
【导读】深度学习中的分布外 (OoD) 泛化是指模型在分布变化的场景下进行泛化的任务。现在受到众多关注。最近,清华大学崔鹏等研究者发布了《分布外泛化(Out-Of-Distribution Generalization)》综述论文,针对该领域的系统、全面地探讨了OOD泛化问题,从定义、方法、评价到启示和未来发展方向。

摘要
经典的机器学习方法是建立在i.i.d.假设的基础上的,即训练和测试数据是独立同分布的。然而,在真实场景中,i.i.d.假设很难得到满足,导致经典机器学习算法在分布移位下的性能急剧下降,这表明研究非分布泛化问题的重要性。Out-of-Distribution分布外 (OOD)泛化问题解决了测试分布未知且与训练不同的挑战性设置。本文首次系统、全面地探讨了OOD泛化问题,从定义、方法、评价到启示和未来发展方向。首先,给出了OOD泛化问题的形式化定义。其次,根据现有方法在整个学习流程中的位置,将其分为无监督表示学习、有监督模型学习与优化三部分,并详细讨论了每一类的典型方法。然后,我们展示了不同类别的理论联系,并介绍了常用的数据集和评价指标。最后,对全文文献进行了总结,并对OOD泛化问题提出了未来的研究方向。本次综述OOD泛化文献可在http://out-of-distribution-generalization.com上找到。
地址:
http://out-of-distribution-generalization.com
引言
现代机器学习技术在计算机视觉、自然语言处理和推荐等领域表现出了出色的能力。许多研究在实验条件下获得了着超越人类的表现,但也揭示了机器学习模型在暴露于不同分布数据时的脆弱性。如此巨大的差距是由于违背了训练和测试数据是相同且独立分布的基本假设(又名i.i.d.假设),而大多数现有的学习模型都是基于这个假设开发的。在许多难以满足i.i.d.假设的实际案例中,尤其是医疗、军事和自动驾驶等高风险应用中,与训练分布内的泛化相比,分布转移下的泛化能力更为重要。因此,对分布外泛化问题的研究在学术界和工业界都具有重要的现实意义。
尽管OOD泛化问题很重要,但是经典的监督学习方法并不能直接解决这个问题。从理论上讲,经典的监督学习最基本的假设之一是i.i.d.假设,它假设训练和测试数据是独立的、同分布的。然而,在OOD泛化问题中,分布偏移是不可避免的,这破坏了i.i.d.假设,使得经典的学习理论不再适用。从经验上看,经典的监督学习方法通常通过最小化训练误差来优化,这些误差贪心式地吸收数据中发现的所有相关性来进行预测。虽然在i.i.d设置中被证明是有效的,但它会在分布变化下损害性能,因为不是所有的相关性将在看不见的测试分布中保持。如[1],[2],[3],[4],[5]等文献所示,当涉及到强分布转移时,仅考虑训练误差的优化模型会显著失败,有时甚至比随机猜测更糟糕,这说明设计OOD泛化问题的方法迫在眉睫。
为了解决OOD泛化问题,还存在几个关键问题有待解决。首先,由于训练和测试数据可以从不同的分布中提取,因此如何形式化地描述分布偏移仍然是一个悬而未决的问题。在OOD泛化文献中,不同的方法分支采用不同的方法来模拟潜在测试分布。领域泛化方法[6],[7],[8],[9]主要关注真实场景,利用不同领域的数据。因果学习方法[2],[10],[11]制定了具有因果结构的训练和测试分布,分布转移主要来源于干预或混杂因素。稳定学习方法[4],[12],[13]通过选择偏差引入分布偏移。其次,如何设计一种具有良好OOD泛化性能的算法是目前研究的热点,方法有很多分支,研究重点不同,包括无监督表示学习方法、有监督学习模型和优化方法。第三,不同方法的OOD性能评价仍然具有挑战性,这需要特定的数据集和评价指标,因为经典的i.i.d.设置方法在分布转移下不适用。这也促使了不同数据集的生成和评估。
在本文中,我们旨在提供一个相当广泛的意义上的OOD泛化系统的全面研究成果,涵盖了从定义,方法,评价的整个生命周期的OOD问题的影响和未来的方向。据我们所知,我们是第一个在如此大的范围和自成一体的形式中讨论分布外泛化的努力。在此之前,已有一些著作对相关问题进行了讨论。如[14]、[15]主要讨论领域泛化;[16]讨论OOD泛化的评价基准。之前的每一篇作品都是整个非分布泛化问题的一块拼图,而在这篇作品中,我们以清晰简洁的方式将所有成分有机地整合在一起。具体来说,我们根据现有方法在整个学习流程中的位置将其分为三类。我们还通过因果关系的视角阐述了不同方法之间的理论联系。为了促进OOD泛化研究的进一步深入,本文对分布偏移下的学习方法评价进行了详尽的综述。
为了应对未知分布偏移带来的挑战,人们在分布外泛化方面做了大量的工作,相关方法的文献也非常丰富。所采用的技术从因果关系到表示学习,从基于结构到基于优化,各有不同。然而,就我们所知,很少有人从广义的OOD泛化的角度对这些不同的方法进行系统和全面的考察,并阐明这些工作之间的区别和联系。在本文中,我们试图首先通过回顾OOD泛化的相关方法来填补这一空白。
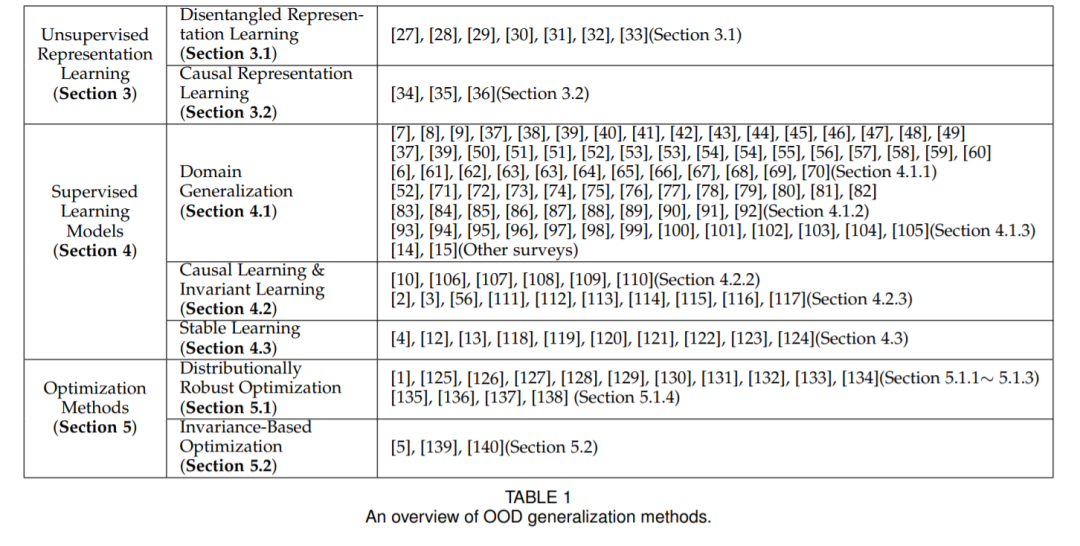
一般来说,定义为式1的监督学习问题可以分为三个相对独立的分量,即(1)特征X的表示(如g(X)); (2)从特征X(或g(X))到标号Y的映射函数fθ(X),一般又称模型或归纳偏差; (3)优化目标的制定。因此,我们根据现有方法在整个学习流程中的位置,将其分为三个部分:
- 面向OOD泛化的无监督表示学习:包括解纠缠表示学习和因果表示学习,它们利用无监督表示学习技术(如变分贝叶斯)将先验知识嵌入到学习过程中。
- 面向OOD泛化的监督模型学习:包括因果学习、稳定学习和领域泛化,设计各种模型体系结构和学习策略来实现OOD泛化。
- OOD泛化优化:包括分布鲁棒优化和基于不变的优化,直接制定OOD泛化目标,并在理论上保证OOD最优性的前提下进行优化。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢