本文提出的重构预训练(reStructured Pre-training,RST),不仅在各种 NLP 任务上表现亮眼,在高考英语上,也交出了一份满意的成绩。
我们存储数据的方式正在发生变化,从生物神经网络到人工神经网络,其实最常见的情况是使用大脑来存储数据。随着当今可用数据的不断增长,人们寻求用不同的外部设备存储数据,如硬盘驱动器或云存储。随着深度学习技术的兴起,另一种有前景的存储技术已经出现,它使用人工神经网络来存储数据中的信息。
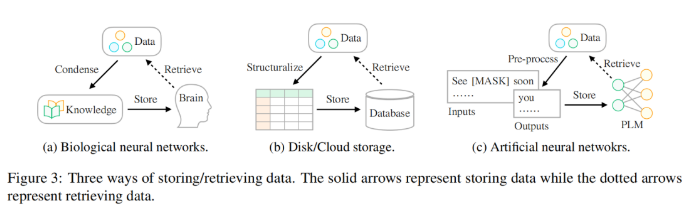
研究者认为,数据存储的最终目标是更好地服务于人类生活,数据的访问方式和存储方式同样重要。然而,存储和访问数据的方式存在差异。历史上,人们一直在努力弥补这一差距,以便更好地利用世界上存在的信息。如图 3 所示:
-
在生物神经网络(如人脑)方面,人类在很小的时候就接受了课程(即知识)教育,以便他们能够提取特定的数据来应对复杂多变的生活。
-
对于外部设备存储,人们通常按照某种模式(例如表格)对数据进行结构化,然后采用专门的语言(例如 SQL)从数据库中有效地检索所需的信息。
-
对于基于人工神经网络的存储,研究人员利用自监督学习存储来自大型语料库的数据(即预训练),然后将该网络用于各种下游任务(例如情绪分类)。
来自 CMU 的研究者提出了一种访问包含各种类型信息数据的新方法,这些信息可以作为指导模型进行参数优化的预训练信号。该研究以信号为单位结构化地表示数据。这类似于使用数据库对数据进行存储的场景:首先将它们构造成表或 JSON 格式,这样就可以通过专门的语言 (如 SQL) 准确地检索所需的信息。
此外,该研究认为有价值的信号丰富地存在于世界各类的数据中,而不是简单地存在于人工管理的监督数据集中, 研究人员需要做的是 (a) 识别数据 (b) 用统一的语言重组数据(c)将它们集成并存储到预训练语言模型中。该研究称这种学习范式为重构预训练(reStructured Pre-training,RST)。研究者将这个过程比作「矿山寻宝」。不同的数据源如维基百科,相当于盛产宝石的矿山。它们包含丰富的信息,比如来自超链接的命名实体,可以为模型预训练提供信号。一个好的预训练模型 (PLM) 应该清楚地了解数据中各种信号的组成,以便根据下游任务的不同需求提供准确的信息。
内容中包含的图片若涉及版权问题,请及时与我们联系删除



评论
沙发等你来抢