
前言
全球化下应用最广泛的 AI 技术是什么?机器翻译必然是其中之一。除了纯文本信息的传播,随着流媒体越来越普及,语音翻译有着越来越广泛的应用:大到国际会议的翻译,小到电影电视等视频翻译的字幕。


图:Netflix推出的韩剧《鱿鱼游戏》(Squid Game) 翻译成 31 种语言“火”遍全球90个国家,“椪糖挑战"也随之在TikTok上就掀起热潮。
语音翻译甚至出现在当下火热的“元宇宙”中,「字节火山引擎」和「亮亮视野」在2021年共同打造了AR眼镜,支持翻译功能,服务于会议场景,也可以帮助许多听残人士,为他们的世界加上了字幕,令人着实体验到了科技给生活带来的便利。
今年,Google I/O 大会上谷歌也展示了AR眼镜进行语音翻译成文字的原型,惊艳到了不少科技发烧友。

图为谷歌CEO桑德尔在I/O大会上展示AR眼镜项目
以上的这些应用,其实都离不开语音翻译技术的加持。如何更方便快速地将语音翻译系统部署到这些端上?这是近年来业界和学术界最关心的课题之一。
端到端语音翻译
语音翻译的传统方法是串联起语音识别(automatic speech recognition, ASR)系统和机器翻译(machine translation, MT)系统,这样的方法被称为语音识别-机器翻译级联系统 (cascaded system)。另一方面,因为部署方便,端到端语音翻译 (end-to-end speech translation) 新技术最近获得了极大的关注。端到端语音翻译无需得到语音的转写内容,直接将语音转化为目标端的语言,这显然更为直接简洁。然而,标注好的“语音-转写-翻译”数据远远不如文本翻译那么丰富,这成了端到端语音翻译模型训练的一大瓶颈。
多任务累进学习
如何克服这瓶颈?知识蒸馏[1]、预训练[2][3]、多任务学习[4][5]… 纷纷被验证可以缓解数据缺少带来的问题,提升翻译质量。其中多任务学习确实是一种简单可行的解决之道,实践证明同时训练语音翻译 (ST)、语音识别 (ASR) 、机器翻译 (MT) 确实有更好的泛化能力。
其中 XSTNet[4]是一个比较典型的可以支持多任务累进学习的结构。在输入端,它既可以接受语音输入,又可以接受文本输入。对于语音输入,利用 wav2vec2 [6] 和几层卷积层提取语音特征;模型中的 transformer encoder 和 decoder 是“语音-到-文本”和“文本-到-文本”共享的。训练方面,采用“多任务累进学习”的意思是,模型(1)先用“文本-到-文本”数据对Transformer Encoder和Decoder进行预训练,(2)然后再多任务共同优化语音翻译、文本翻译、语音识别任务。
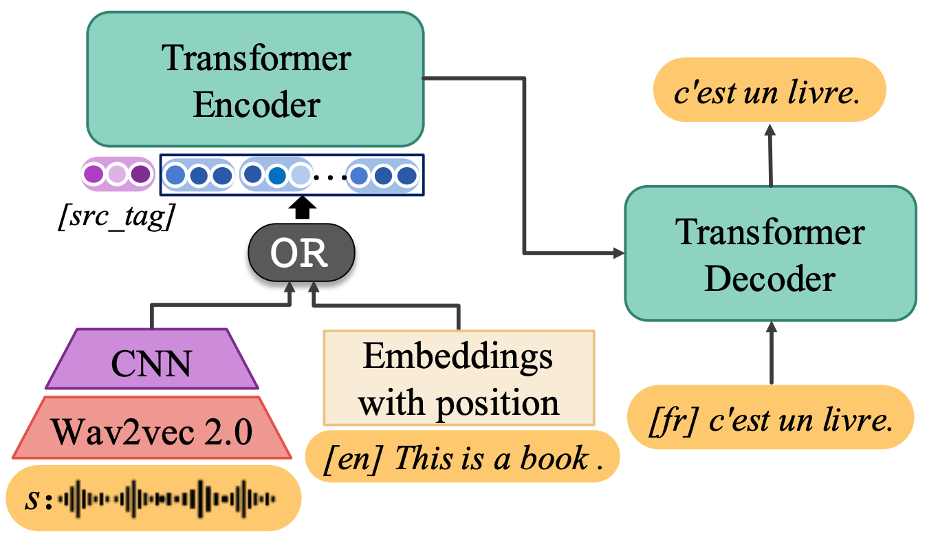
多任务累进学习框架 XSTNet[4] 的图示
模态鸿沟——多任务累进学习无法解决的痛
虽然多任务学习模型获得了不错的效果,可是当我们从表示角度,观察重语音和文本两个不同模态的表示时,我们发现两者依旧存在鸿沟,如下图中 (a) current models 所示,现在的多任务学习模型中,同一句话,同一个意思,语音和文本的表示依旧有较大差距,而我们期望的是,对于同一句话,比如语音的 “it’s a nice day!” 和文本的 “it’s a nice day!” 的表示应该是相近的(如 (b) Expected 所示)。


左图:多任务学习框架下语音和文本两者表示之间依旧存在差距;右图:我们所期望的两个模态表示:相同意思的语音和文本应该有相近的表示。
所以怎样才能缩小两个模态的表示的鸿沟,从而提升语音翻译的表现呢?
这里给大家介绍在字节跳动 AI-Lab 与 UCSB 发表在 NAACL 2022 的长文:Cross-modal Contrastive Learning for Speech Translation[7]。本文提出 ConST 模型,其在语音翻译上获得了当前最好的效果。此外,本文探讨了如何将跨模态对比学习更好利用到语音翻译上。

论文地址:
https://arxiv.org/abs/2205.02444
代码地址:
https://github.com/ReneeYe/ConST
ConST:利用对比学习解决模态鸿沟
ConST 模型依旧采取了可接受双头输入的结构,对于语音有特有的 S-Enc 学习表征,transformer encoder decoder模块是语音和文本共享的。ConST的模型结构如下图所示。
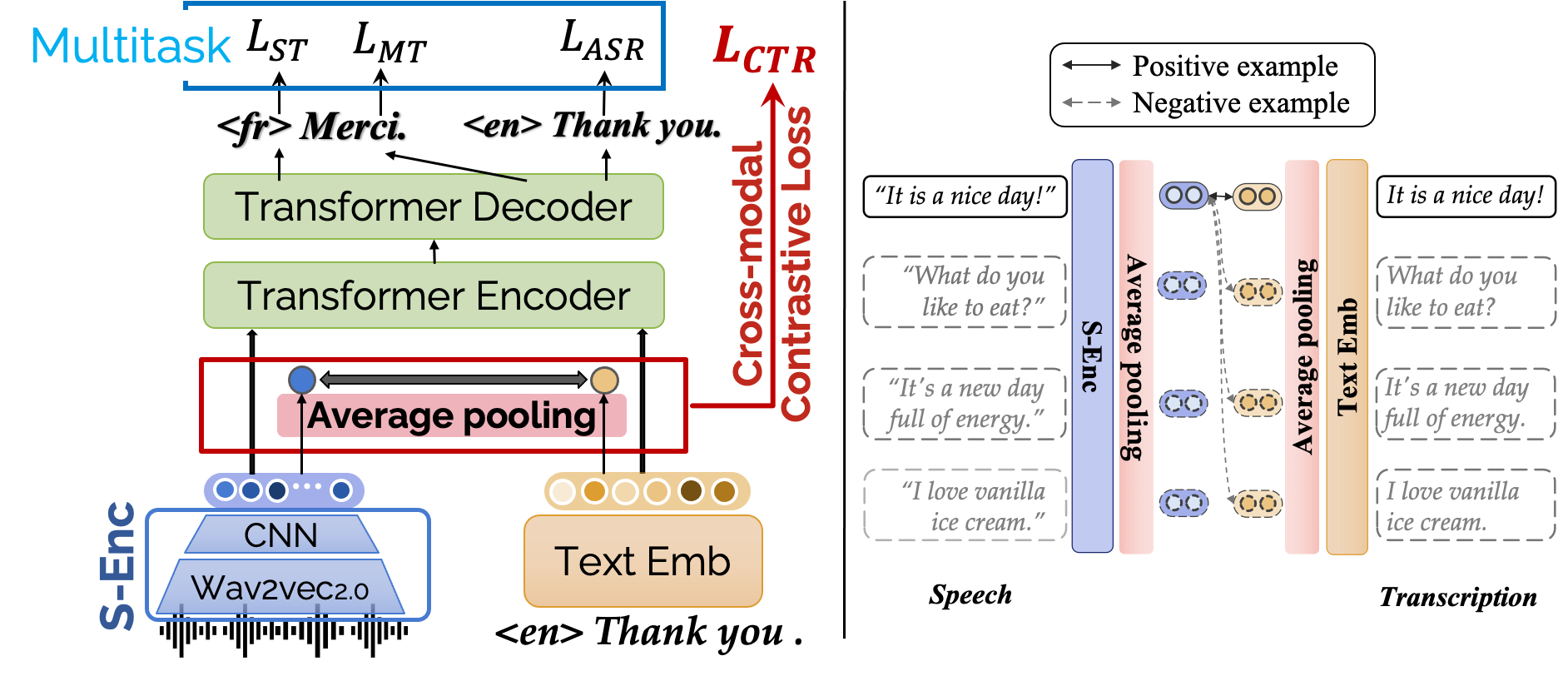
图:ConST模型架构和训练损失函数——多任务损失和对比损失的加权和
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢