
本文分享 CVPR 2022 论文『Cross-Architecture Self-supervised Video Representation Learning』,提出问题:不同网络结构的特征也能进行对比学习?并由蚂蚁&美团&南大&阿里提出跨架构自监督视频表示学习方法CACL,在视频检索和动作识别任务上SOTA!

论文链接:
https://arxiv.org/abs/2205.13313
项目链接:
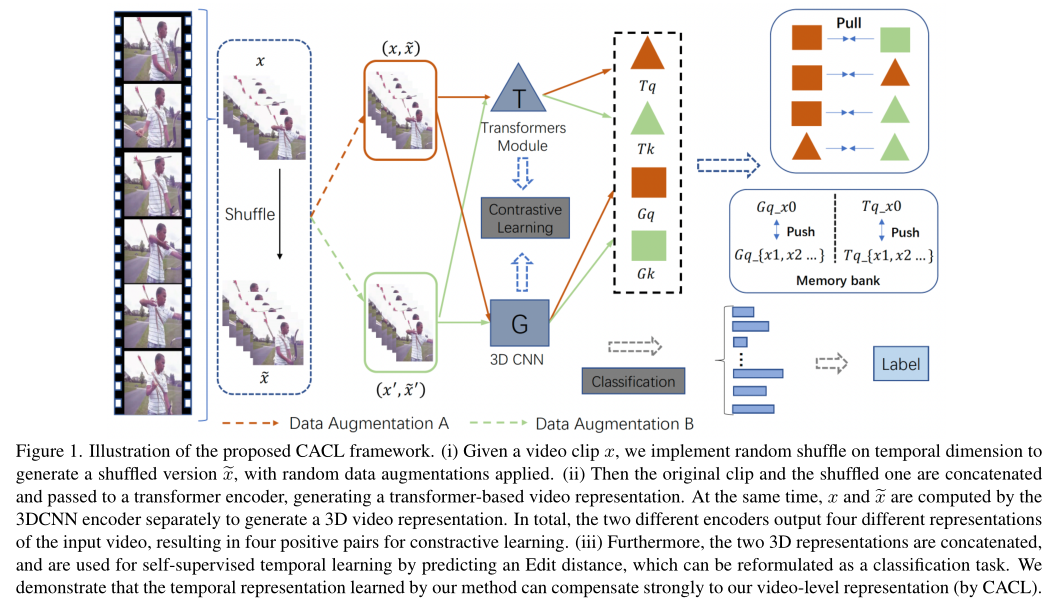
在本文中,作者提出了一种新的用于自监督视频表示学习的跨架构对比学习(cross-architecture contrastive learning,CACL)框架。CACL由一个3D CNN和一个视频Transformer组成,它们被并行使用以生成用于对比学习的各种正对。这使得模型能够从这些不同但有意义的对中学习强表示。
此外,作者引入了一个时间自监督学习模块,该模块能够按照时间顺序显式预测两个视频序列之间的编辑距离,这使得模型能够学习丰富的时间表示。作者对本文的方法在UCF101和HMDB51数据集上的视频检索和动作识别任务进行了评估,结果表明本文的方法取得了优异的性能,大大超过了Video MoCo和MoCo+BE等最先进的方法。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢