
本文分享论文『MoCoViT: Mobile Convolutional Vision Transformer』,由字节跳动提出轻量级高效新型网络MoCoViT,在分类、检测等CV任务上性能优于GhostNet、MobileNetV3!

论文链接:
https://arxiv.org/abs/2205.12635
摘要
最近,Transformer 在各种视觉任务上取得了不错的成果。然而,它们中的大多数计算成本很高,不适合于实际的移动应用程序。在这项工作中,作者提出了移动卷积视觉Transformer(MoCoViT),它通过将Transfomrer引入移动卷积网络(mobile convolutional networks)来利用这两种架构的优点,从而提高性能和效率。
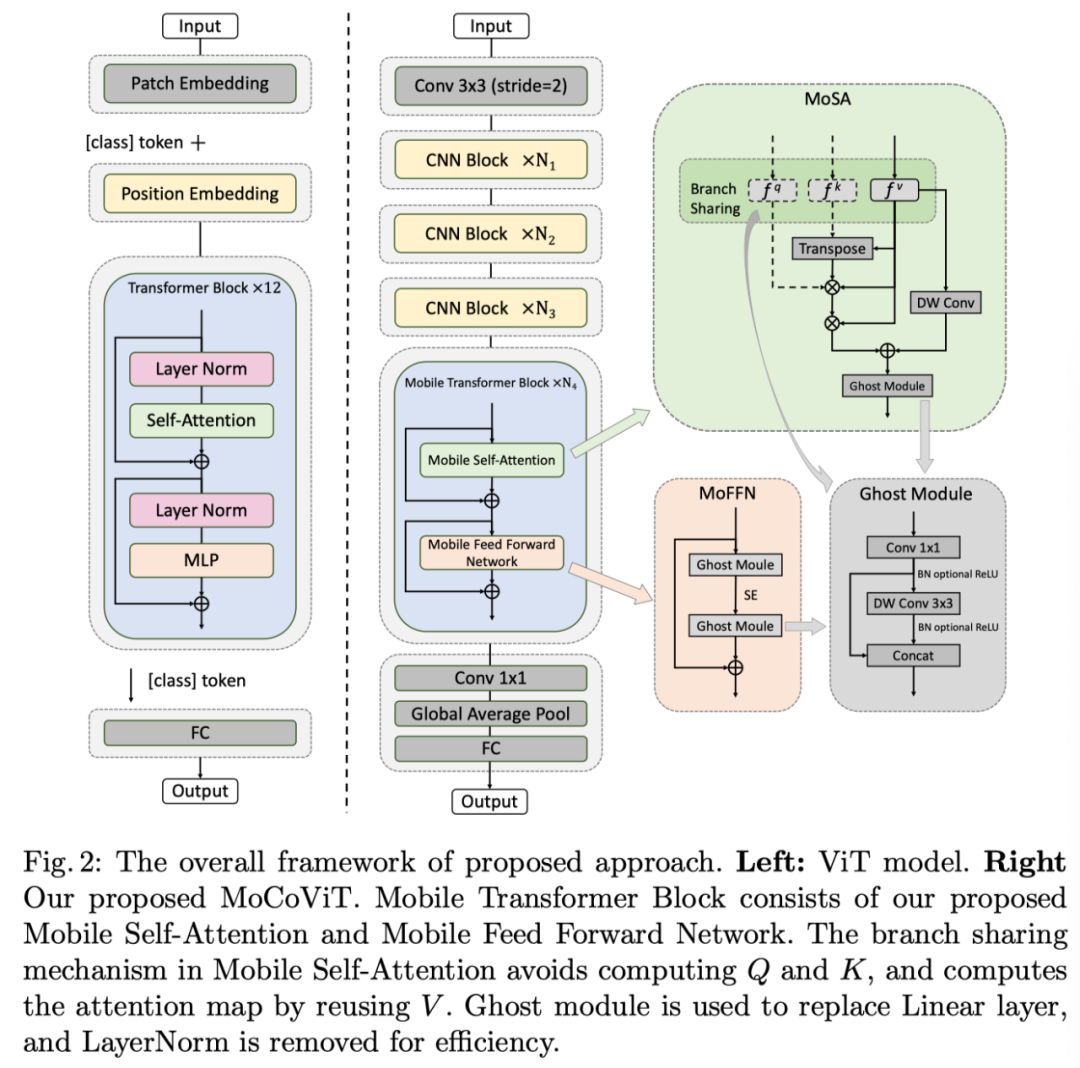
与最近有关vision transformer的工作不同,MoCoViT中的mobile transformer模块是为移动设备精心设计的,非常轻量级,通过两个主要修改完成:移动自注意力(Mobile Self-Attention,MoSA)模块和移动前馈网络(Mobile Feed Forward Network,MoFFN)。MoSA通过分支共享方案简化了attention map的计算,而MoFFN则作为transformer中MLP的移动版本,进一步大幅度减少了计算量。
综合实验证明,作者提出的MoCoViT系列在各种视觉任务上优于SOTA的便携式CNN和transformer神经架构。在ImageNet分类中,它在147M次浮点运算时达到了74.5%的Top-1精度,比MobileNetV3在计算量更少的情况下提高了1.2%。在COCO目标检测任务上,MoCoViT在RetinaNet框架下的性能比GhostNet高出2.1 AP。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢