
近日,智源“悟道”大模型项目——“悟道·文澜”团队论文“Towards Artificial General Intelligence via a Multimodal Foundation Model”登上 Nature 子刊《自然·通讯》。“悟道·文澜”团队由中国人民大学文继荣教授牵头。在论文中,团队不仅开发了一个相对资源节约以及方便部署的多模态基础模型,而且在模型可解释性方面进行了尝试。
具体而言,团队研究员通过“观察”人类大脑处理多模态信息的机制,提出文本与图片之间的弱语义相关假设,赋予了模型足够的想象能力和泛化能力,从而帮助人工智能应用快速有效应对各类认知任务。
据文章通讯作者、智源悟道团队成员卢志武教授介绍,这项工作对应“悟道·文澜”项目 BriVL 模型,已经在快手、华为、OPPO 等企业有落地方面的探索,具体应用包括“无障碍图像”、“视频剪辑”、“文生成国画”等。
“(纯粹)多模态工作登上 Nature 子刊,在业界尚属首次,这是‘悟道’大模型项目力争世界领先的努力成果,也是多模态迈向通用人工智能这一研究方向的重要进展。”对于该工作的意义,卢志武教授如此介绍。
论文介绍
以脑为鉴,结合情感与思考
用多模态迈向通用人工智能
近年来,深度学习在计算机视觉、自然语言处理等各种人工智能领域取得了许多重大突破,例如深度残差网络在图像分类方面的表现超越人类,语言模型 RoBERTa 在 GLUE 基准测试上取得优越的成绩。但是,目前大多数的人工智能工作还是只局限于单个认知能力的习得。
为了克服这些局限并向通用人工智能迈出一步,“悟道·文澜”团队开发了一个多模态预训练模型,在海量的多模态数据上进行自监督训练,并把它命名为 BriVL(Bridging-Vision-and-Language),期望打通人工智能众多认知能力之间桎梏,从而应对多种下游认知任务带来的挑战。
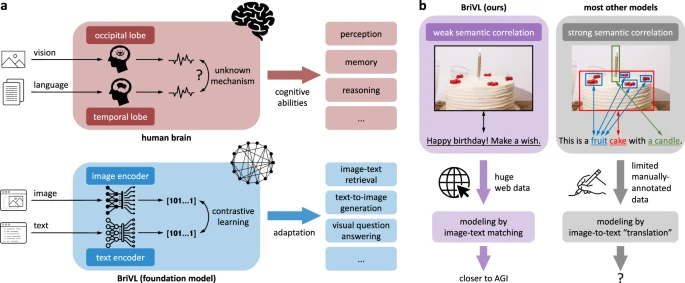
团队发现当前主流多模态模型总是假设文本与图像之间是强语义相关关系,但这种“观察”不符合现实世界,也会导致模型丢失人们在为图片配文时暗含的复杂情感和思考。因此,在论文中,研究员们提出训练数据中的图片与文本应遵循弱语义相关假设,借鉴人类大脑处理多模态信息的机制,提高模型泛化能力。
“脑机制”加持下的 BriVL 获得了强大的高级语义概念的想象能力,例如:
输入抽象化单词:自然、时间、科学、梦境。输出结果表明模型具有把抽象概念概括为一系列具体物体的能力。

输入抽象化句子,输出结果如下所示,无论是寓意,还是古诗意境, BriVL 都能很好地理解它们。

上面几幅图,是BriVL 的神经网络可视化结果,为了提高模型解释性,团队利用 VQGAN 在 BriVL 的指导下来生成图像,例如:
输入:自然、冲浪、冬日的校园、乌云背后有阳光。输出:

提高难度,输入连贯的句子。输出结果如下图,虽然每张图片都是独立生成的,但四张图片在视觉上是连贯的,且风格一致。

弱语义相关数据上预训练的 BriVL 还可以对人类很少见到的概念/ 场景(如“熊熊燃烧的大海” 和“发光的森林”)甚至世界上不存在的场景(如“赛博朋克风格的城市”和“月球上的宫殿”)进行生成,这也证明了 BriVL 的优越性能不是来自于对预训练数据的过拟合 :



BriVL 使文澜模型对文本/图像信息的理解不仅局限于“等价”关联,而是进一步扩展到了“场景”关联、“因果”关联等。这也说明,以多模态为核心的预训练模型“悟道·文澜”,在语义理解、视觉-语言检索方面的创新达到了业界领先水平。
目前,“悟道·文澜”模型已经进化到3.0,聚焦于视频-文本预训练模型,并探索实际应用场景的落地。模型将在过往图文预训练的基础上,确保模型设计能够自动适应视频场景,使得“悟道·文澜”模型更通用,赋能更多产业领域。
未来,基于团队对多模态科研的理解,“悟道·文澜”项目将在人工智能研发上从顶天和立地两个方面发力,深入研究多模态预训练模型的可解释性,同时探索通用人工智能的实现路径。





内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢