
在神经网络结构设计中,我们经常会引入一些先验知识,比如ResNet的残差结构。然而我们还是用常规的优化器去训练网络。在本工作中,我们提出将先验信息用于修改梯度数值,称为梯度重参数化,对应的优化器称为RepOptimizer。我们着重关注VGG式的直筒模型,训练得到RepOptVGG模型,他有着高训练效率,简单直接的结构和极快的推理速度。

论文链接:https://arxiv.org/abs/2205.15242
官方仓库:https://github.com/DingXiaoH/RepOptimizers
与RepVGG的区别
- RepVGG加入了结构先验(如1x1,identity分支),并使用常规优化器训练。而RepOptVGG则是将这种先验知识加入到优化器实现中
- 尽管RepVGG在推理阶段可以把各分支融合,成为一个直筒模型。但是其训练过程中有着多条分支,需要更多显存和训练时间。而RepOptVGG可是 真-直筒模型,从训练过程中就是一个VGG结构
- 我们通过定制优化器,实现了结构重参数化和梯度重参数化的等价变换,这种变换是通用的,可以拓展到更多模型
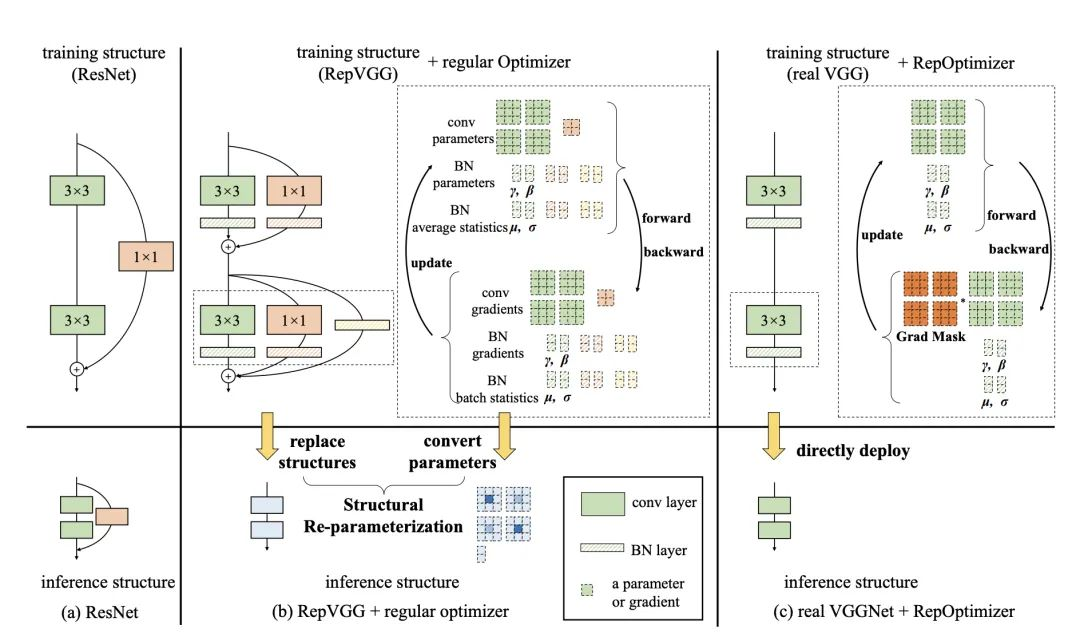
将结构先验知识引入优化器
我们注意到一个现象,在特殊情况下,每个分支包含一个线性可训练参数,加一个常量缩放值,只要该缩放值设置合理,则模型性能依旧会很高。我们将这个网络块称为Constant-Scale Linear Addition(CSLA)我们先从一个简单的CSLA示例入手,考虑一个输入,经过2个卷积分支+线性缩放,并加到一个输出中,我们考虑等价变换到一个分支内,那等价变换对应2个规则:
初始化规则
融合的权重需为:
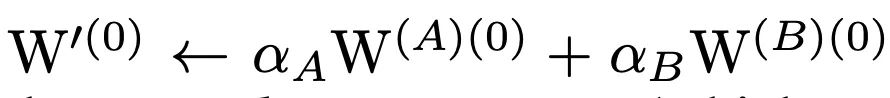
更新规则
针对融合后的权重,其更新规则为:
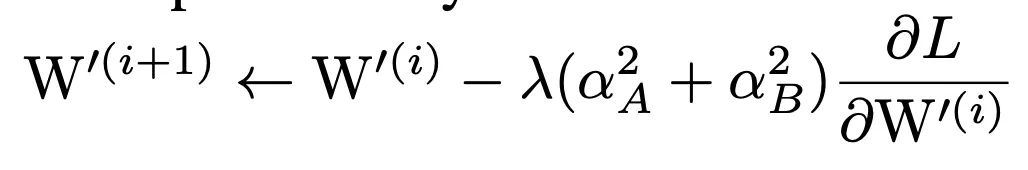
这部分公式可以参考附录A中,里面有详细的推导一个简单的示例代码为:
import torch
import numpy as np
np.random.seed(0)
np_x = np.random.randn(1, 1, 5, 5).astype(np.float32)
np_w1 = np.random.randn(1, 1, 3, 3).astype(np.float32)
np_w2 = np.random.randn(1, 1, 3, 3).astype(np.float32)
alpha1 = 1.0
alpha2 = 1.0
lr = 0.1
conv1 = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
conv2 = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
conv1.weight.data = torch.nn.Parameter(torch.tensor(np_w1))
conv2.weight.data = torch.nn.Parameter(torch.tensor(np_w2))
torch_x = torch.tensor(np_x, requires_grad=True)
out = alpha1 * conv1(torch_x) + alpha2 * conv2(torch_x)
loss = out.sum()
loss.backward()
torch_w1_updated = conv1.weight.detach().numpy() - conv1.weight.grad.numpy() * lr
torch_w2_updated = conv2.weight.detach().numpy() - conv2.weight.grad.numpy() * lr
print(torch_w1_updated + torch_w2_updated)
import torch
import numpy as np
np.random.seed(0)
np_x = np.random.randn(1, 1, 5, 5).astype(np.float32)
np_w1 = np.random.randn(1, 1, 3, 3).astype(np.float32)
np_w2 = np.random.randn(1, 1, 3, 3).astype(np.float32)
alpha1 = 1.0
alpha2 = 1.0
lr = 0.1
fused_conv = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
fused_conv.weight.data = torch.nn.Parameter(torch.tensor(alpha1 * np_w1 + alpha2 * np_w2))
torch_x = torch.tensor(np_x, requires_grad=True)
out = fused_conv(torch_x)
loss = out.sum()
loss.backward()
torch_fused_w_updated = fused_conv.weight.detach().numpy() - (alpha1**2 + alpha2**2) * fused_conv.weight.grad.numpy() * lr
print(torch_fused_w_updated)在RepOptVGG中,对应的CSLA块则是将RepVGG块中的3x3卷积,1x1卷积,bn层替换为带可学习缩放参数的3x3卷积,1x1卷积进一步拓展到多分支中,假设s,t分别是3x3卷积,1x1卷积的缩放系数,那么对应的更新规则为:

第一条公式对应输入通道==输出通道,此时一共有3个分支,分别是identity,conv3x3, conv1x1第二条公式对应输入通道!=输出通道,此时只有conv3x3, conv1x1两个分支第三条公式对应其他情况需要注意的是CSLA没有BN这种训练期间非线性算子(training-time nonlinearity),也没有非顺序性(non sequential)可训练参数。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢