

论文地址:
https://arxiv.org/abs/2206.04674
构建一个如人脑一样的能同时处理所有任务的“通才”模型一直是AI领域研究员追求的目标。近来已有多个通才模型被相继提出,如商汤提出的Uni-Perceiver、阿里提出的OFA、Deepmind提出的Gato等。通过将所有任务都建模成一个统一的范式,并在多任务大规模预训练之后,通才模型不仅仅可以使用同一套模型权重同时完成多个不同的任务,还能够在不引入任何新参数时在全新任务上进行零样本推理。
尽管通才模型在模型通用性方面已经取得了长足进步,但是相较于特定于任务而设计的算法模型,通才模型往往在一些任务上有着性能下降的现象。本论文发现通才模型共享参数在优化不同任务时由于任务干扰可能存在不同的优化梯度方向,这种优化过程中梯度的不一致性将会导致参数更新的方向相较于每个任务的最优方向来说都是不确定的,从而使得网络最终性能的下降。
本篇论文旨在于消除通才模型优化过程中存在的任务干扰问题,从而提升模型在下游任务上的性能表现。一个很自然的解决办法是在不同任务间使用独立的参数 (下图),但是这种特定于任务的设计将会破坏通才模型的通用性。本篇论文选择了使用Mixture of Experts (MoE)来解决通才模型中的任务干扰。MoE是一种依赖于当前输入的条件计算方式,可以在不引入任何特定任务设计的前提下让网络自适应地稀疏激活部分子网络,从而为解决共享参数中的任务干扰提供了新思路。除此之外本论文还探讨了MoE如何选择有效的信息可靠激活子网络,从而在保持一个高效的计算效率的同时维持通才模型在新任务上的泛化能力。
为了消除通才模型中的任务干扰,本论文将MoE应用到了通才模型Uni-Perceiver中(表示为Uni-Perceiver-MoE)。实验结果发现MoE能够在引入较小的计算成本时有效去除通才模型中的任务干扰。在多数下游任务中,Uni-Perceiver-MoE表现出了极为理想的效果,仅使用1%的数据进行prompt tuning即能达到SOTA性能。此外,Uni-Perceiver-MoE在从未见过的新任务上面仍然保持着不错的zero-shot推理能力。图1和图2可视化了Uni-Perceiver-MoE稀疏激活情况。
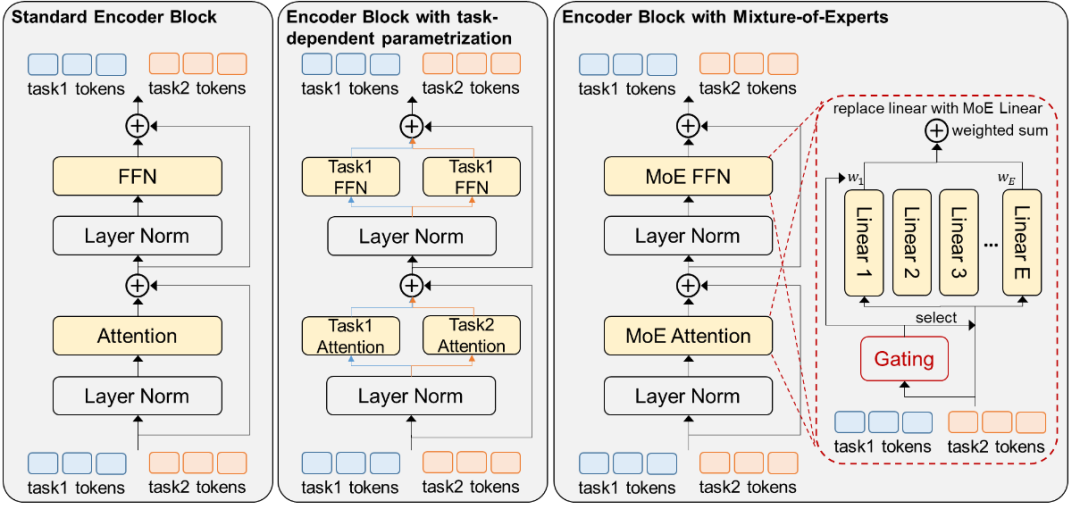 在通才模型Uni-Perceiver中引入MoE
在通才模型Uni-Perceiver中引入MoE
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢