
【标题】Logic-based Reward Shaping for Multi-Agent Reinforcement Learning
【作者团队】Ingy ElSayed-Aly, Lu Feng
【发表日期】2022.6.17
【论文链接】https://arxiv.org/pdf/2206.08881.pdf
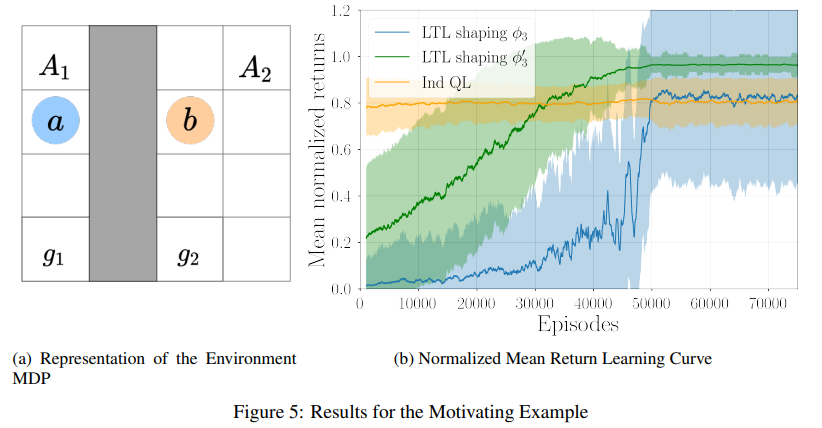
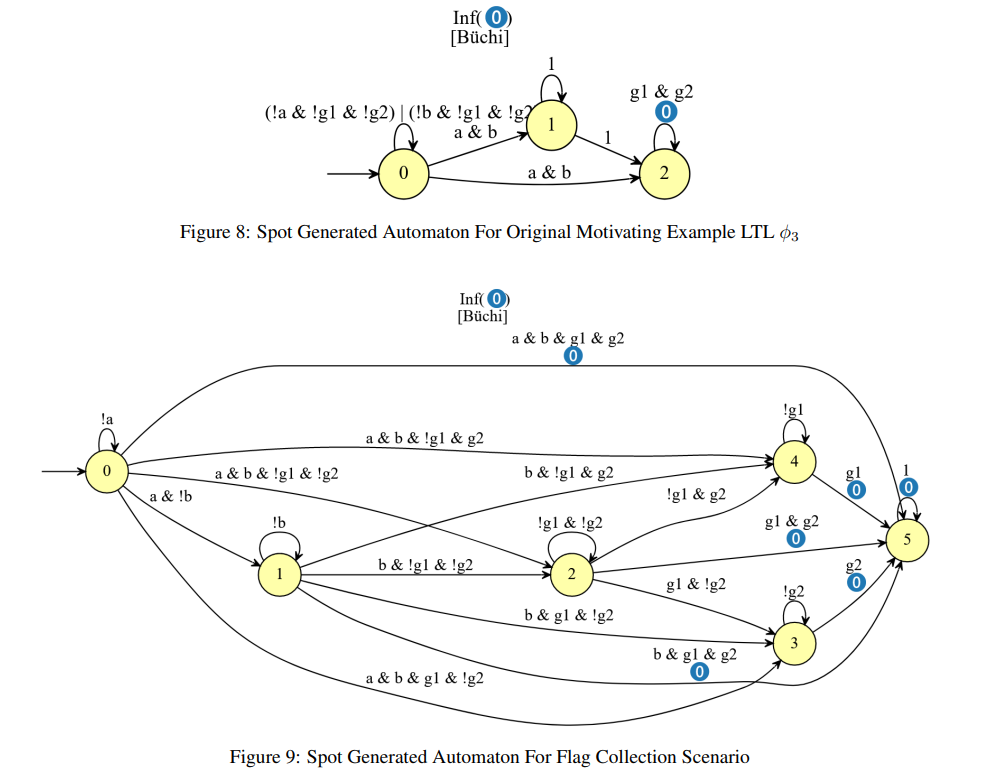
【推荐理由】强化学习 (RL) 在很大程度上依赖于探索来从环境中学习并最大化观察到的奖励。因此,必须设计一个奖励函数,以确保从收到的经验中获得最佳学习。先前的研究将基于自动机和逻辑的奖励塑造与环境假设相结合,以提供一种自动机制来根据任务合成奖励函数。然而,关于如何将基于逻辑的奖励形成扩展到多智能体强化学习 (MARL) 方面的工作还很有限。如果任务需要合作,环境将需要考虑联合状态以跟踪其他智能体,从而遭受与智能体数量相关的维度灾难。该项目探讨了如何为不同的场景和任务设计基于逻辑的 MARL 奖励形成。本文提出了一种新颖的基于半集中式逻辑的 MARL 奖励形成方法,该方法在智能体数量上具有可扩展性,并在多个场景中对其进行评估。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢