVi++来分割用移动摄像机记录的复杂动态场景,其中包含自然背景上不同外观的静态和移动物体,而不需要分割监督。实验证明,通过使用从LiDAR获得的稀疏深度信号,SAVi++能从现实世界的Waymo Open数据集中的视频中学习涌现的物体分割和跟踪。
The visual world can be parsimoniously characterized in terms of distinct entities with sparse interactions. Discovering this compositional structure in dynamic visual scenes has proven challenging for end-to-end computer vision approaches unless explicit instance-level supervision is provided. Slot-based models leveraging motion cues have recently shown great promise in learning to represent, segment, and track objects without direct supervision, but they still fail to scale to complex real-world multi-object videos. In an effort to bridge this gap, we take inspiration from human development and hypothesize that information about scene geometry in the form of depth signals can facilitate object-centric learning. We introduce SAVi++, an object-centric video model which is trained to predict depth signals from a slot-based video representation. By further leveraging best practices for model scaling, we are able to train SAVi++ to segment complex dynamic scenes recorded with moving cameras, containing both static and moving objects of diverse appearance on naturalistic backgrounds, without the need for segmentation supervision. Finally, we demonstrate that by using sparse depth signals obtained from LiDAR, SAVi++ is able to learn emergent object segmentation and tracking from videos in the real-world Waymo Open dataset. Project page: https://slot-attention-video.github.io/savi++/
https://arxiv.org/abs/2206.07764


2、[CV] RigNeRF: Fully Controllable Neural 3D Portraits
S Athar, Z Xu, K Sunkavalli, E Shechtman, Z Shu
[Stony Brook University & Adobe Research]
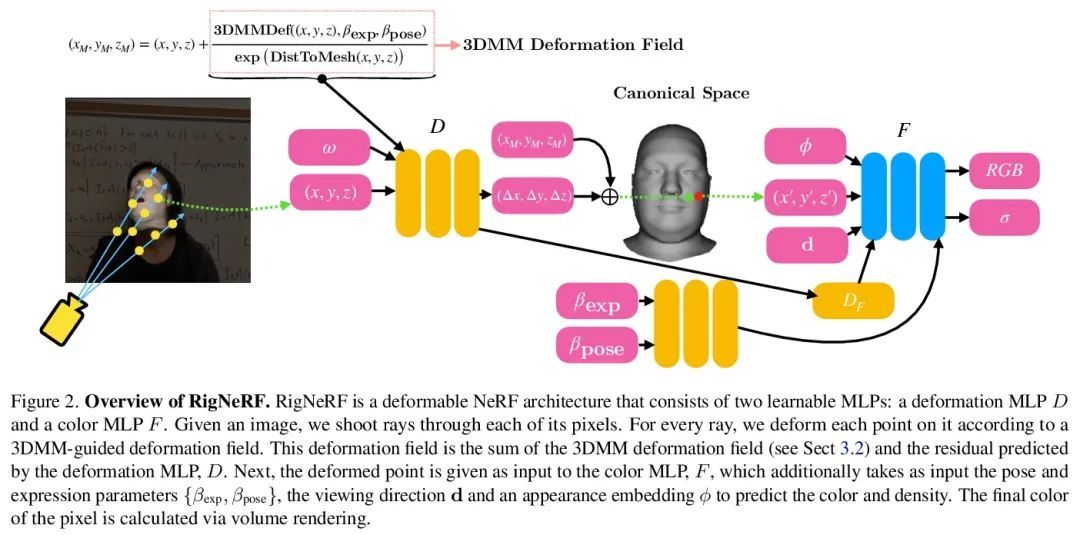
RigNeRF:完全可控神经3D人像。体神经渲染方法,如神经辐射场(NeRF),已经实现了照片级真实的新视图合成。然而,标准形式的NeRF不支持在场景中编辑物体,如人的头部。本文提出RigNeRF,一种超越了新视角合成的系统,能完全控制从单个人像视频中学习的头部姿态和面部表情。用一个由3D可变形脸部模型(3DMM)引导的变形场来模拟头部姿势和人脸表情的变化。3DMM有效充当了RigNeRF的先验,学会了只预测3DMM变形的残差,并允许渲染输入序列中不存在的新(刚性)姿态和(非刚性)表情。仅用智能手机拍摄的主体短视频进行训练,证明了该方法在具有明确头部姿态和表情控制的人像场景的自由视图合成中的有效性。
Volumetric neural rendering methods, such as neural radiance fields (NeRFs), have enabled photo-realistic novel view synthesis. However, in their standard form, NeRFs do not support the editing of objects, such as a human head, within a scene. In this work, we propose RigNeRF, a system that goes beyond just novel view synthesis and enables full control of head pose and facial expressions learned from a single portrait video. We model changes in head pose and facial expressions using a deformation field that is guided by a 3D morphable face model (3DMM). The 3DMM effectively acts as a prior for RigNeRF that learns to predict only residuals to the 3DMM deformations and allows us to render novel (rigid) poses and (non-rigid) expressions that were not present in the input sequence. Using only a smartphone-captured short video of a subject for training, we demonstrate the effectiveness of our method on free view synthesis of a portrait scene with explicit head pose and expression controls. The project page can be found here.
https://arxiv.org/abs/2206.06481




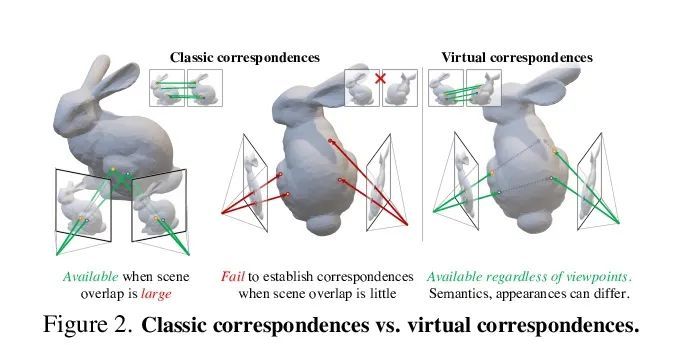
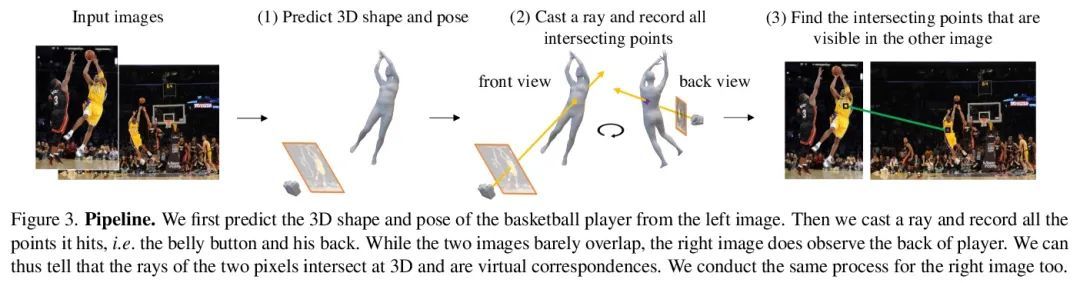
3、[CV] Virtual Correspondence: Humans as a Cue for Extreme-View Geometry
W Ma, A J Yang, S Wang, R Urtasun, A Torralba
[MIT & University of TorontoUniversity of Illinois & Urbana-Champaign]
虚拟对应:人为线索的极限视角几何。从极端视角的图像中恢复摄像机的空间布局和场景的几何形状是计算机视觉中的一个长期挑战。现行的3D重建算法通常采用图像匹配的范式,并假定场景的一部分在不同的图像中都是可见的,当输入之间几乎没有重叠时,就会产生糟糕的性能。相反,人类可以通过对形状的先验知识,将一个图像中的可见部分与另一个图像中的相应不可见部分联系起来。受到这一事实的启发,本文提出一种新概念——虚拟对应(VC)。VC是一对来自两幅图像的像素,它们的相机射线在3D中相交。与经典对应相似,VC符合表极几何学;与经典的对应不同,VC不需要在不同的视图中共同可见。因此,即使图像不重叠,也可以建立和利用VC。本文提出一种方法来寻找基于场景中人的虚拟对应关系。展示了VC如何与经典的绑定调整无缝集成,以恢复极端视图中的相机姿态。实验表明,所提出方法在具有挑战性的场景中明显优于最先进的摄像机姿态估计方法,并且在传统的密集捕捉设置中具有可比性。该方法还释放了多种下游任务的潜力,如多视角立体图像的场景重建和极端视角场景下的新视图合成。
Recovering the spatial layout of the cameras and the geometry of the scene from extreme-view images is a longstanding challenge in computer vision. Prevailing 3D reconstruction algorithms often adopt the image matching paradigm and presume that a portion of the scene is covisible across images, yielding poor performance when there is little overlap among inputs. In contrast, humans can associate visible parts in one image to the corresponding invisible components in another image via prior knowledge of the shapes. Inspired by this fact, we present a novel concept called virtual correspondences (VCs). VCs are a pair of pixels from two images whose camera rays intersect in 3D. Similar to classic correspondences, VCs conform with epipolar geometry; unlike classic correspondences, VCs do not need to be co-visible across views. Therefore VCs can be established and exploited even if images do not overlap. We introduce a method to find virtual correspondences based on humans in the scene. We showcase how VCs can be seamlessly integrated with classic bundle adjustment to recover camera poses across extreme views. Experiments show that our method significantly outperforms state-of-the-art camera pose estimation methods in challenging scenarios and is comparable in the traditional densely captured setup. Our approach also unleashes the potential of multiple downstream tasks such as scene reconstruction from multi-view stereo and novel view synthesis in extreme-view scenarios.
https://arxiv.org/abs/2206.08365



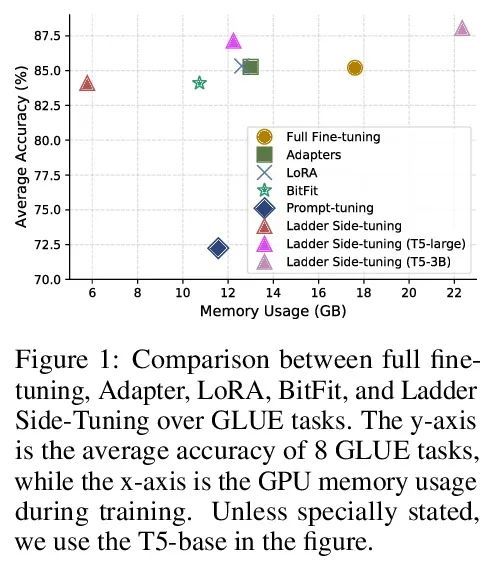
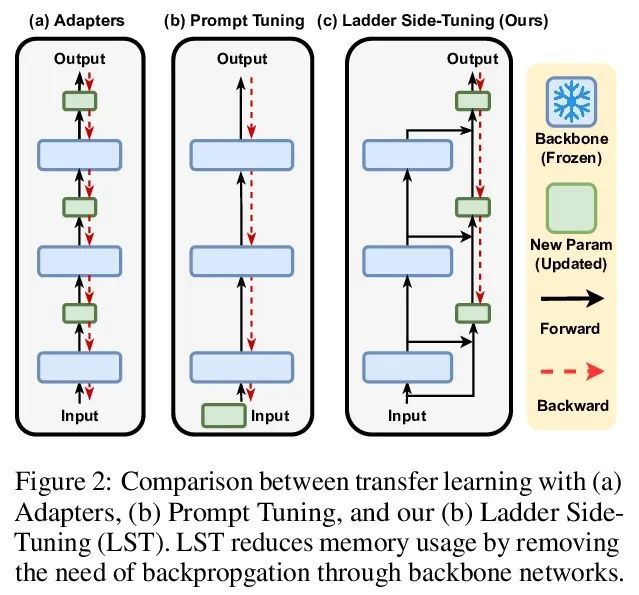
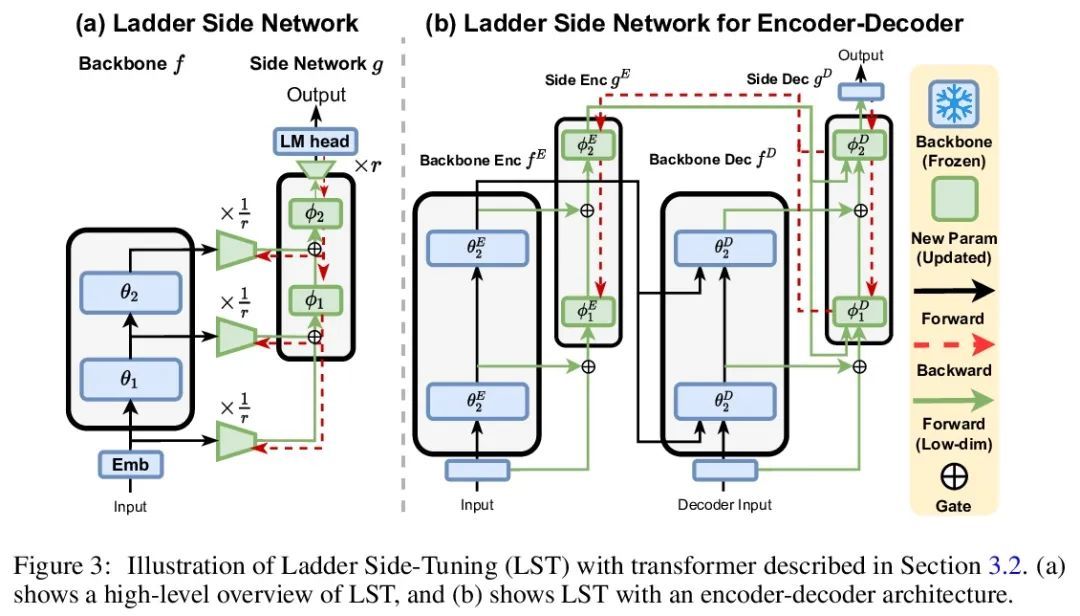
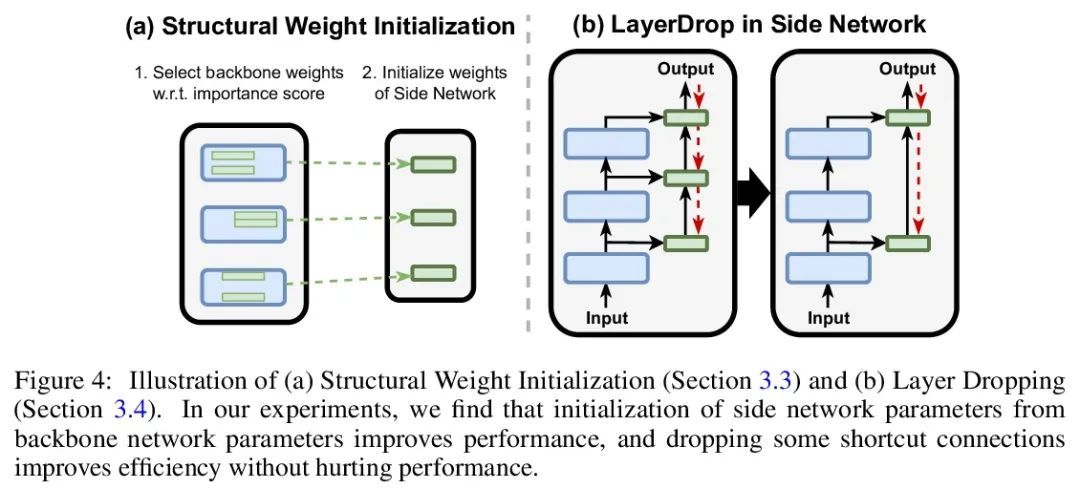
4、[CL] LST: Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning
Y Sung, J Cho, M Bansal
[UNC Chapel Hill]
LST:面向参数及内存高效迁移学习的梯侧微调。最近,在各种领域都采用了在下游任务上对大型预训练模型进行微调。然而,更新大型预训练模型的整个参数集的成本很高。尽管最近提出的参数高效迁移学习(PETL)技术允许在预训练的骨干网络中更新一小部分参数(例如只使用2%的参数)来完成一个新任务,但也只能减少30%的训练内存需求。这是因为可训练参数的梯度计算仍然需要通过大型预训练骨干模型进行反向传播。为解决这个问题,我们提出了梯侧微调(LST),一种新的PETL技术,可以将训练内存需求降低到更大的程度。与现有的在骨干网络内插入额外参数的参数高效方法不同,训练一个梯侧网络,一个小的独立网络,通过骨干网络的快捷连接(梯)将中间激活作为输入并进行预测。LST对内存的要求明显低于之前的方法,因为它不需要通过骨干网络进行反向传播,而只需要通过侧网络和梯进行连接。用各种模型(T5和CLIP-T5)在自然语言处理(GLUE)和视觉-语言(VQA、GQA、NLVR、MSCOCO)任务上评估了多提出的方法。LST节省了69%的内存成本来微调整个网络,而其他方法在类似的参数使用中只节省了26%(节省了2.7倍的内存)。此外,LST在低内存场景实现了比Adapter和LoRA更高的精度。为进一步显示这种更好的内存高效的优势,将LST应用于更大的T5模型(T5-large,T5-3B),获得了比全微调和其他PETL方法更好的GLUE性能。这一趋势在视觉和语言任务的实验中也是成立的,在训练类似数量的参数时,LST达到了与其他PETL方法相似的精度,同时还能节省2.7倍的内存。
Fine-tuning large pre-trained models on downstream tasks has been adopted in a variety of domains recently. However, it is costly to update the entire parameter set of large pre-trained models. Although recently proposed parameter-efficient transfer learning (PETL) techniques allow updating a small subset of parameters (e.g. only using 2% of parameters) inside a pre-trained backbone network for a new task, they only reduce the training memory requirement by up to 30%. This is because the gradient computation for the trainable parameters still requires backpropagation through the large pre-trained backbone model. To address this, we propose Ladder Side-Tuning (LST), a new PETL technique that can reduce training memory requirements by more substantial amounts. Unlike existing parameterefficient methods that insert additional parameters inside backbone networks, we train a ladder side network, a small and separate network that takes intermediate activations as input via shortcut connections (ladders) from backbone networks and makes predictions. LST has significantly lower memory requirements than previous methods, because it does not require backpropagation through the backbone network, but instead only through the side network and ladder connections. We evaluate our method with various models (T5 and CLIP-T5) on both natural language processing (GLUE) and vision-and-language (VQA, GQA, NLVR, MSCOCO) tasks. LST saves 69% of the memory costs to fine-tune the whole network, while other methods only save 26% of that in similar parameter usages (hence, 2.7x more memory savings). Moreover, LST achieves higher accuracy than Adapter and LoRA in a low-memory regime. To further show the advantage of this better memory efficiency, we also apply LST to larger T5 models (T5-large, T5-3B), attaining better GLUE performance than full fine-tuning and other PETL methods. The trend also holds in the experiments on vision-and-language tasks, where LST achieves similar accuracy to other PETL methods when training a similar number of parameters while also having 2.7x more memory savings.https://arxiv.org/abs/2206.06522

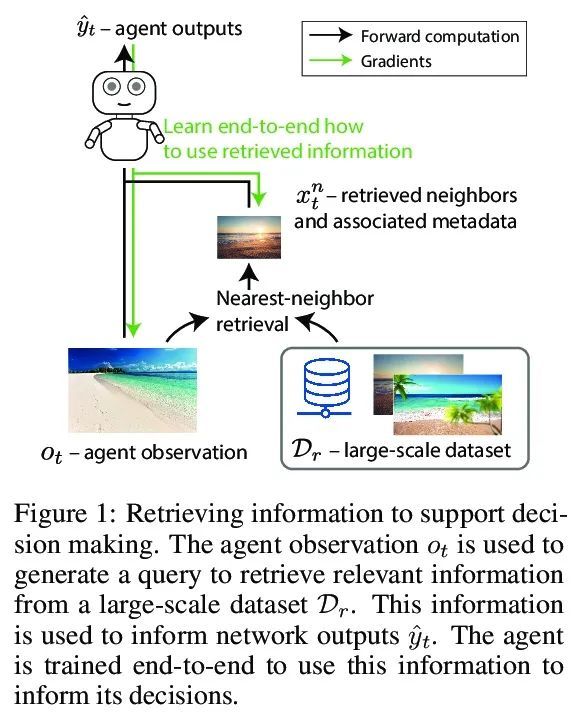
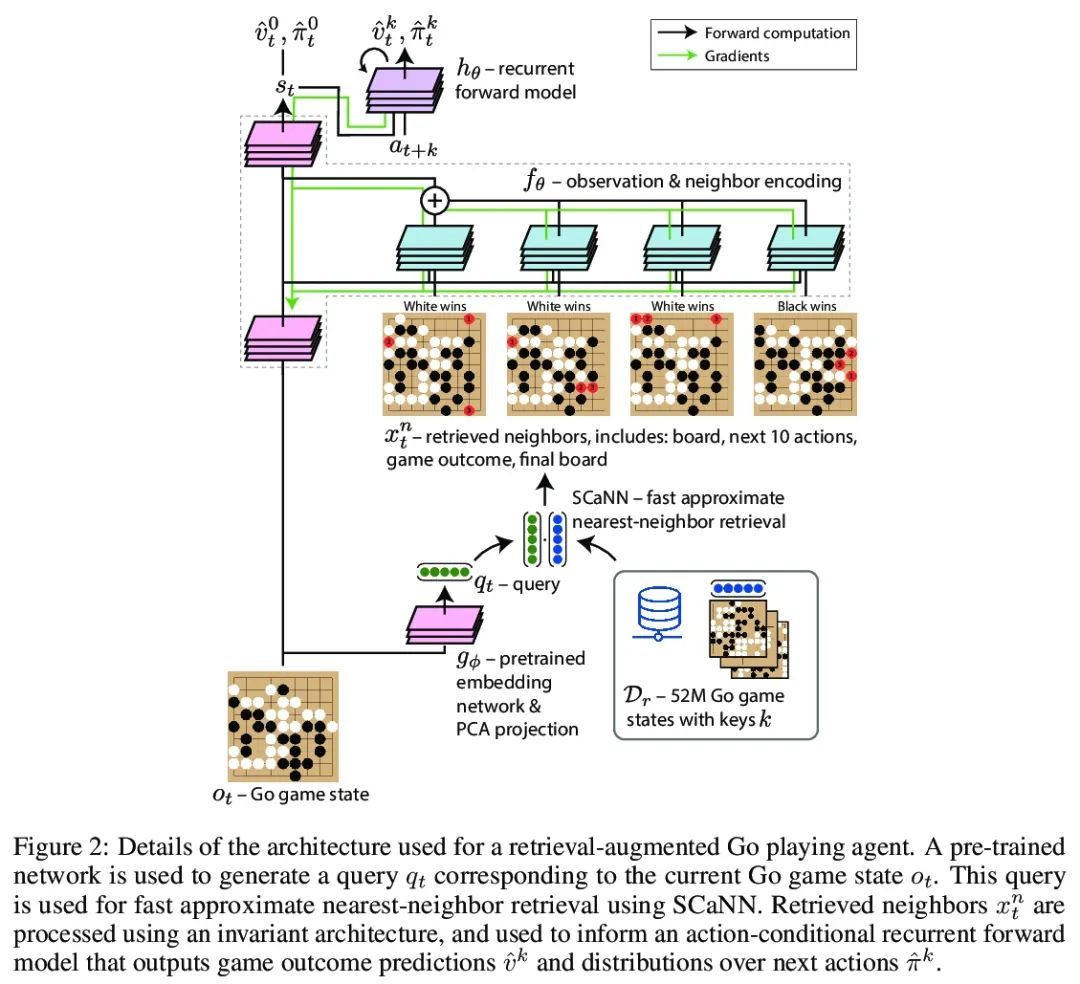
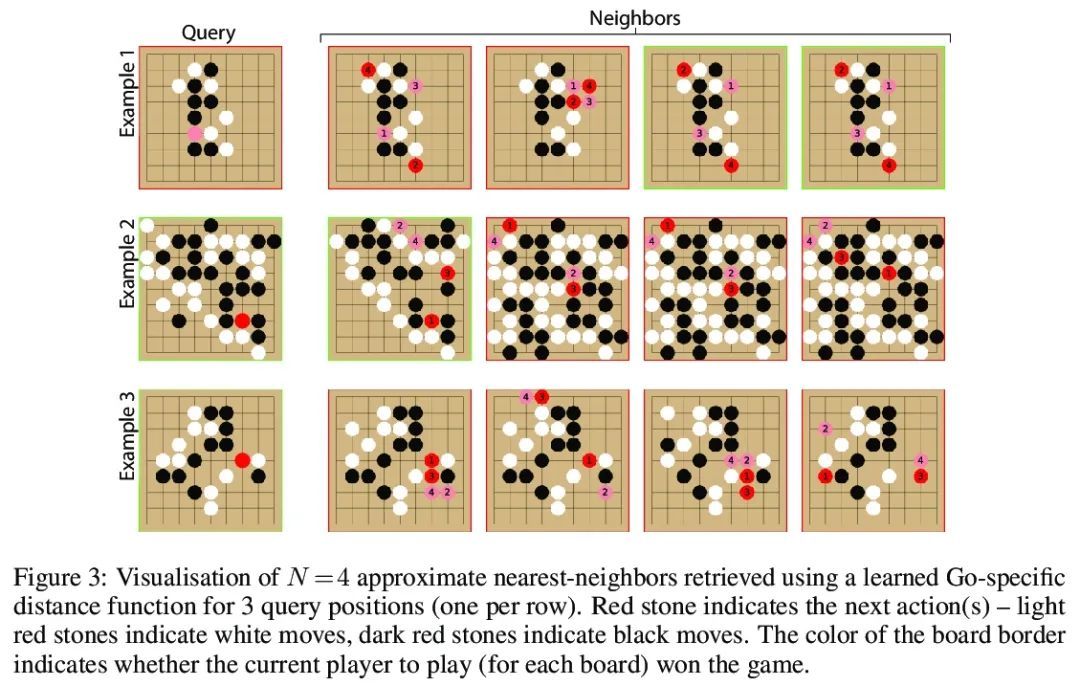
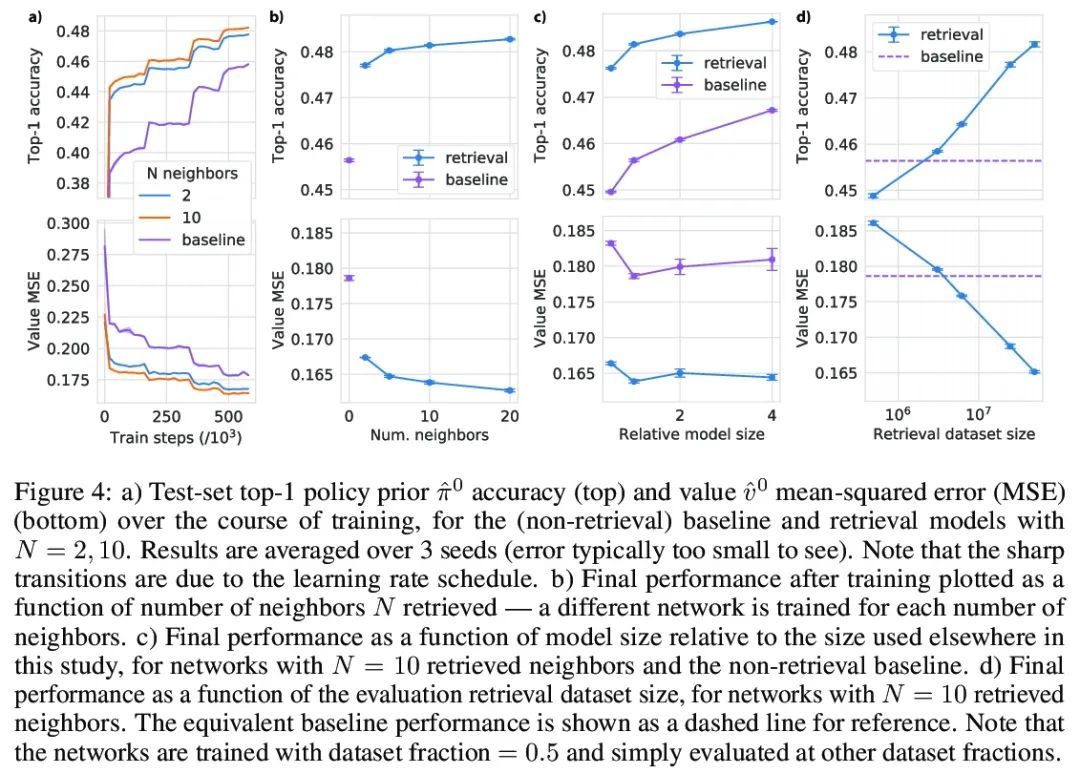
5、[LG] Large-Scale Retrieval for Reinforcement Learning
P C. Humphreys, A Guez, O Tieleman, L Sifre, T Weber, T Lillicrap
[Deepmind]
强化学习的大规模检索。有效的决策涉及将过去的经验和相关的上下文信息与新情况灵活联系起来。在深度强化学习中,主流范式是智能体通过训练损失的梯度下降将有助于决策的信息纳入其网络权重。本文追求另一种方法,即智能体可以利用大规模上下文敏感数据库查询来支持其参数化计算。允许智能体以端到端的方式直接学习,以利用相关信息来告知其输出。此外,通过简单地增加检索数据集,新的信息可以被智能体关注,而无需重新训练。在围棋中研究了这种方法,这是一种具有挑战性的游戏,对于该游戏来说,庞大的组合状态空间使泛化性优于与过去经验的直接匹配。利用快速、近似的近邻技术,从一组数千万的专家示范状态中检索相关数据。与简单使用这些演示作为训练轨迹相比,关注这些信息能极大提高预测的准确性和游戏性能,为强化学习智能体中大规模检索的价值提供了一个令人信服的证明。
Effective decision making involves flexibly relating past experiences and relevant contextual information to a novel situation. In deep reinforcement learning, the dominant paradigm is for an agent to amortise information that helps decisionmaking into its network weights via gradient descent on training losses. Here, we pursue an alternative approach in which agents can utilise large-scale contextsensitive database lookups to support their parametric computations. This allows agents to directly learn in an end-to-end manner to utilise relevant information to inform their outputs. In addition, new information can be attended to by the agent, without retraining, by simply augmenting the retrieval dataset. We study this approach in Go, a challenging game for which the vast combinatorial state space privileges generalisation over direct matching to past experiences. We leverage fast, approximate nearest neighbor techniques in order to retrieve relevant data from a set of tens of millions of expert demonstration states. Attending to this information provides a significant boost to prediction accuracy and game-play performance over simply using these demonstrations as training trajectories, providing a compelling demonstration of the value of large-scale retrieval in reinforcement learning agents.
https://arxiv.org/abs/2206.05314

另外几篇值得关注的论文:
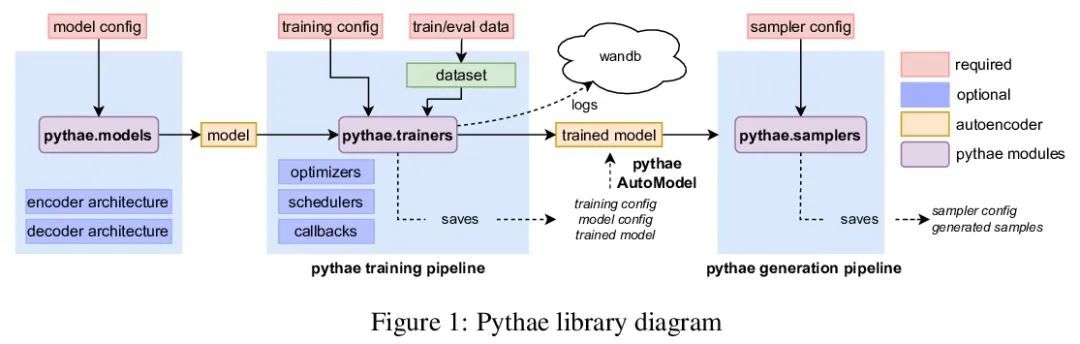
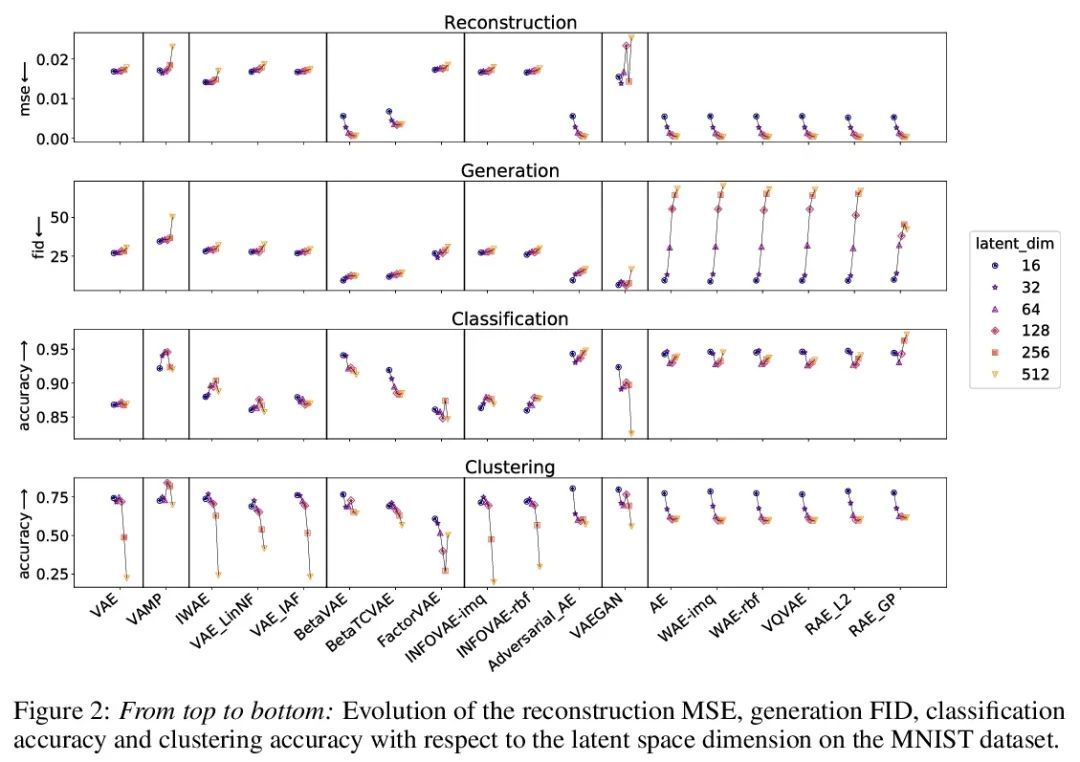
[LG] Pythae: Unifying Generative Autoencoders in Python - A Benchmarking Use Case
Pythae:Python统一生成式自编码器库
C Chadebec, L J. Vincent, S Allassonnière
[INRIA]
https://arxiv.org/abs/2206.08309

[CV] Diffusion Models for Video Prediction and Infilling
视频预测和填充的扩散模型
T Höppe, A Mehrjou, S Bauer, D Nielsen, A Dittadi
[KTH Stockholm & Max Planck Institute for Intelligent Systems & Norwegian Computing Center]
https://arxiv.org/abs/2206.07696





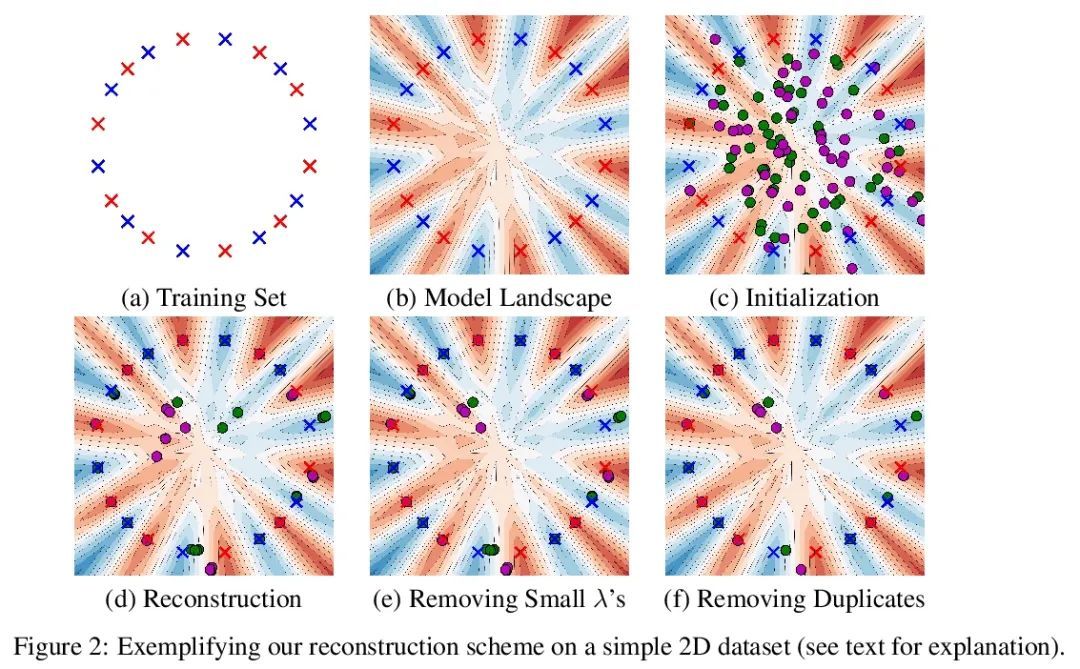
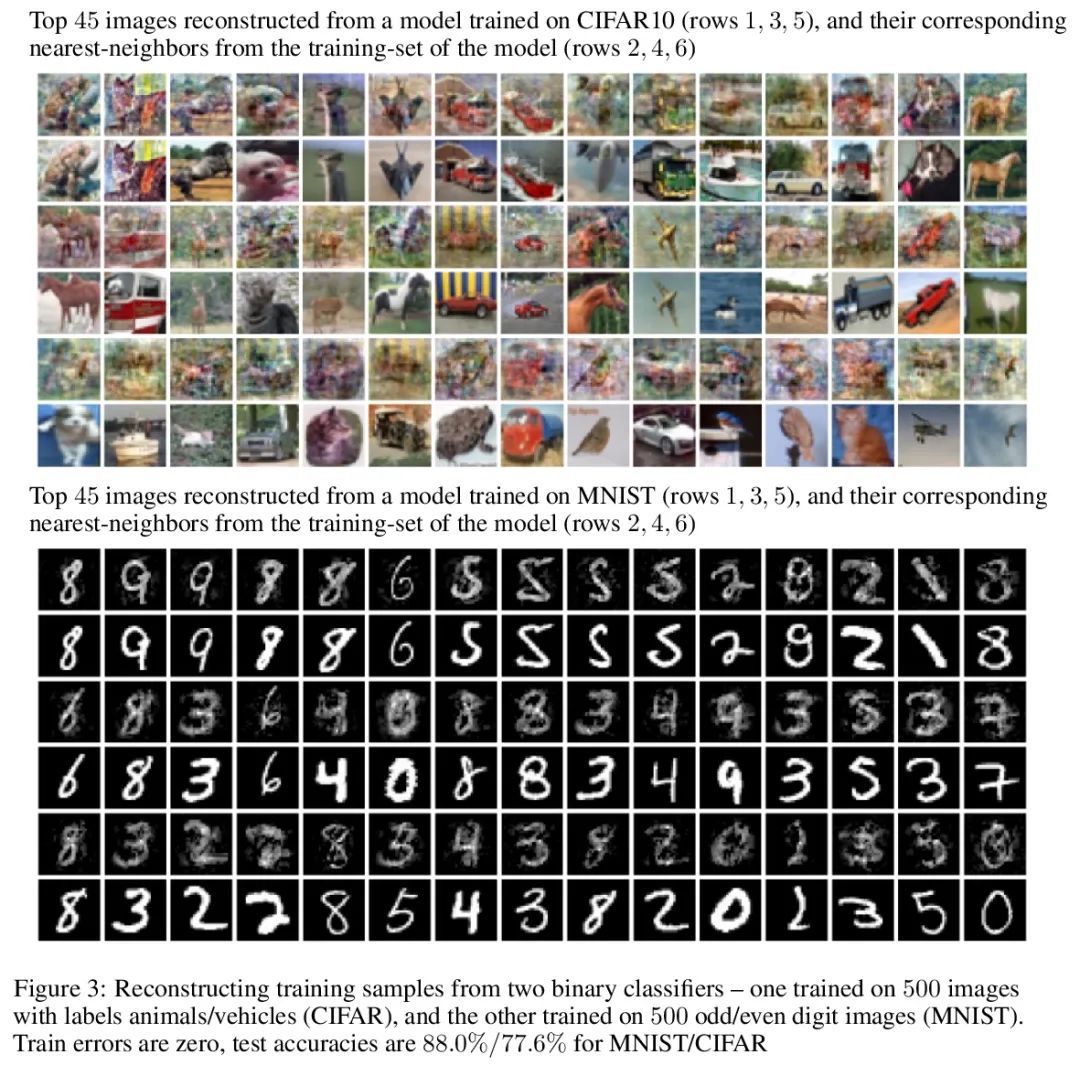
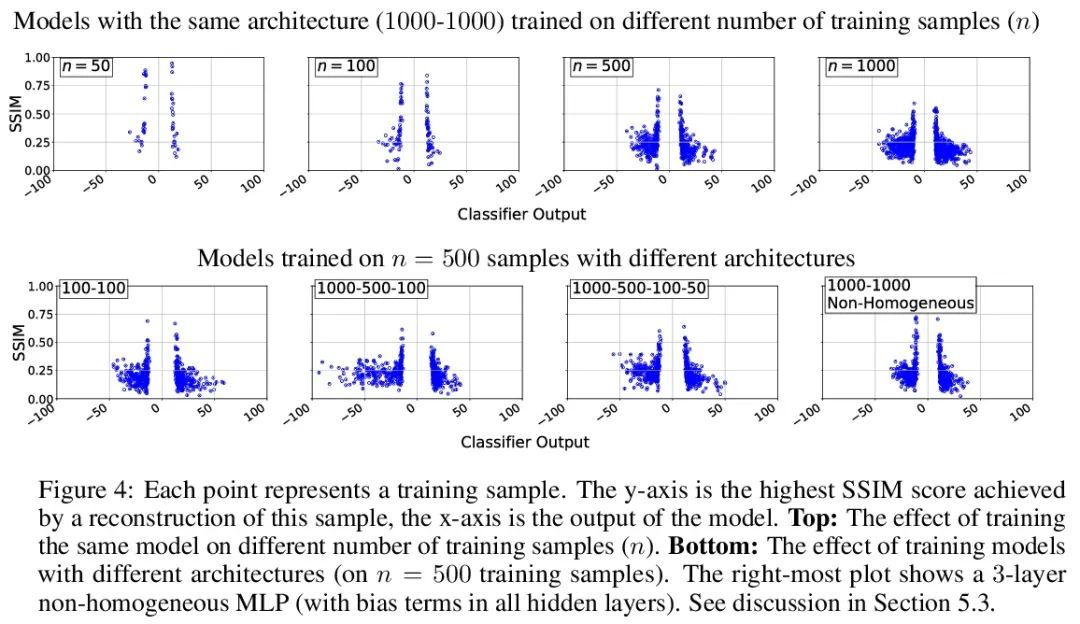
[LG] Reconstructing Training Data from Trained Neural Networks
从经过训练的神经网络重建训练数据
N Haim, G Vardi, G Yehudai, O Shamir, M Irani
[Weizmann Institute of Science]
https://arxiv.org/abs/2206.07758


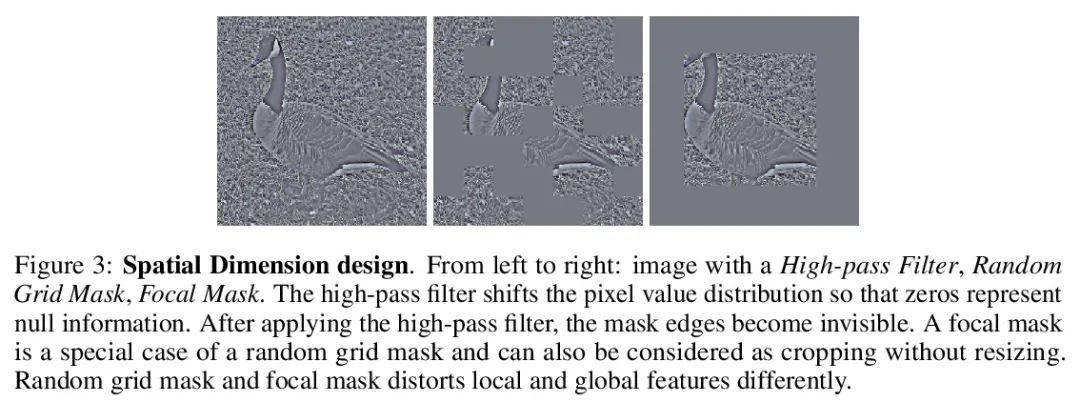
[CV] Masked Siamese ConvNets
掩码Siamese卷积网络
L Jing, J Zhu, Y LeCun
[Meta AI & NYU]
https://arxiv.org/abs/2206.07700




内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢