
作者:Tian Li,Xiang Chen,Zhen Dong等
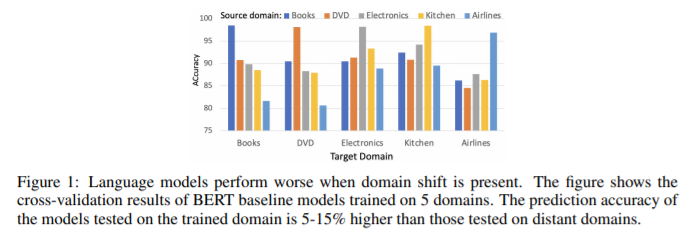
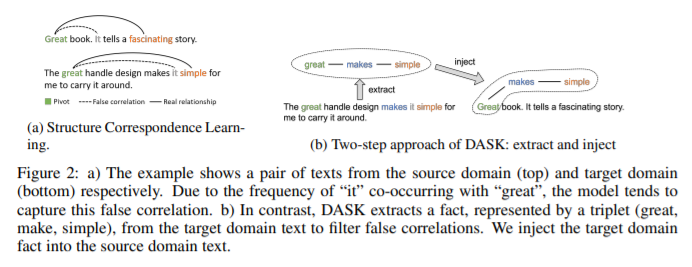
简介:领域自适应文本分类是大规模预训练的一个具有挑战性的问题语言模型,因为它们通常需要昂贵的附加标记数据来适应新领域。现有作品通常无法利用跨域单词之间的隐含关系。在本文中,作者提出了一种新方法,称为结构化知识域适应 (DASK),通过利用词级语义关系来增强域适应。DASK 首先构建一个知识图谱来捕获目标域中的主干词(与领域无关的词)和非主干词之间的关系。然后在训练期间,DASK 将与枢轴相关的知识图谱信息注入到源域文本中。对于下游任务,这些知识注入文本被输入到能够处理知识注入文本数据的 BERT 变体中。感谢知识注入,作者的模型根据与枢轴的关系为非枢轴学习域不变特征。DASK 在使用伪标签训练期间通过候选枢轴的极性分数动态推断,确保枢轴具有域不变的行为。作者在广泛的跨域情感分类任务上验证了 DASK,并观察到 20 个不同域对的基线绝对性能提升高达 2.9%。代码将在 https://github.com/hikaru-nara/DASK 上提供。
论文下载:https://arxiv.org/pdf/2206.09591.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢