

论文链接:https://www.aaai.org/AAAI22Papers/AAAI-12678.LiuZ.pdf
导读
近年来,自监督学习(SSL)尤其是对比学习方法因其能够在无语义标注的情况下学习有效的可迁移表示而备受关注。自监督预训练的常见做法是使用尽可能多的数据。然而,从本文的大量实验中观察到,对于特定的下游任务,在预训练中涉及无关数据可能会降低下游性能。另一方面,对于现有的SSL方法,在针对不同任务的预训练中使用不同的下游任务定制数据集比较繁琐。为了解决这个问题,作者提出了一种称为可扩展动态路由(Scalable Dynamic Routing,SDR)的新SSL范式,该范式可以训练一次,并使用任务定制的预训练模型有效地部署到不同的下游任务。具体地说,作者用不同的子网构造SDRnet,并通过数据感知渐进式训练,仅用数据的一个子集训练每个子网。当下游任务到达时,在所有预训练的子网之间进行路由,以获得最佳的子网及其相应的权重。实验结果表明,本文的SDR可以在ImageNet上同时训练256个子网,这比在完整ImageNet上训练的统一模型提供了更好的迁移性能,在11个下游分类任务上达到了最先进的平均精度,在PASCAL VOC检测任务上达到了SOTA结果。
贡献
最近,自监督学习(SSL)引起了人们的广泛关注,它通过无语义标注的借口任务(pretext task)学习表征。SSL的最新研究表明,与监督学习相比,SSL在各种下游任务上的表现具有竞争力,甚至更好。
SSL可以在模型预训练中使用大量未标记数据。然而,在自监督的预训练中,更多的数据是否总能带来更好的迁移性能?换言之,对于特定的下游任务,预训练中的无关数据会影响下游性能吗?
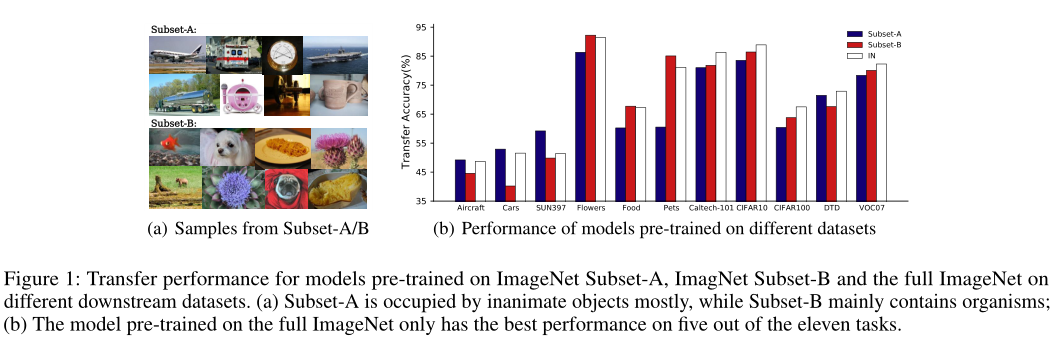
为了回答上述问题,作者进行了一系列实验。作者基于它们在WordNet Tree中的语义差异,故意将ImageNet拆分为两个不相交的子集,即子集A和子集B。使用SimSiam在没有数据注释的情况下分别对具有子集A、子集B和完整ImageNet的模型进行预训练,并在11个下游分类数据集上评估迁移性能。三种模型的训练时间相同。
如上图(b)所示,在子集A上预训练的模型在飞机、汽车和SUN397上的迁移性能最好,而在子集B上预训练的模型在鲜花、宠物和食物上的迁移性能最好。11个下游任务中只有5个从完整的ImageNet中获益更多。结果表明,在预训练中加入不相关的数据反而可能会损害下游性能。这种现象被认为是自监督训练中的负迁移。
流行的SSL方法,如MoCo-v2和SimSiam通常忽略负迁移的影响,并为不同的下游任务提供一个通用的预训练模型。消除负迁移影响的一个简单扩展是使用任务特定的数据集对模型进行预训练。然而,考虑到预训练的繁重计算成本,这种扩展实际上是不切实际的。之前有工作简单地将大规模数据集(即YFCC100)拆分为不同的子集,用于定制模型预训练,这对于大量下游任务来说是不可扩展的。作者希望开发一种高效的SSL范式,提供任务定制的预训练模型。
在这项工作中,作者提出了一种新的SSL范式,称为可拓展动态路由(SDR),它可以为不同的下游任务实现动态预训练和高效部署。具体来说,作者用不同的子网构建SDRnet,并用包含不同语义簇的不同数据子集训练每个子网。作者进一步提出了一个数据感知的渐进式训练框架,以稳定子网的预训练过程并避免崩溃。当下游任务到达时,作者在所有子网之间进行路由,以获得最佳的预训练模型及其权重。通过使用SDR,模型能够同时预训练一系列子网,以便高效部署各种下游任务。
总之,本文的主要贡献是:
- 通过大量实验,作者发现SSL中存在负迁移现象,即使用无关数据进行预训练可能会降低特定下游任务中的迁移性能。
- 本文提出了可拓展动态路由(SDR),这是一种新的SSL范式,可以通过提供高效、可拓展的任务定制自监督预训练模型来缓解负迁移的影响。
- 作者成功地在ImageNet上同时训练了256个子网,并在11个下游分类数据集和AP的PASCAL VOC检测任务中达到了SOTA的平均精度。
方法
3.1 Overview of SimSiam
SimSiam从图像x中随机选取两个增强视图x1和x2作为输入。这两个视图由编码器f处理,编码器包含主干网络和投影MLP头h。编码器在x1和x2之间共享权重SimSiam通过比较编码器输出和预测头输出的相似性来学习表示。最后,损失计算如下:
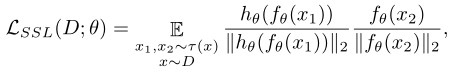
其中|| ||2表示l2范数,D,τ()分别表示未标记的训练数据集和数据增强的分布。此外,在实现过程中,采用了stop-gradient操作,以避免训练崩溃。
3.2 Scalable Dynamic Routing
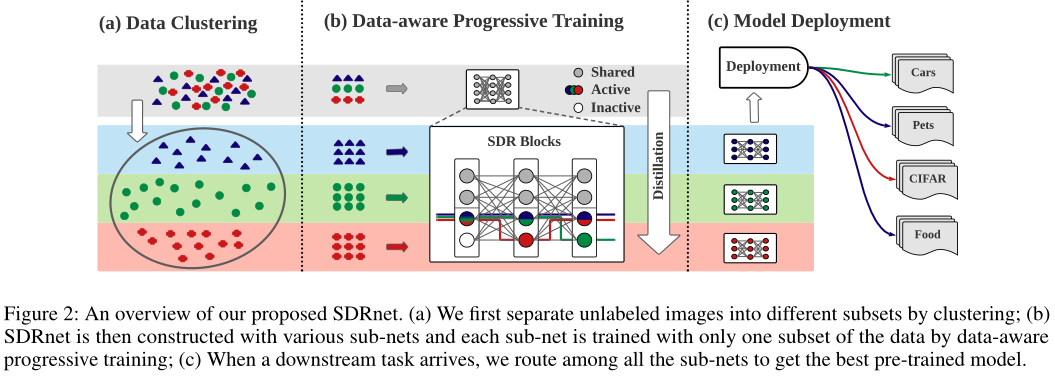
如上图所示,本文的可拓展动态路由(SDR)包括三个步骤。首先,作者将数据集聚类为不相交的子集,然后构建包含多个子网的SDRnet模型,并通过数据感知渐进式训练动态地训练每个子网及其相应的子集(如下图的算法1所示)。在预训练之后,可以在所有子网之间进行路由,以找到最适合于特定下游任务的子网。

Data clustering
SDR的基本思想是应用不同语义的数据同时高效地训练不同的网络。采用聚类方法将未标记的训练数据分组到不同的语义聚类中。作者首先使用整个数据集预训练SimSiam模型,并收集所有图像特征,表示为F=[f1,f2,...fn]。大规模聚类是在F上进行的。
具体来说,将k设置为所需的簇数,并将簇的可学习质心定义为C。然后,将特征分配给聚类可以计算为S=FTC。作者定义了一个辅助矩阵U,它可以被视为聚类的后验分布。本文的目标是最大化U和S之间的相似性,可以表示为:
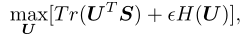
其中H(U)表示的熵,模型迭代优化U和C。U通过迭代Sinkhornkonpp算法求解,而C通过SGD学习,以最小化U和之间的交叉熵。经过几次训练后,作者采用S作为分配矩阵。最终的聚类结果表示为,表示整个数据集。
Framework optimization
整个SDRnet将由整个训练集D0进行训练,而第i个子网Di将使用其相应的子数据集进行额外训练。设W0为总网络的权重,Wi是与第i个子网相对应的权重。训练损失可以形式化为:
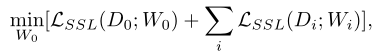
总体目标是同时优化SDRnet和子网在其相应数据集上的权重。
Splits of sub-nets and SDR block
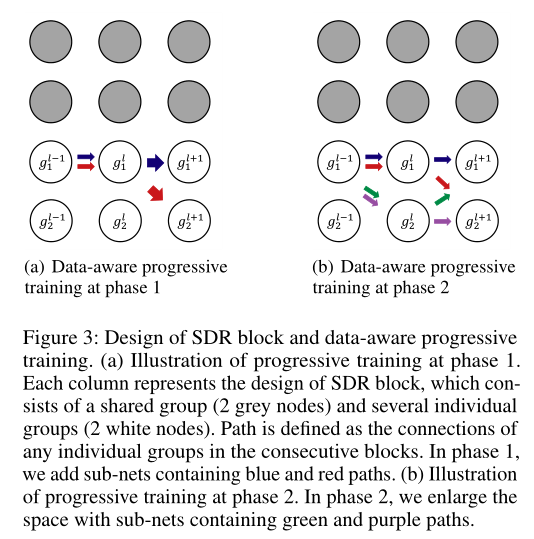
SDR块是从ResNet块修改而来的,可扩展到大量子网。作者将上图中的每一列表示为一个块。将每个块的通道分为两部分:单独组和共享组。路径定义为连续块之间单个组的任意连接。共有3个块(列),每个块包含2个共享组(灰色节点)和2个单独组(白色节点)。
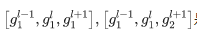 是显示为蓝色和红色路径的两个示例路径,其中gli表示第l个块的第i个单独组。路径的总数可以根据单个组的数量和块的数量来计算,在上图中则为2^3=8。当中的数据出现时,将通过共享组和路径中定义的单独组的concatenation来推断块,因此被定义为相应路径中的参数和所有共享组的并集。
是显示为蓝色和红色路径的两个示例路径,其中gli表示第l个块的第i个单独组。路径的总数可以根据单个组的数量和块的数量来计算,在上图中则为2^3=8。当中的数据出现时,将通过共享组和路径中定义的单独组的concatenation来推断块,因此被定义为相应路径中的参数和所有共享组的并集。
Data-aware progressive training
由于训练过程的不稳定性,同时训练大量子网是一个挑战。在自监督学习中,单纯地对子网进行采样并使用相应的数据集对其进行训练往往会导致不稳定性,最终导致特征崩溃。因此,作者提出了数据感知的逐块渐进式训练来稳定优化过程。在每个阶段之后,逐步定义并扩大网络空间。在每个阶段,只对空间内的网络进行采样和训练。
具体来说,网络空间最初只包含最大的网络。最初开始添加路径仅在最后一个块中不同的子网(如上图a的红蓝路径)。在下一阶段中,将继续添加路径为绿色和紫色的子网。通过这种渐进式训练,模型能够同时训练最大的网络和多个子网络。
Task-customized knowledge distillation
除了逐块渐进式训练外,作者还提出了一种任务特定的蒸馏方法SiamKD。具体而言,子网提供的特征也可用于预测最大网络的特征。损失函数为:
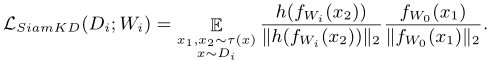
在计算时,停止梯度操作是在SDRnet上执行的,因为将SDRnet单边提取到每个子网。实验表明,SiamKD显著优于L2蒸馏损失。
3.3 Deployment
当下游任务到来时,可以在所有子网之间进行路由,以找到任务的最佳预训练模型。对于分类任务,一个实际实现是采用k-近邻(kNN)分类器进行快速性能评估。对于检测任务,可以应用提前停止来选择最佳的预训练模型。
实验
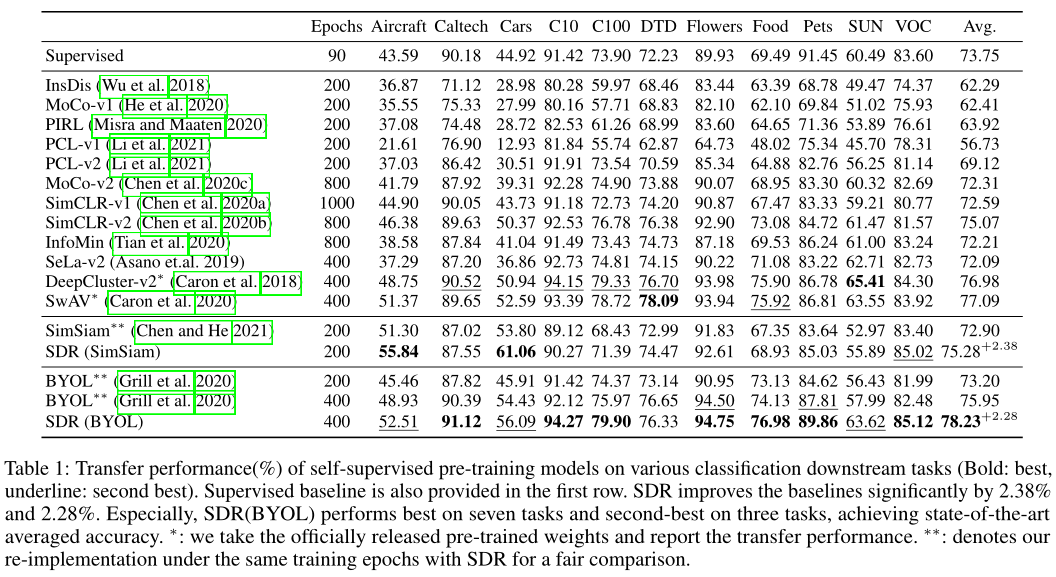
上表总结了分类任务中预训练模型的迁移性能。可以看出,与在完整ImageNet(即SimSiam和BYOL baseline)上预训练的模型相比,SDR提高了所有下游数据集的性能。SDR在11个下游任务上的准确率分别提高了2.38%和2.23%,证明了任务定制预训练对缓解负迁移的有效性。
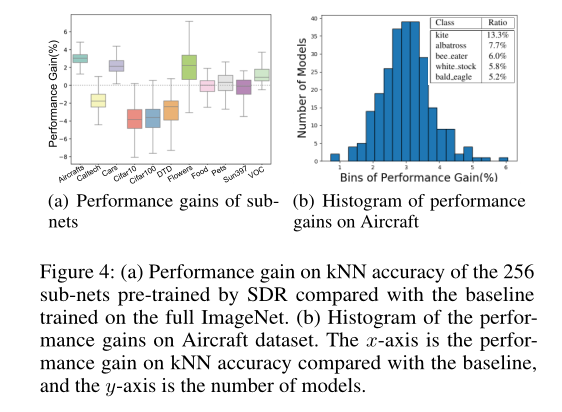
作者注意到,对于不同的下游数据集,子网的性能差异很大。如上图(a)所示,与在全ImageNet上训练的baseline相比,256个子网的kNN精度性能有所提高。使用SDR时,包括Aircraft、Cars和Flowers在内的下游任务的平均性能有显著提高。这可能是因为这些数据集是对负迁移敏感的细粒度数据集。因此,ImageNet的子集倾向于提供更好的预训练模型。另一方面,在使用SDR时,诸如CIFAR10、CIFAR100和DTD等下游任务的改进有限。这可能是因为这些数据集包含类似于ImageNet中的类,所以负迁移的影响可以忽略不计。因此,完整的ImageNet可以提供更适用的预训练模型。
上图(b)绘制了256个子网上Aircraft数据集的kNN精度直方图。可以看出,Aircraft的最佳预训练模型实际上是在ImageNet的子集上预训练的,该子集主要包含飞行物体的图像,如风筝、信天翁和鹳。结果表明,数据聚类和数据感知渐进式训练过程是有效的。
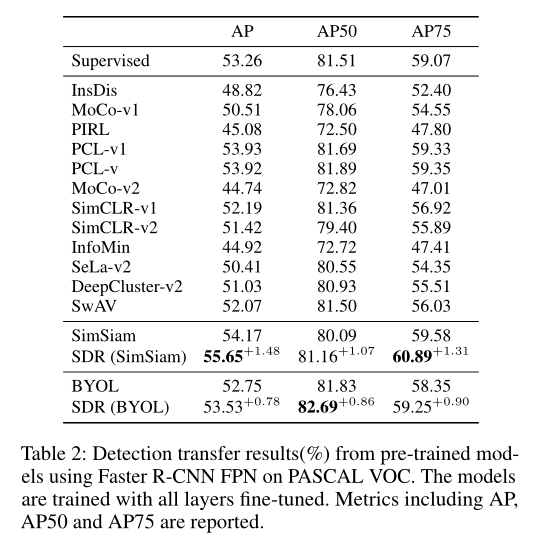
检测任务的传输结果如上表所示。对于检测任务,与在完整ImageNet上预先训练的模型相比,在模型尺寸较小的AP中,SDR也将baseline提高了1.48%和0.78%。
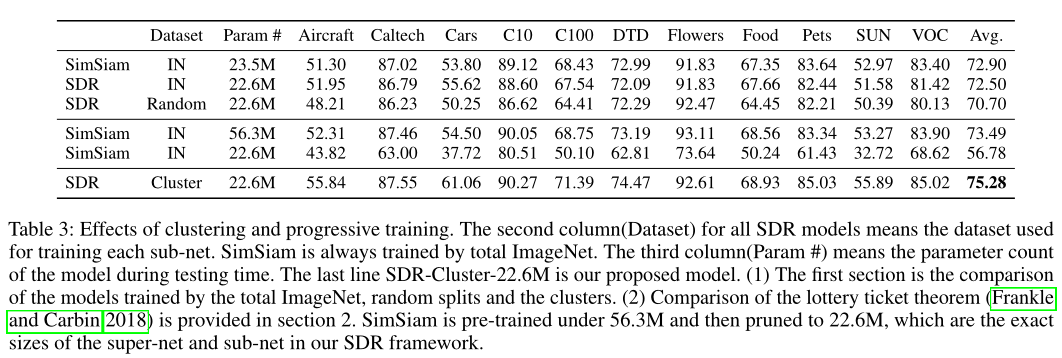
在上表中,作者对本文提出的组件进行了消融实验,可以看出,本文提出的组件都是非常有效的。
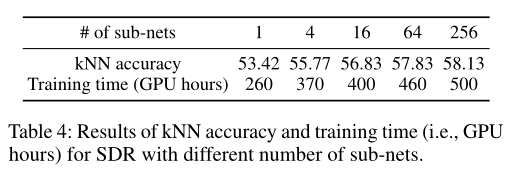
作者通过评估11个下游任务的kNN平均精度,分析不同数量的子网如何影响最终结果。带有一个子网的模型实际上是SimSiam baseline。kNN精度和相应的训练时间如上表所示。随着子网数量的增加,kNN精度显著提高。

上图展示了不同聚类数据的图片样本。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢