
本文提出了一个统一的纯视觉3D感知框架PETRv2。基于PETR,PETRv2探究了利用历史帧的信息来进行时序建模,大幅度地提升了3D物体检测的性能。具体来说,我们扩展了PETR中所提出的3D position embedding (3D PE)来进行时序建模,证明3D PE能够实现不同帧物体空间位置的对齐。进一步地,我们引入了一个特征引导的位置编码器,来改善3D PE对于不同输入数据的适应性。为使PETR框架能够同时进行高质量的BEV分割,PETRv2提供了一个简单而又高效的解决方案。我们引入了一些分割查询向量,每个分割查询变量用于分割BEV图像中特定的块区域。PETRv2在3D物体检测和BEV分割任务上均有着先进的性能表现。基于PETR系列框架,本文也进行了详细的鲁棒性分析,我们希望PETRv2能够作为一个简单而又强大的基线框架。

论文名称:
PETRv2: A Unified Framework for 3D Perception from Multi-Camera Images
论文链接:
https://arxiv.org/pdf/2206.01256.pdf
代码链接:
https://github.com/megvii-research/PETR,支持2080ti等低端显卡训练。
一、研究动机
近期,基于纯视觉(多个摄像头图像)的3D感知受到广泛关注。如何结合输入数据流的时序信息,并将3D检测、BEV分割等多项感知任务整合到一个统一的框架中具有重大意义。BEVFormer1和BEVDet4D2是近期比较有代表性的两个方法,通过结合时序建模实现了出色的检测性能。然而,这些方法大都选择bird-eye-view(BEV)空间进行时序的特征对齐,并利用BEV特征进行分割。考虑到重建得到的BEV特征相比于range view(RV)特征可能有信息损失,且特征之间的对齐往往需要自定义算子不利于硬件部署。于是,我们考虑是否可以不依赖于BEV特征来实现时序对齐并支持BEV分割。
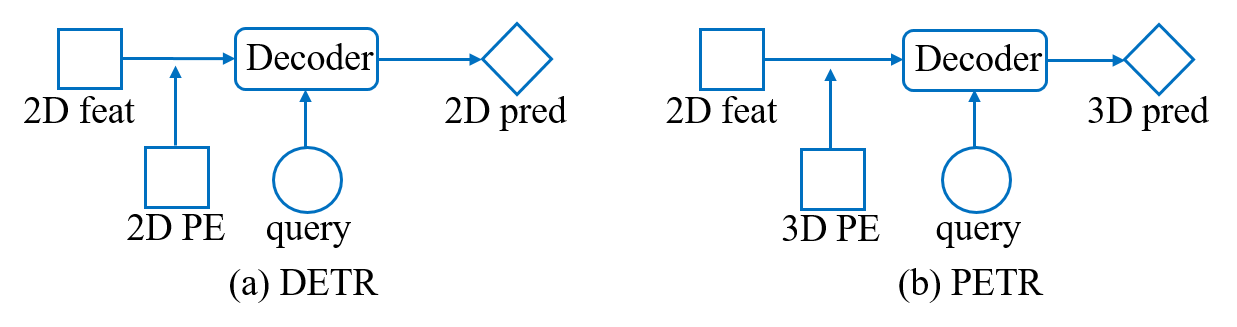
图一 DETR和PETR对比示意图,图来源于PETR。
我们的方法主要启发于近期提出的PETR3框架。如图一所示,PETR基于DETR4框架,引入了3D position embeding(3D PE)的概念,将3D coordinates信息编码进2D RV特征使其对3D空间位置敏感,如此一来,query可以和RV特征直接在decoder中交互并预测3D检测结果,无需显式的空间变换。本文中,我们对PETR框架进行如下的几项改进:
- 我们将PETR中的3D PE扩展到时序版本,通过对生成的3D coordinates进行变换,实现了时序对齐。
- PETR中,3D PE的生成是data-independent的,我们引入了一个特征引导的位置编码器,使得3D PE的生成和输入数据相关,隐式地从特征中获取到深度等信息。
- 我们引入了一个简单高效的方案来支持BEV分割。受SOLQ5启发,DETR框架中一个query足以表征一块区域内的掩码,为此我们定义若干个分割查询向量实现高质量的BEV分割。
二、方法
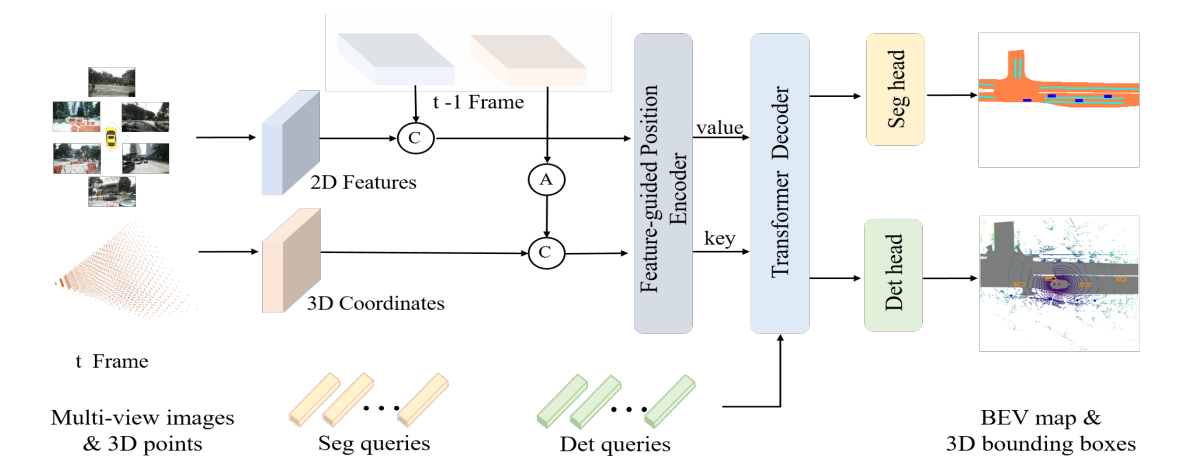
图二 PETRv2结构图。'A’表示时序对齐,'C’表示拼接操作。
2.1 整体框架
如图二所示,PETRv2的框架主要基于PETR,其输入为前后两帧( t−1 帧与t 帧)的2D features和视锥空间中3D points所对应的3D coordinates。首先, t−1 帧与 t 帧的3D Coordinates进行时序对齐(2.2节描述)并拼接到一起,两帧的特征则直接进行拼接。然后,2D features和3D coordinates输入到特征引导的位置编码器(2.3节描述)中,将对齐后的3D Coordinates转换为3D position embeding (3D PE),并与2D features相结合,生成后续Transformer解码器(2.4节描述)的key、value元素。之后,seg query、det query与前述生成的key、value在Transformer decoder中进行交互。最后,交互更新后的两类query送入两个任务的head,输出检测和分割结果。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢