

论文链接:
https://arxiv.org/abs/2111.13336
代码链接:
https://github.com/alibaba/lightweight-neural-architecture-search
导读
本文提出一种基于最大熵原理的目标检测搜索方法:MAE-Det。该方法通过计算最大特征的最大熵来代表网络的表达能力,代替训练网络来评估模型的最后性能,同时设计了多级维度的最大熵来适配检测任务的不同尺度下的表达能力。Training-free的策略将NAS的搜索成本降低接近零,在相同的FLOPs预算下,MAE-Det可以为目标检测设计更好的特征提取器。在仅仅一天的GPU全自动设计,MAE-DET在多个检测基准数据集上刷新了检测主干网络的SOTA性能。与ResNet-50主干相比,在使用相同数量的FLOP和参数下,MAE-DET在mAP中的性能提高了+2.0%;在相同的mAP下,在NVIDIA V100上的推理速度提升1.54倍。

贡献
在目标检测中,作为特征提取的主干网络消耗的推理成本占据总成本的一半以上。最近的研究试图通过借助神经结构搜索(NAS)来优化主干结构,从而降低这一块成本。然而,现有的NAS目标检测方法需要数百到数千个GPU小时的搜索,这使得它们在快节奏的研发中很不实用。
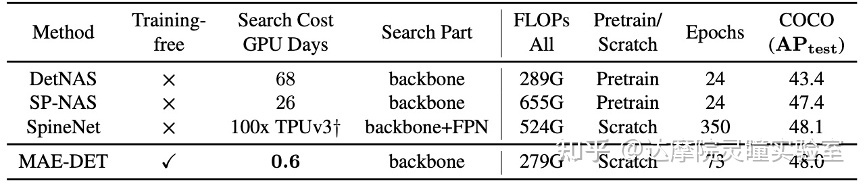
表1 现有方法搜索效率对比
作为NAS方法的代表,DetNAS、SP-NAS和SpineNet依旧采用训练评估(Training-based)的搜索方法,在搜索的过程需要通过训练来评估后续网络的性能。DetNAS使用one-shot的方法构建一个SuperNet,从SuperNet中采样小的网络在数据集中评估,需要68个GPU days搜索出最佳的网络;SP-NAS使用串并行的多层结构,通过进化算法随机迭代block进行筛选,可以在26个GPU days获得最佳的网络;SpineNet将backbone的搜索和FPN的搜索结合在一起,搜索不同分辨率下的特征的排列组合,使用100块TPUv3最后获得搜索的网络。虽然这些方法搜索的主干网络性能也超过R50的baseline,但是Training-based的策略极大地消耗GPU资源,需要消耗几十天的GPU资源,而且只能用于较少迭代的网络的数量。
方法
1、最大熵原理(Maximum Entropy Principle)
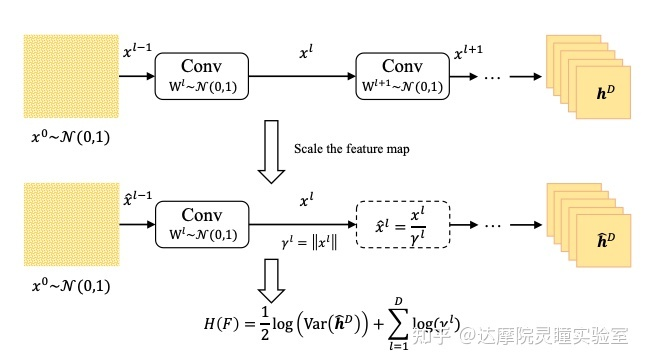
图2 基于最大熵的原理计算公式
为了对网络架构进行细粒度分析,我们在系统搜索时只应用了2D CNN,而不添加激活、BN等辅助模块,这种结构是在深度学习早期提出的最简单的网络模型之一,在理论文献中被广泛用作原型分析。在最后的训练时会结合任务将这些辅助模块重新添加回来,来让训练性能最大化。具体来说,给定一个2D卷积网络,其中包含L层卷积核,如图2所示,最后一层的特征可以通过下面公式来表达:
\( {x}^{l}=\phi\left({h}^{l}\right), {h}^{l}=\mathbf{W}^{l} * {x}^{l-1} \quad l=1, \ldots, D \)
我们将神经网络看作是一个信息系统,那么对于一个给定的输入,最后一个输出特征图的微分熵代表系统的最后的信息量。信息量可以由微分熵来表示,因此微分熵最大的模型结构的表达能力也应该是最强的。对于给定初始化的输入和权重,最后一个输出特征图的微分熵的分布具有确定的均值和方差。根据高斯熵上界定理,我们知道对于已知均值和方差的高维特征,当其符合高斯分布的时候,对应的微分熵最大,因此高斯微分熵代表了特征分布的信息上界。在计算微分熵时,高斯分布的微分熵只与方差正相关,而与均值无关,忽略掉一些常数,最后基于最大熵理论得出的系统的上限熵由下式给出:
\( H(F)=\frac{1}{2} \log \left(\text{Var}\left({h}^{D}\right)\right) \)
其中,我们假设输入和权重都通过标准高斯初始化后,该公式可以通过每次的前向传播来计算,并且我们借鉴了Zen-NAS中使用的缩放机制用于应对数值溢出,最终的公式如图2所示。
2、目标检测的多级维度最大熵
相比于识别任务,检测任务更需要保证网络结构在不同尺度下的表达能力。如图3所示常见的目标检测模型由骨干网络(backbone)、特征金字塔网络(FPN)和头网络(head)构成。骨干网络会从三个维度C3/C4/C5来输出特征金字塔网络所需要的特征,因此如果仅仅像图2中算最后特征C5的Score而忽略C3/C4的特征的话,那么目标检测的骨干网络将不是最优的。所以我们对C3/C4/C5 3个维度分别算每一个子网络的最大熵,最后通过权重来调节不同维度的表达能力,从而让整体网络表达能力达到最优,最后的多级信息熵用来评估检测特征提取器的总体表达能力。
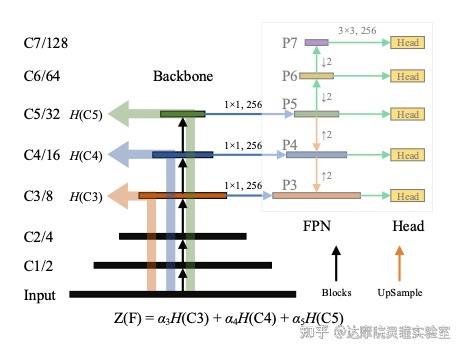
图3 基于多级维度的最大熵结构图
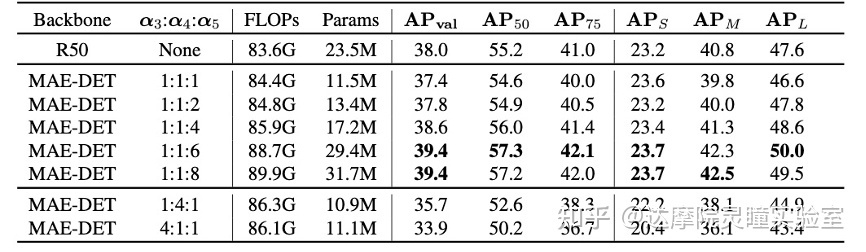
表2 基于不同维度比例的FCOS下的3X训练结果
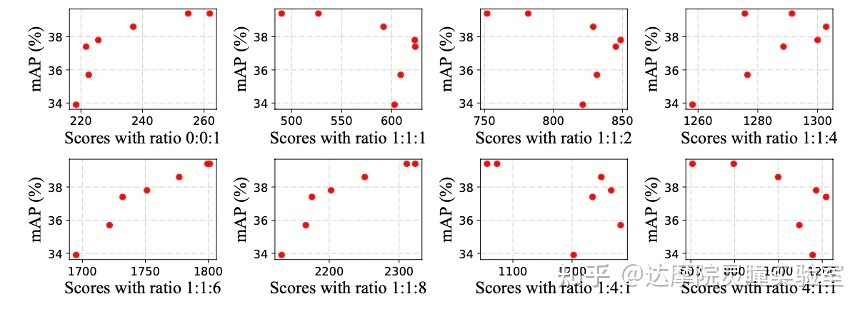
图4 不同比例下的mAP与score的相关性
进一步我们在一个较宽的范围内调整多维度比例的选择。我们选择了七个不同权重比用于搜索不同的模型,所有模型都在COCO数据集上使用FCOS框架和3x训练策略。图3显示,如果C3-C5的权重相同,MAE-DET在COCO上的性能比ResNet-50差。考虑到C5的重要性,我们增加了C5的权重,MAE-DET的性能继续改善。为了进一步探索mAP和分数之间的相关性,我们使用七个权重比来计算每个模型的不同分数,以及0:0:1的单一维度权重比。mAP和不同分数之间的相关性如图5所示。根据图4和图5中的结果,我们确认1:1:6的比例对于当前的FPN结构可能足够好,适用于大部分的多级检测结构。
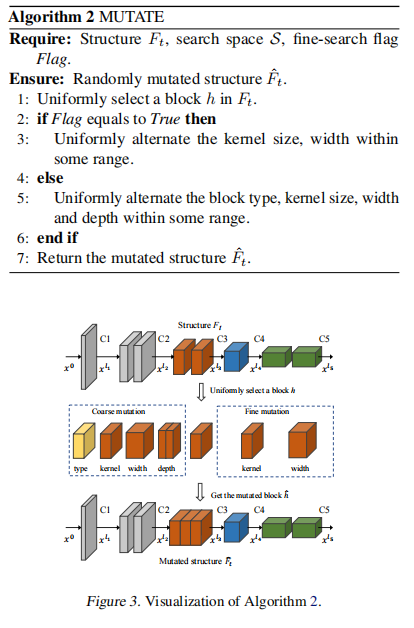
基于以上的方法,我们结合进化算法最终设计了MAE-DET用于检测骨干网络的搜索,算法流程如下图所示:

其中,第8行的MUTATE表示对NAS的潜在种子结构进行随机生成,其算法流程如下图所示:
实验
1、Performance
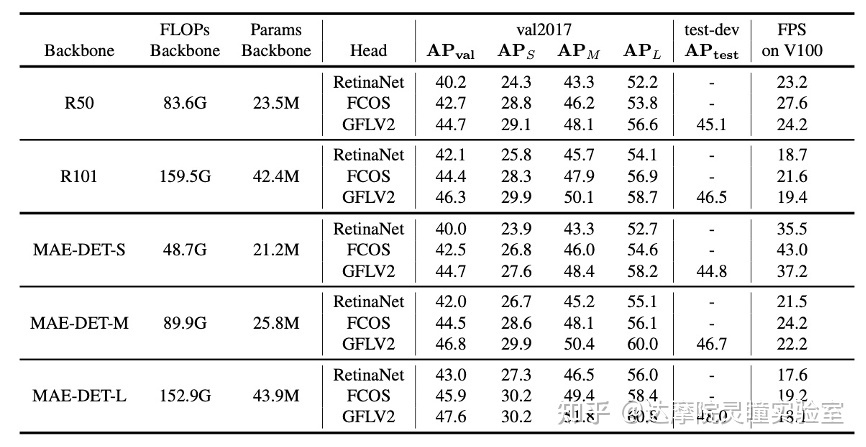
表3 MAE-DET在不同框架下雨R50的比较结果
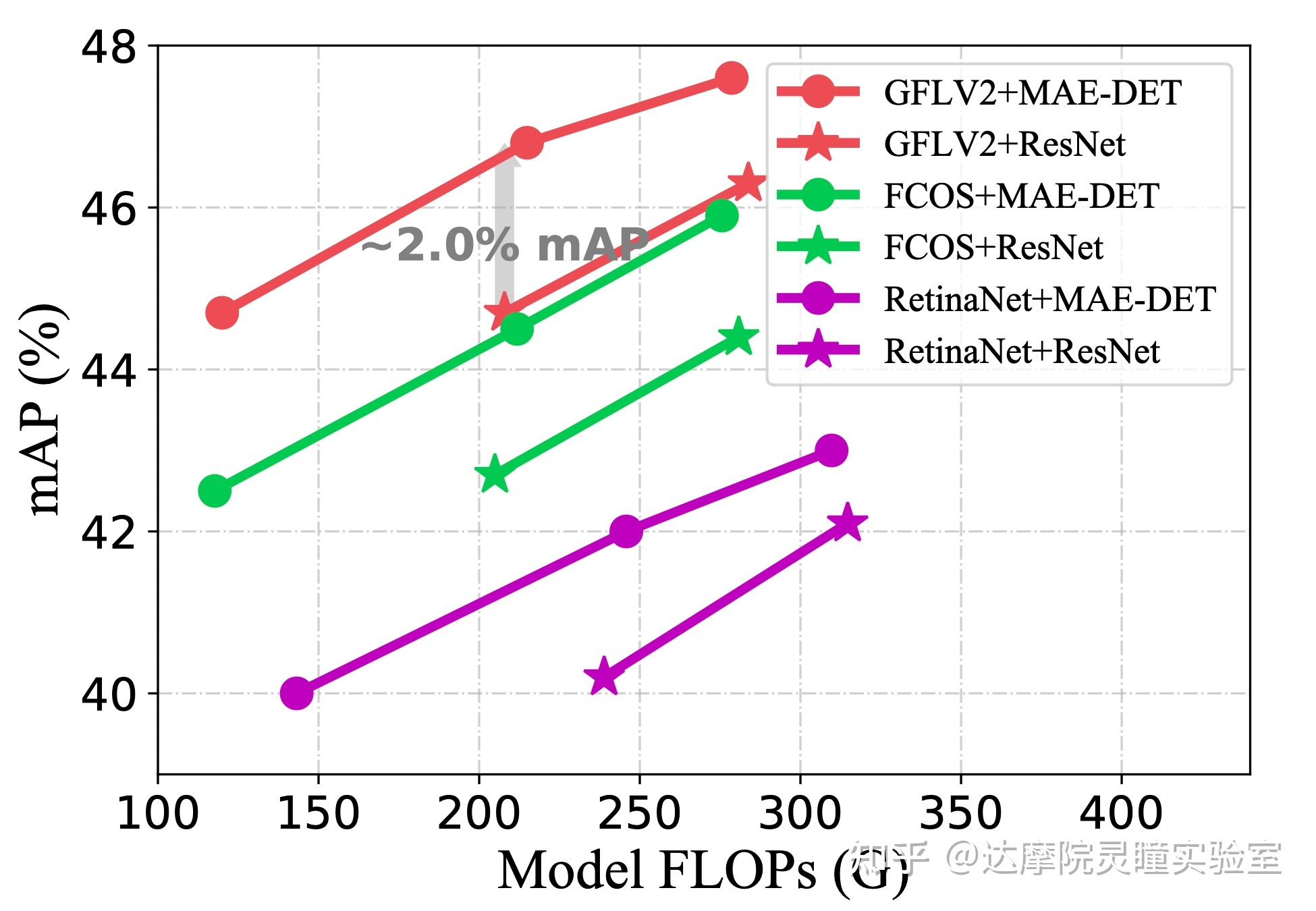
图5.1 MAE-DET在不同框架下与R50的性能比较
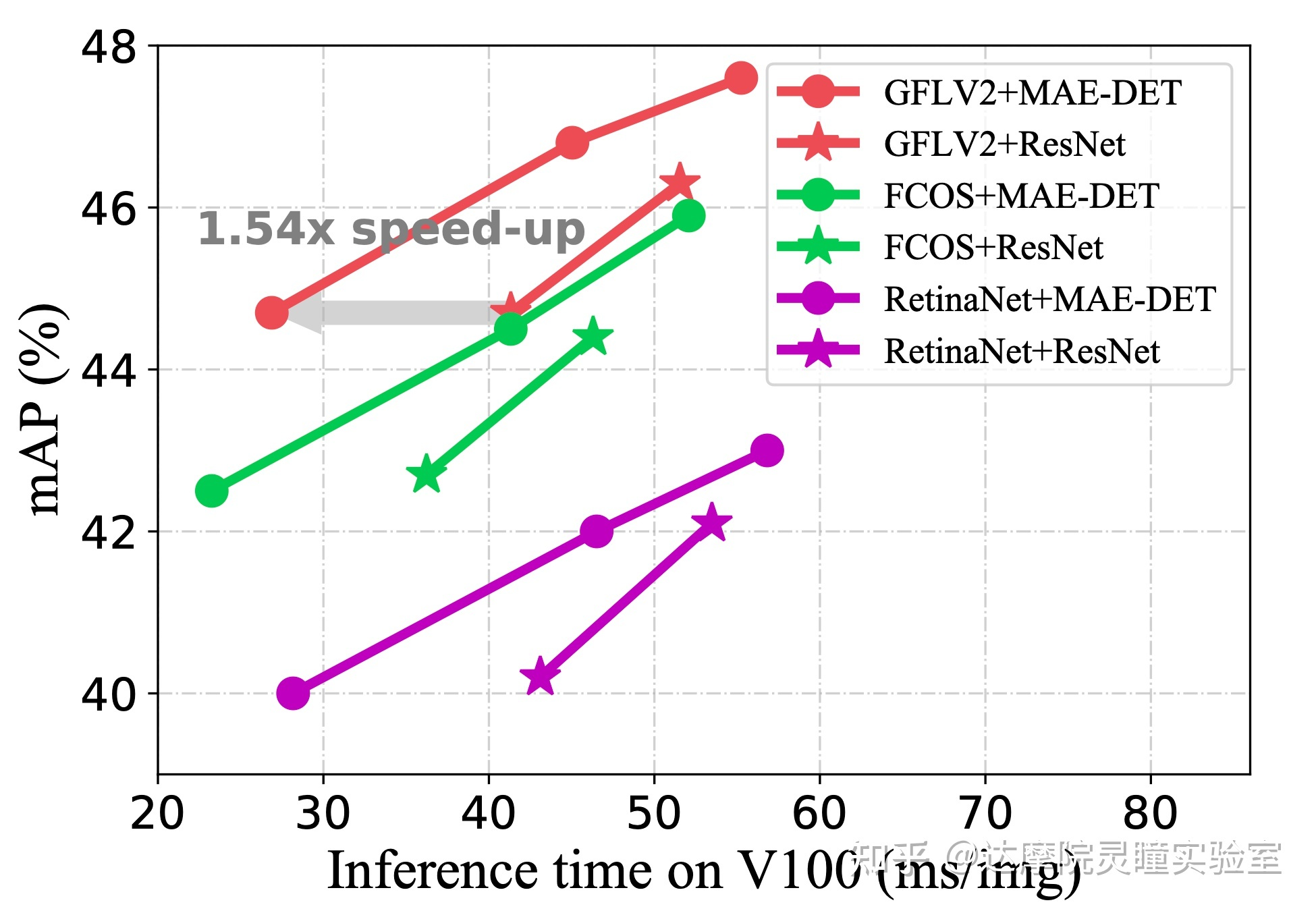
图5.2 MAE-DET在不同框架下与R50的性能比较
我们搜索用于目标检测的与ResNet-50/101对齐的高效MAE-DET主干网络。MAE-DET-S比ResNet-50使用更少60%的FLOPs;MAE-DET-M与ResNet-50一致,具有与ResNet-50类似的FLOPs和参数数量;MAE-DET-L与ResNet-101对齐。对于MAE-DET-M和MAE-DET-L,FPN和heads中的特征尺寸设置为256,但对于MAE-DET-S,设置为192。在图6和图7中,MAE-DET的表现大大优于ResNet,且在三种检测框架的改进是一致的。特别是,当使用最新的框架GFLV2时,MAE-DET在与ResNet-50类似的FLOPs情况下将COCO mAP提高了+2%,并在与ResNet-50相同的精度下将推理速度提高了1.54倍。
2、其他的NAS方法
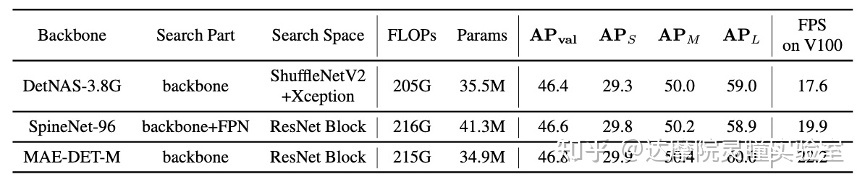
表4 在相同训练条件下比较其他NAS方法搜索到的结构
除了图1中的搜索效率的对比,为了进一步公平地比较相同训练设置下的不同主干,我们在图7中训练了由MAE-DET设计的主干和以前的主干NAS方法。由于SP-NAS的网络结构不是开源的,我们从头开始在COCO上重新培训MAE-DET、DetNAS和SpineNet。图8表明MAE-DET在COCO上实现了与DetNAS和SpineNet相同的性能,但需要的参数更少,在V100上的推理速度更快。
3、多数据集和分割任务
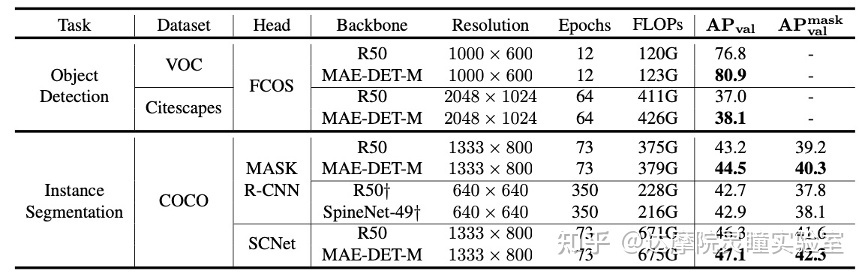
表5 在多数据集和实例分割任务重的结果
为了评估MAE-DET在不同数据集和不同任务中的可迁移性,我们将基于FCOS的MAE-DET-M转移到VOC和Cityscapes数据集中。如图9的上半部分所示,训练在ImageNet上预训练后,对模型进行了微调。与ResNet-50相比,MAE-DET-M在VOC方面的mAP提高了+4.1%,在Cityscapes方面的mAP提高了+1.1%。图9的的下半部分报告了COCO实例分段任务的mask R-CNN和SCNet模型的结果,训练采用6X从头训练策略。与ResNet-50相比,在模型大小和FLOPs近似的情况下,MAE-DET-M 在mask R-CNN和SCNet上实现了更好的AP和mask AP。
参考
https://github.com/alibaba/lightweight-neural-architecture-search
https://www.techbeat.net/article-info?id=3688
https://mp.weixin.qq.com/s/20wF8ppE6__vuaFdzO6UfQ
https://mp.weixin.qq.com/s/5jKimbCWnhZlCGAybbCzzg
https://mp.weixin.qq.com/s/QlHqNZ05YaAXF5M0Ol0cQA
https://mp.weixin.qq.com/s/4ByvyNuN2pgr-gHxLmXvJg
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢