
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:让多智能体学习更接近真实世界的可扩展(无人)驾驶基准、面向内容丰富文本到图像生成的扩展自回归模型、网络博弈结构推断学习、要训练稠密篇章检索器有问题就够了、重构式预训练、视觉-语言表示学习中在编码器间搭设桥梁、时间一致语义视频编辑、面向无锚和基于锚检测器的半监督目标检测、基础模型能谈论因果吗
1、[LG] Nocturne: a scalable driving benchmark for bringing multi-agent learning one step closer to the real world
E Vinitsky, N Lichtlé, X Yang, B Amos, J Foerster
[Meta AI & UC Berkeley & Univeristy of Oxford]
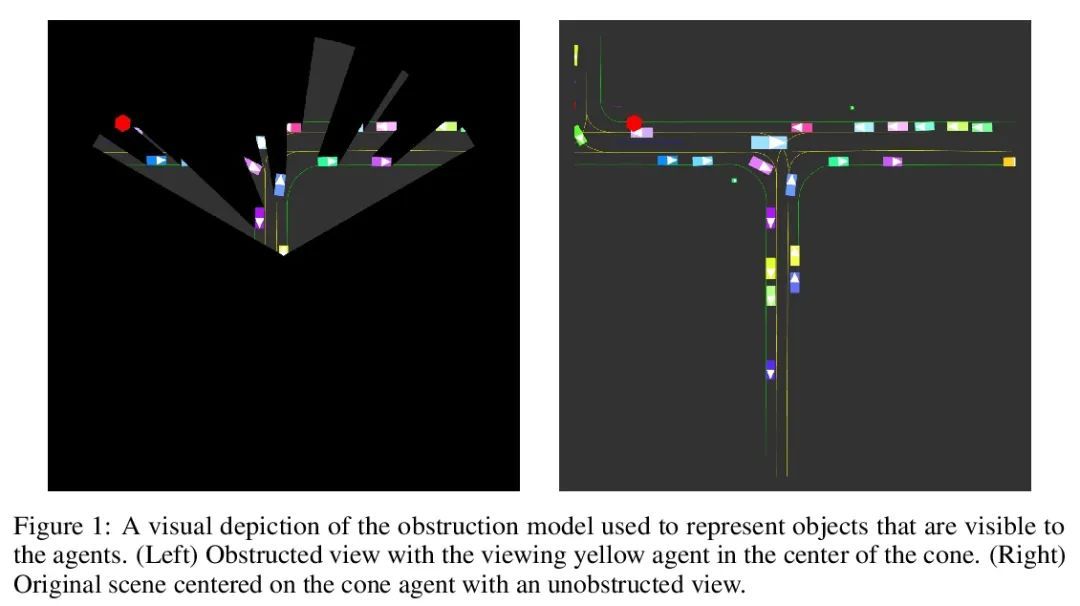
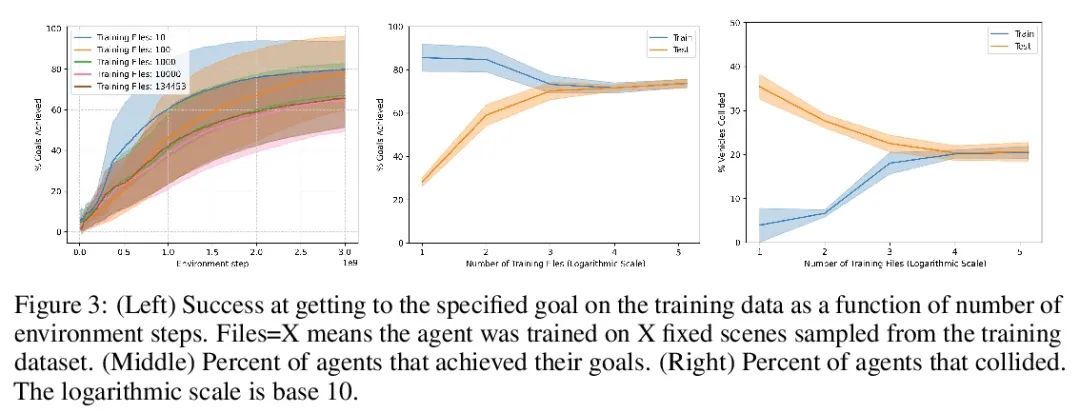
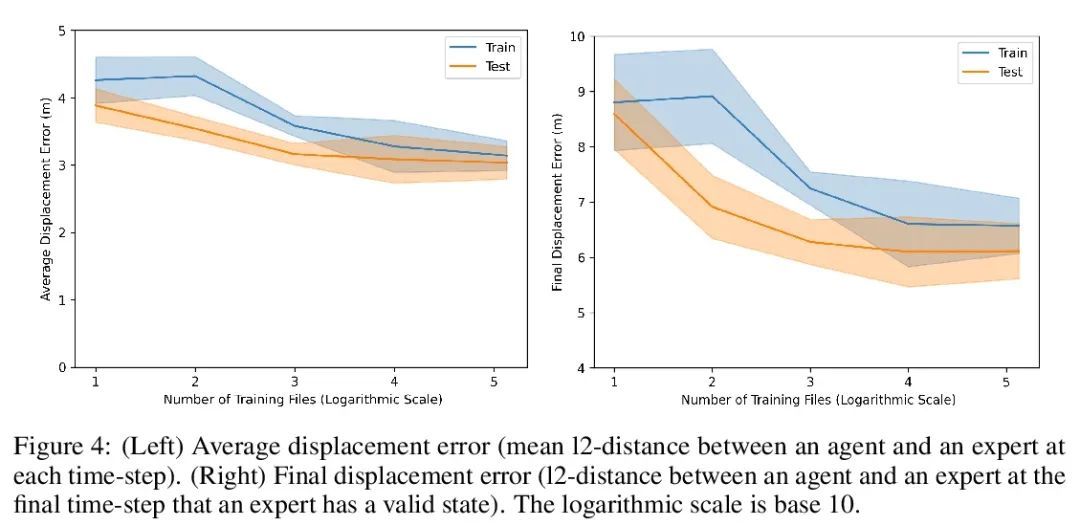
Nocturne:让多智能体学习更接近真实世界的可扩展(无人)驾驶基准。本文介绍了Nocturne,一种新的2D驾驶模拟器,用于研究部分可观察的多智能体去中心化协调。Nocturne的重点,是在没有计算机视觉和图像特征提取的计算开销的情况下,在现实世界的多智能体环境中实现推理和心智理论的研究。该模拟器中的智能体只观察场景的遮挡视图,模仿人类的视觉感应限制。与现有基准不同,Nocturne使用高效的交叉方法来计算C++后端可见特征的矢量集,使模拟器能够以每秒2000多步的速度运行。利用开源的轨迹和地图数据,构建了一个模拟器,来加载和重放真实世界驾驶数据中的任意轨迹和场景。利用这个环境,本文对强化学习和模仿学习的智能体进行了基准测试,并证明这些智能体与人类水平的协调能力相差甚远,并明显偏离专家的轨迹。
We introduce Nocturne, a new 2D driving simulator for investigating multi-agent coordination under partial observability. The focus of Nocturne is to enable research into inference and theory of mind in real-world multi-agent settings without the computational overhead of computer vision and feature extraction from images. Agents in this simulator only observe an obstructed view of the scene, mimicking human visual sensing constraints. Unlike existing benchmarks that are bottlenecked by rendering human-like observations directly using a camera input, Nocturne uses efficient intersection methods to compute a vectorized set of visible features in a C++ back-end, allowing the simulator to run at 2000+ steps-per-second. Using open-source trajectory and map data, we construct a simulator to load and replay arbitrary trajectories and scenes from real-world driving data. Using this environment, we benchmark reinforcement-learning and imitation-learning agents and demonstrate that the agents are quite far from human-level coordination ability and deviate significantly from the expert trajectories.
https://arxiv.org/abs/2206.09889


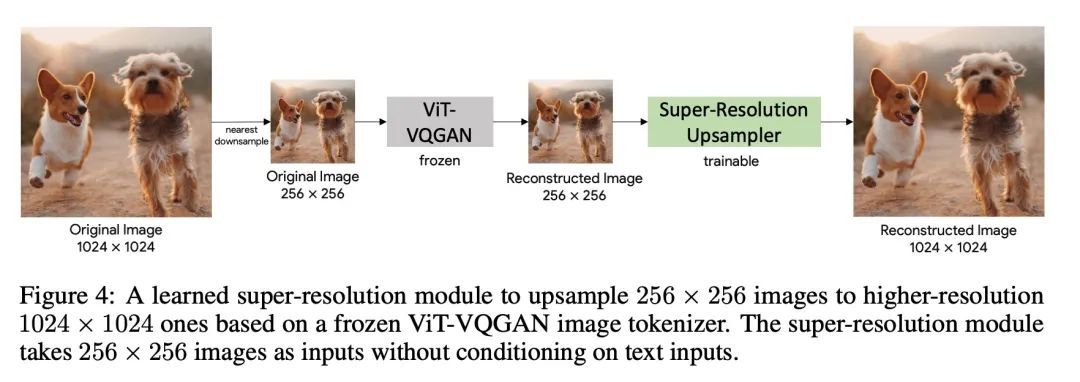
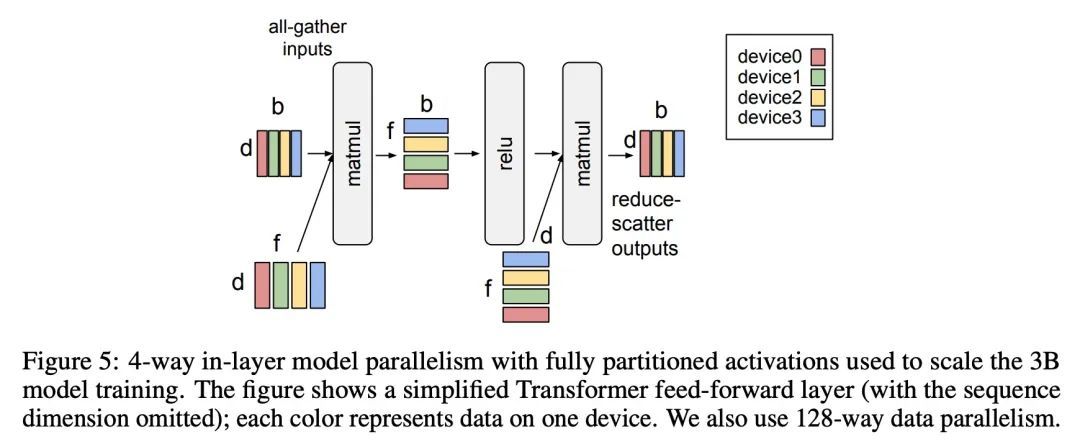
2、[LG] Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
J Yu, Y Xu, J Y Koh, T Luong, G Baid...
[Google Research]
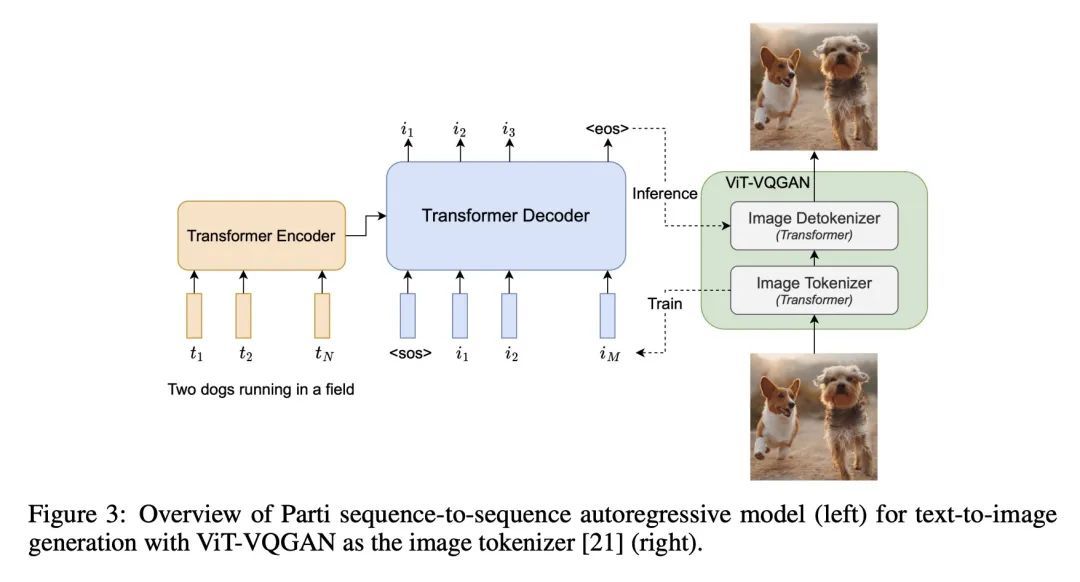
面向内容丰富文本到图像生成的扩展自回归模型。我们提出Pathways自回归文本-图像(Parti)模型,能生成高保真的逼真图像,并支持涉及复杂成分和世界知识的内容丰富的合成。Parti将文本到图像的生成视为一个序列到序列的建模问题,类似于机器翻译,将图像token的序列作为目标输出,而不是另一种语言的文本token。这种策略可以自然而然地利用之前关于大型语言模型的丰富工作,通过扩大数据和模型的规模,这些模型的能力和性能都有了持续的进步。方法很简单:首先,Parti用基于Transformer的图像标记器ViT-VQGAN,将图像编码为离散的token序列。通过将编码器-解码器Transformer模型扩展到20B的参数,实现了质量的持续改进,在MS-COCO上,新的最先进的零样本FID得分为7.23,微调FID得分为3.22。对Localized Narratives以及PartiPrompts(P2)——一个由1600多个英语提示语组成的新的整体基准——的详细分析,证明了Parti在各种类别和难度方面的有效性。本文还探讨并强调了所提出模型的局限性,以界定和示范进一步改进的关键重点领域。
We present the Pathways [1] Autoregressive Text-to-Image (Parti) model, which generates high-fidelity photorealistic images and supports content-rich synthesis involving complex compositions and world knowledge. Parti treats text-to-image generation as a sequence-to-sequence modeling problem, akin to machine translation, with sequences of image tokens as the target outputs rather than text tokens in another language. This strategy can naturally tap into the rich body of prior work on large language models, which have seen continued advances in capabilities and performance through scaling data and model sizes. Our approach is simple: First, Parti uses a Transformer-based image tokenizer, ViT-VQGAN, to encode images as sequences of discrete tokens. Second, we achieve consistent quality improvements by scaling the encoder-decoder Transformer model up to 20B parameters, with a new state-of-the-art zero-shot FID score of 7.23 and finetuned FID score of 3.22 on MS-COCO. Our detailed analysis on Localized Narratives as well as PartiPrompts (P2), a new holistic benchmark of over 1600 English prompts, demonstrate the effectiveness of Parti across a wide variety of categories and difficulty aspects. We also explore and highlight limitations of our models in order to define and exemplify key areas of focus for further improvements. See parti.research.google for high-resolution images.
https://gweb-research-parti.web.app/parti_paper.pdf


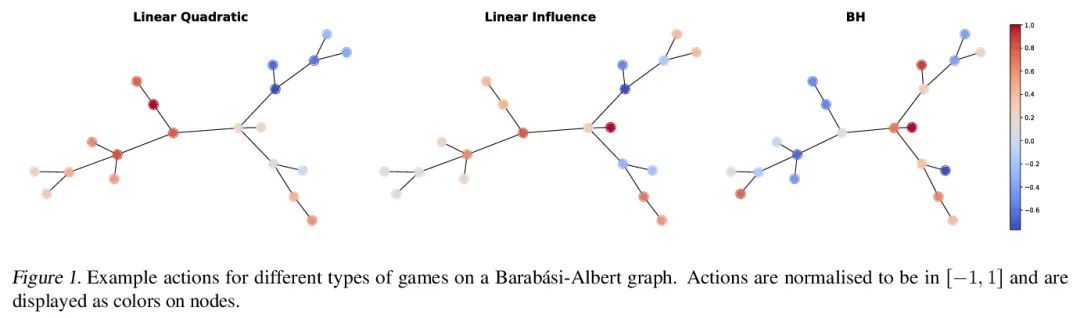
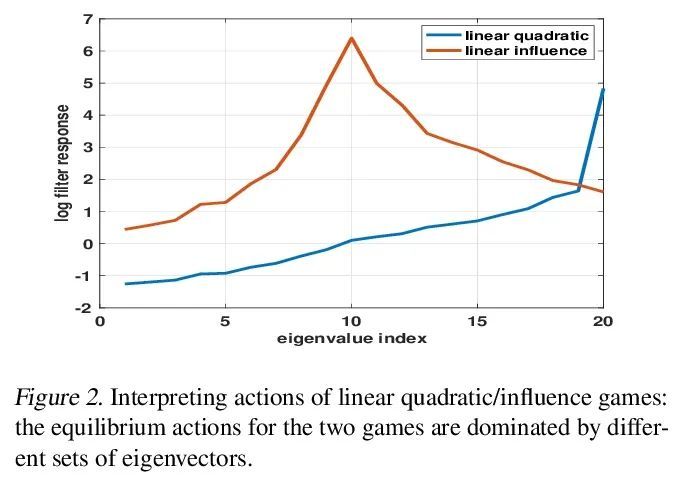
3、[LG] Learning to Infer Structures of Network Games
E Rossi, F Monti, Y Leng, M M. Bronstein, X Dong
[Twitter & The University of Texas at Austin & University of Oxford]
网络博弈结构推断学习。一组个人或组织之间的战略互动可以被模拟为在网络上进行的博弈,其中参与者的回报不仅取决于他们的行动,也取决于他们邻居的行动。从观察到的博弈结果(均衡行动)来推断网络结构是一个重要的问题,在经济学和社会科学中有许多潜在的应用。现有的方法大多需要了解与博弈相关的效用函数,这在现实世界的场景中往往是不现实的。本文采用一种类似于Transformer的结构,正确地解释了问题的对称性,并在不明确知道效用函数的情况下学习了从均衡行动到博弈网络结构的映射。在三种不同类型的网络博弈上使用合成和真实世界的数据测试了所提出的方法,证明了它在网络结构推断中的有效性和比现有方法更优越的性能。
Strategic interactions between a group of individuals or organisations can be modelled as games played on networks, where a player’s payoff depends not only on their actions but also on those of their neighbours. Inferring the network structure from observed game outcomes (equilibrium actions) is an important problem with numerous potential applications in economics and social sciences. Existing methods mostly require the knowledge of the utility function associated with the game, which is often unrealistic to obtain in real-world scenarios. We adopt a transformer-like architecture which correctly accounts for the symmetries of the problem and learns a mapping from the equilibrium actions to the network structure of the game without explicit knowledge of the utility function. We test our method on three different types of network games using both synthetic and real-world data, and demonstrate its effectiveness in network structure inference and superior performance over existing methods.
https://arxiv.org/abs/2206.08119

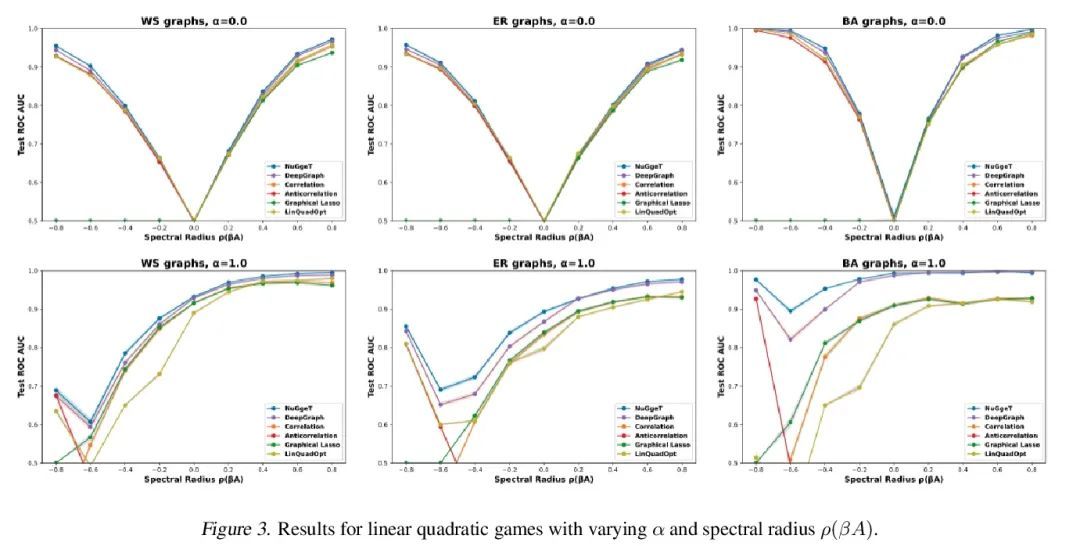
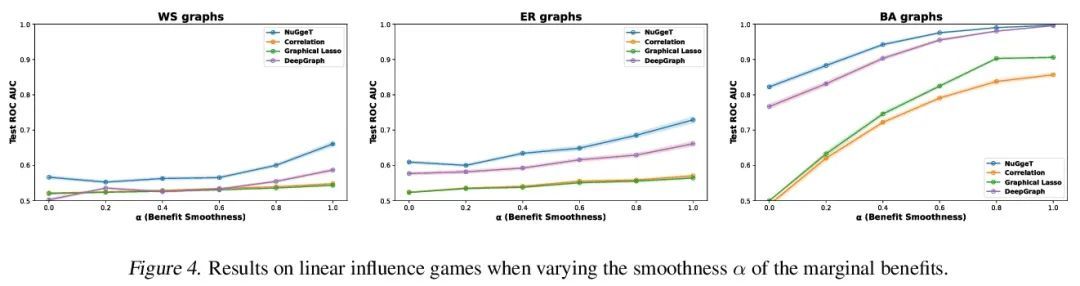
4、[CL] Questions Are All You Need to Train a Dense Passage Retriever
D S Sachan, M Lewis, D Yogatama, L Zettlemoyer, J Pineau, M Zaheer
[McGill University & Meta AI & Google DeepMind]
要训练稠密篇章检索器有问题就够了。本文提出ART,一种新的语料库级自动编码方法,用于训练稠密检索模型,不需要任何标注训练数据。稠密检索是开放域任务的一个核心挑战,例如开放式QA,最先进的方法往往需要大量的监督数据集,并对正样本进行自定义的硬负样本挖掘和去噪。相比之下,ART只需要访问未配对的输入和输出(例如,问题和潜在的答案文档)。采用一种新的文档检索自动编码方案,其中(1)输入问题用于检索一组证据文档,(2)用这些文档来计算重建原始问题的概率。基于问题重建的检索训练能够有效地对文档和问题编码器进行无监督学习,之后可以将其纳入完整的开放式QA系统,而不需要再进行任何微调。广泛的实验表明,ART在多个QA检索基准上获得了最先进的结果,只需从预训练的语言模型中进行通用初始化,就可以消除对标注数据和特定任务损失的需求。
We introduce ART, a new corpus-level autoencoding approach for training dense retrieval models that does not require any labeled training data. Dense retrieval is a central challenge for open-domain tasks, such as Open QA, where state-of-the-art methods typically require large supervised datasets with custom hard-negative mining and denoising of positive examples. ART, in contrast, only requires access to unpaired inputs and outputs (e.g. questions and potential answer documents). It uses a new document-retrieval autoencoding scheme, where (1) an input question is used to retrieve a set of evidence documents, and (2) the documents are then used to compute the probability of reconstructing the original question. Training for retrieval based on question reconstruction enables effective unsupervised learning of both document and question encoders, which can be later incorporated into complete Open QA systems without any further finetuning. Extensive experiments demonstrate that ART obtains state-of-the-art results on multiple QA retrieval benchmarks with only generic initialization from a pretrained language model, removing the need for labeled data and task-specific losses.
https://arxiv.org/abs/2206.10658

5、[CL] reStructured Pre-training
W Yuan, P Liu
[CMU]
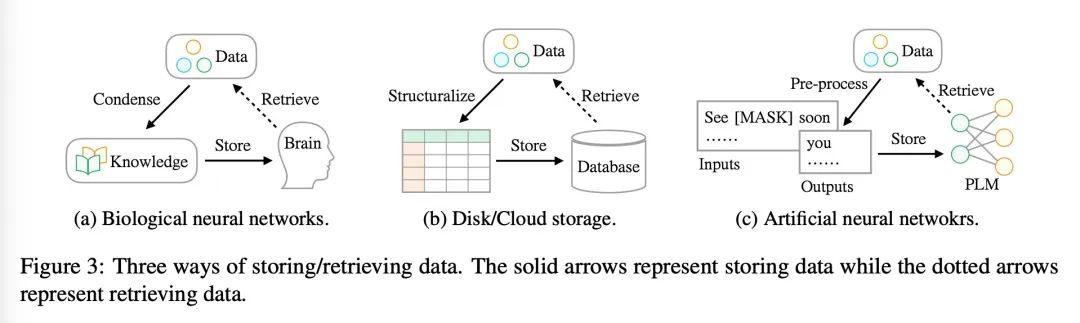
重构式预训练。本文试图破解过去几十年NLP技术发展的内部联系,寻找其本质,从而为NLP任务提供一种(潜在的)新的学习范式,称为重构式预训练(RST)。在这种范式中,数据的作用将被重新强调,模型的预训练和下游任务的微调被看作是一个数据存储和访问的过程。在此基础上,将一个简单的原则操作化,即一个好的存储机制不仅要有缓存大量数据的能力,还要考虑访问的便捷性。在克服了一些工程上的挑战后,本文通过对由各种有价值的信息组成的重组数据而不是原始数据进行预训练来实现这一目标。通过实验,RST模型不仅在各种NLP任务(如分类、信息抽取、事实检索、文本生成等)的52/55个流行数据集上超越了强大的竞争对手(如T0),而且在全国高考英语(Gaokao-English)中取得了优异的成绩。具体来说,所提出的系统Qin取得了比学生所做的平均分数高40分,用1/16的参数取得了比GPT3高15分的成绩。特别是,Qin在2018年英语考试(全国卷III)中获得了138.5的高分(满分150分)。通过在线提交平台发布了高考基准,其中包含了2018-2021年的十份有标注的英语试卷,到目前为止(并将每年扩展),这使得更多AI模型可以参加高考,为人类和AI竞争建立一个相对公平的测试平台,帮助我们更好地了解所处的位置。我们在最近(2022.06.08)的2022年高考英语中测试所提出模型,得到的总分是134分(GPT3得分为108分)。
In this work, we try to decipher the internal connection of NLP technology development in the past decades, searching for essence, which rewards us with a (potential) new learning paradigm for NLP tasks, dubbed as reStructured Pre-training (RST). In such a paradigm, the role of data will be re-emphasized, and model pre-training and fine-tuning of downstream tasks are viewed as a process of data storing and accessing. Based on that, we operationalize the simple principle that a good storage mechanism should not only have the ability to cache a large amount of data but also consider the ease of access. We achieve this by pre-training models over restructured data that consist of a variety of valuable information instead of raw data after overcoming several engineering challenges. Experimentally, RST models not only surpass strong competitors (e.g., T0) on 52/55 popular datasets from a variety of NLP tasks (e.g., classification, information extraction, fact retrieval, text generation, etc.) without fine-tuning on downstream tasks, but also achieve superior performance in National College Entrance Examination English (Gaokao-English), the most authoritative examination in China, which millions of students will attend every year. Specifically, the proposed system Qin achieves 40 points higher than the average scores made by students and 15 points higher than GPT3 with 1/16 parameters. In particular, Qin gets a high score of 138.5 (the full mark is 150) in the 2018 English exam (national paper III). We have released the Gaokao Benchmark with an online submission platform that contains ten annotated English papers from 2018-2021 so far (and will be expanded annually), which allows more AI models to attend Gaokao, establishing a relatively fair test bed for human and AI competition and helping us better understand where we are. In addition, we test our model in the 2022 College Entrance Examination English that happened a few days ago (2022.06.08), and it gets a total score of 134 (v.s. GPT3’s 108).
https://arxiv.org/abs/2206.11147

另外几篇值得关注的论文:
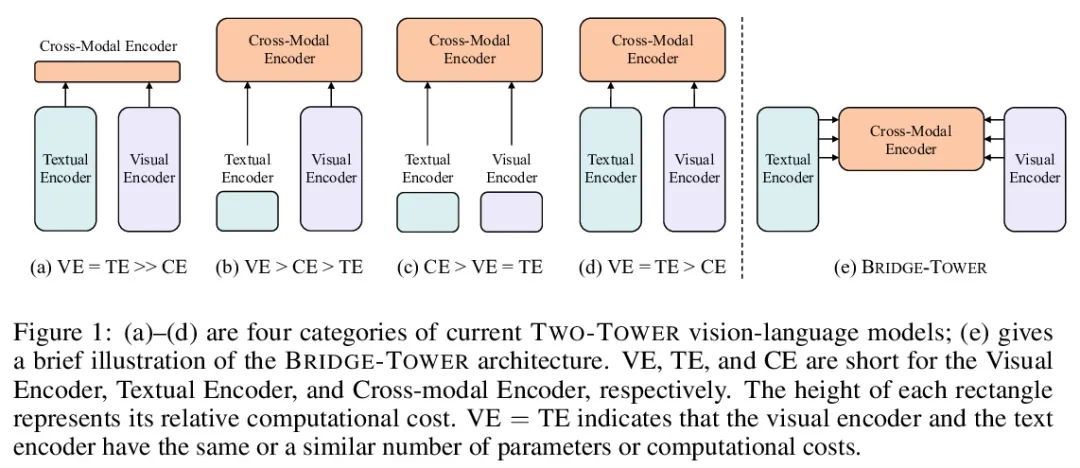
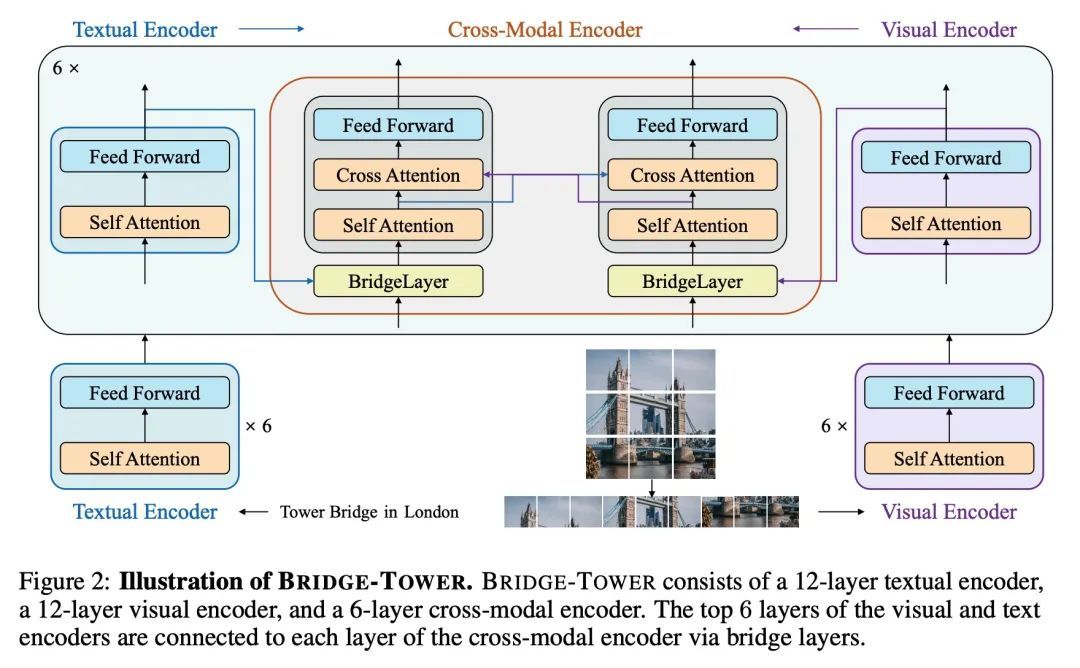
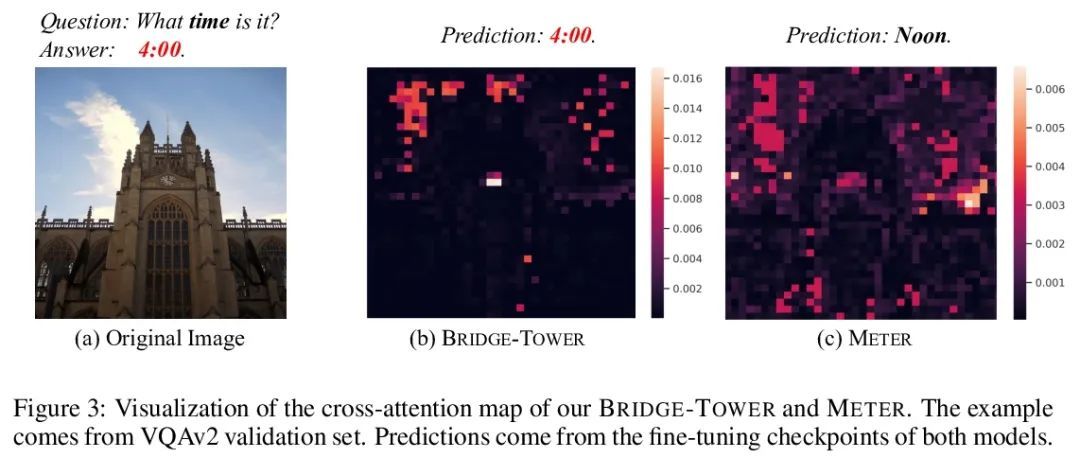
[CV] Bridge-Tower: Building Bridges Between Encoders in Vision-Language Representation Learning
Bridge-Tower:视觉-语言表示学习中在编码器间搭设桥梁
X Xu, C Wu, S Rosenman, V Lal, N Duan
[Microsoft Research Asia & Intel Labs]
https://arxiv.org/abs/2206.08657

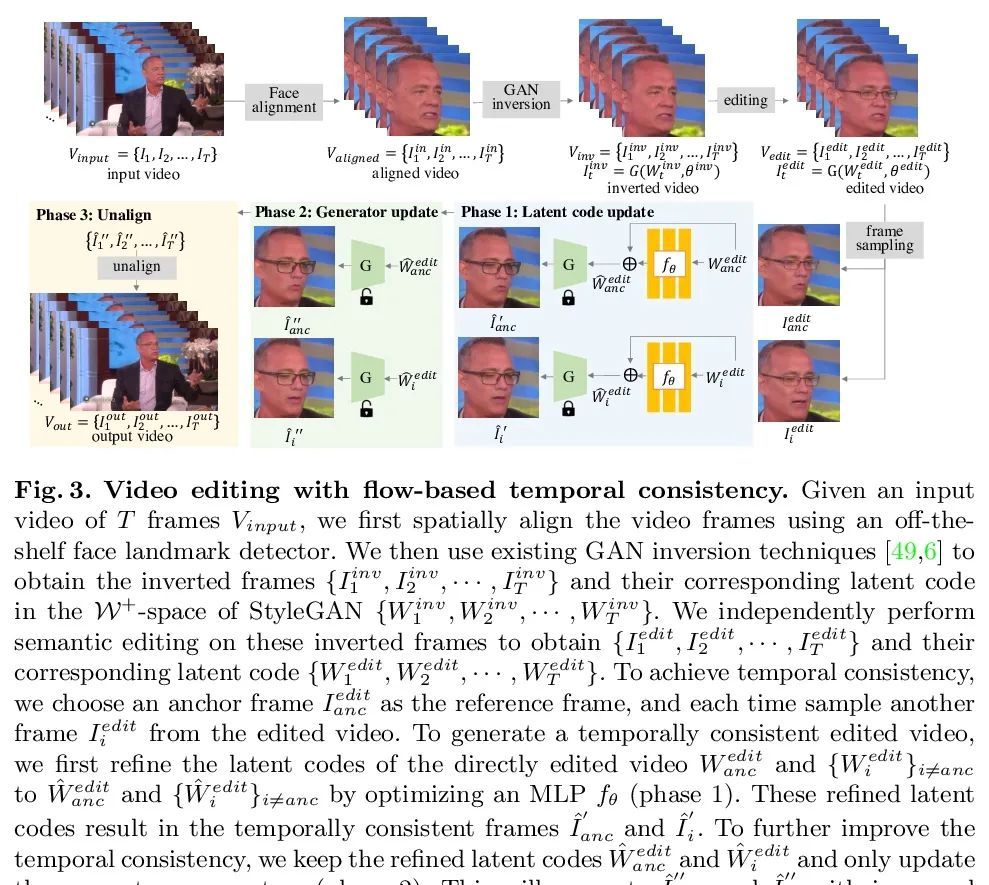
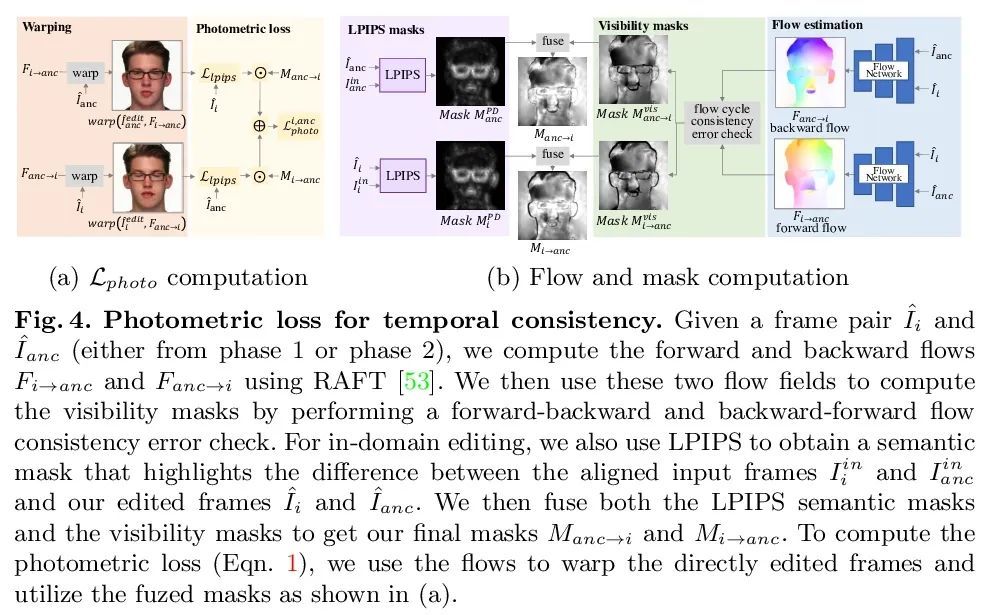
[CV] Temporally Consistent Semantic Video Editing
时间一致语义视频编辑
Y Xu, B AlBahar, J Huang
[University of Maryland & Virginia Tech]
https://arxiv.org/abs/2206.10590



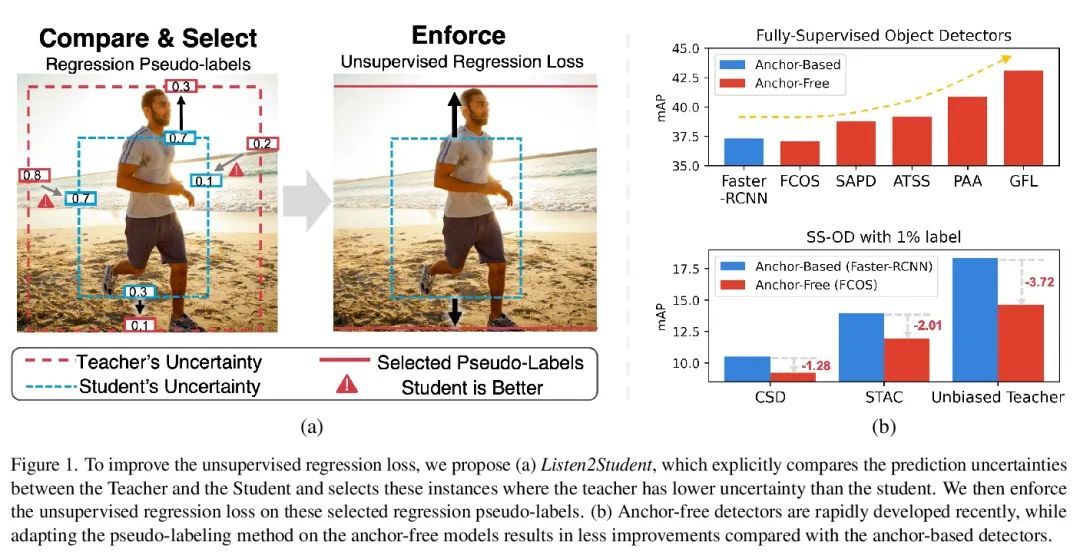
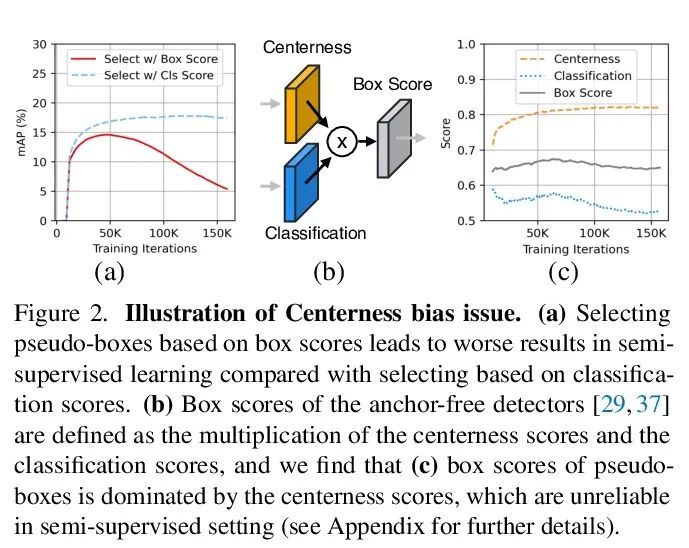
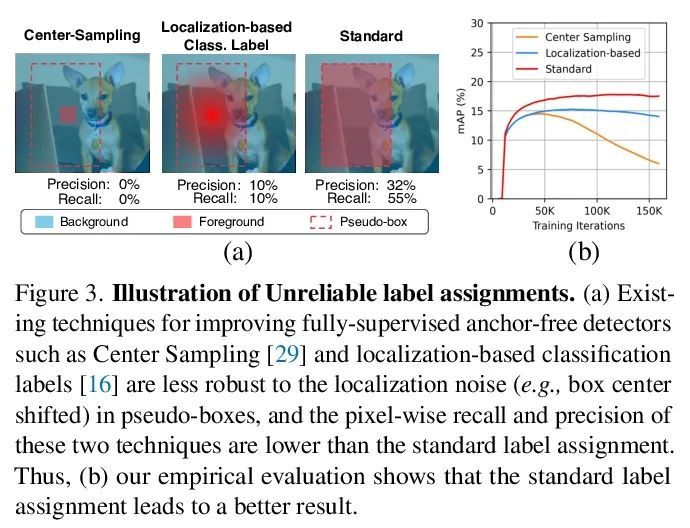
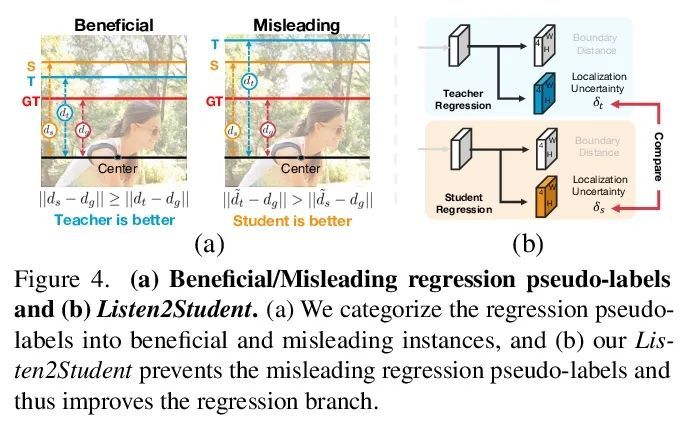
[CV] Unbiased Teacher v2: Semi-supervised Object Detection for Anchor-free and Anchor-based Detectors
Unbiased Teacher v2:面向无锚和基于锚检测器的半监督目标检测
Y Liu, C Ma, Z Kira
[Georgia Institute of Technology & Meta]
https://arxiv.org/abs/2206.09500

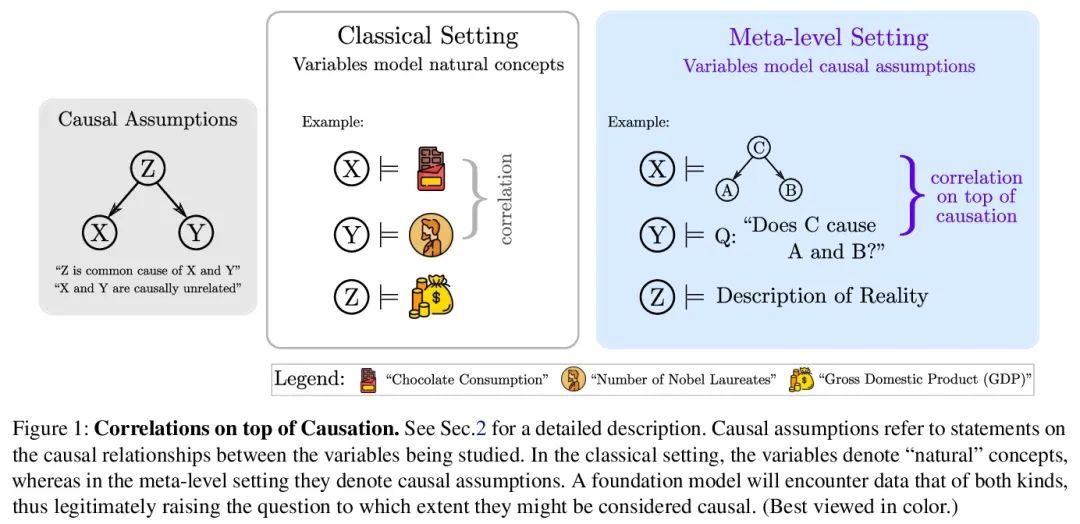
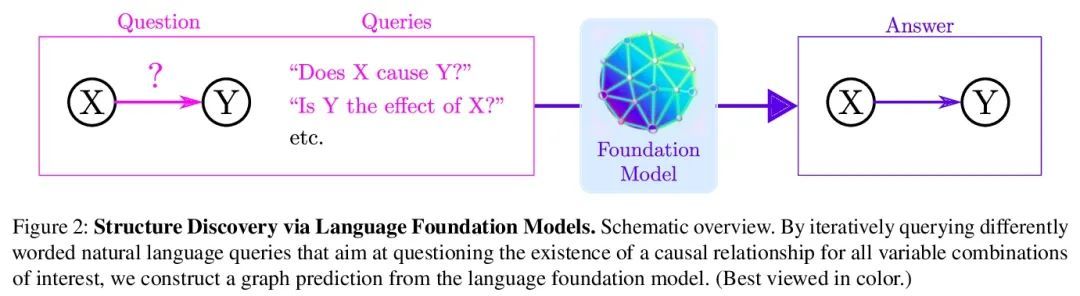
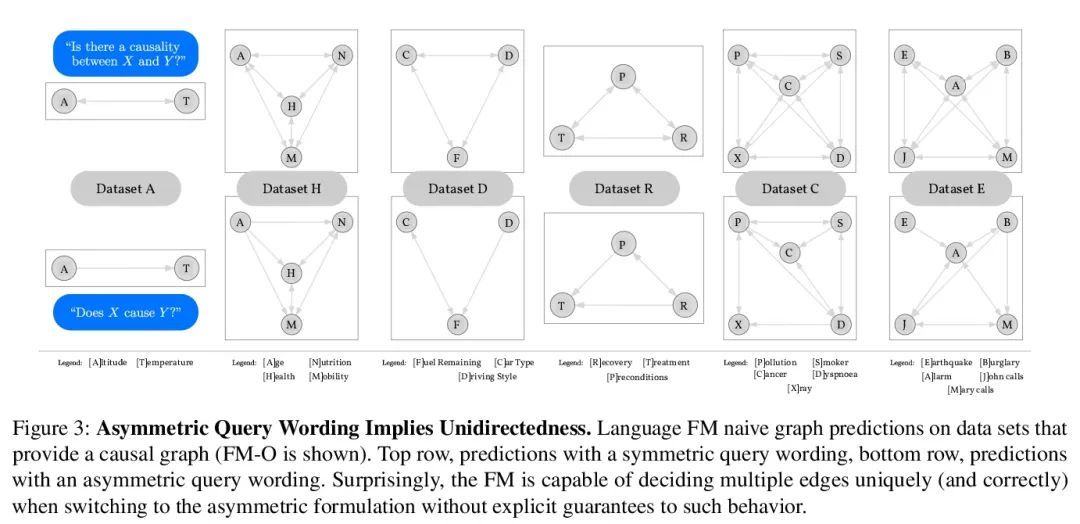
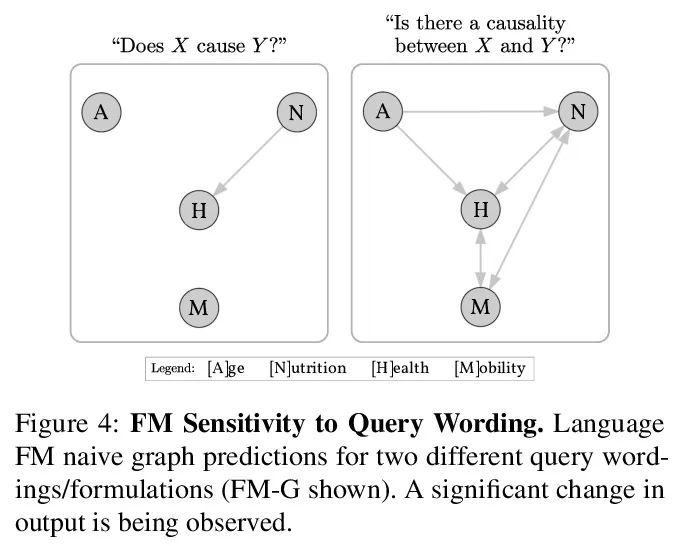
[CL] Can Foundation Models Talk Causality?
基础模型能谈论因果吗?
M Willig, M Zečević, D S Dhami, K Kersting
[TU Darmstadt]
https://arxiv.org/abs/2206.10591

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢