
二十一世纪,人类正面临着前所未有的环境和医疗挑战。为特定目的设计新型蛋白质的能力将有可能改变及时应对这些问题的能力。人工智能领域的最新进展正在为这一目标的实现创造条件。蛋白质序列在本质上类似于自然语言:氨基酸以多种组合方式排列,形成承载功能的结构,就像字母构成单词和句子承载意义一样。因此,在整个自然语言处理(NLP)的历史中,它的许多技术被应用于蛋白质研究问题,这并不令人惊讶。过去的几年里见证了NLP领域的革命性突破。Transformer预训练模型的实施使文本生成具有类似人类的能力,包括具有特定属性的文本,如风格或主题。受其在NLP任务中取得的巨大成功的激励,本文预计Transformer将在不久的将来主导自定义蛋白质序列的生成。对蛋白质家族的预训练模型进行微调,将使它们能够用新的序列来扩展它们的家族组库,这些序列可能是高度不同的,但仍有潜在的功能。控制标签的结合,如细胞区系或功能,将进一步使新型蛋白质功能的可控设计成为可能。此外,最近的模型可解释性方法将能够打开 "黑盒子",从而增强对折叠原理的理解。早期的举措显示了生成性语言模型在设计功能序列方面的巨大潜力。本文认为,使用生成性文本模型来创造新的蛋白质是一个很有前途的、在很大程度上未被开发的领域,并讨论了它对蛋白质设计可预见的影响。
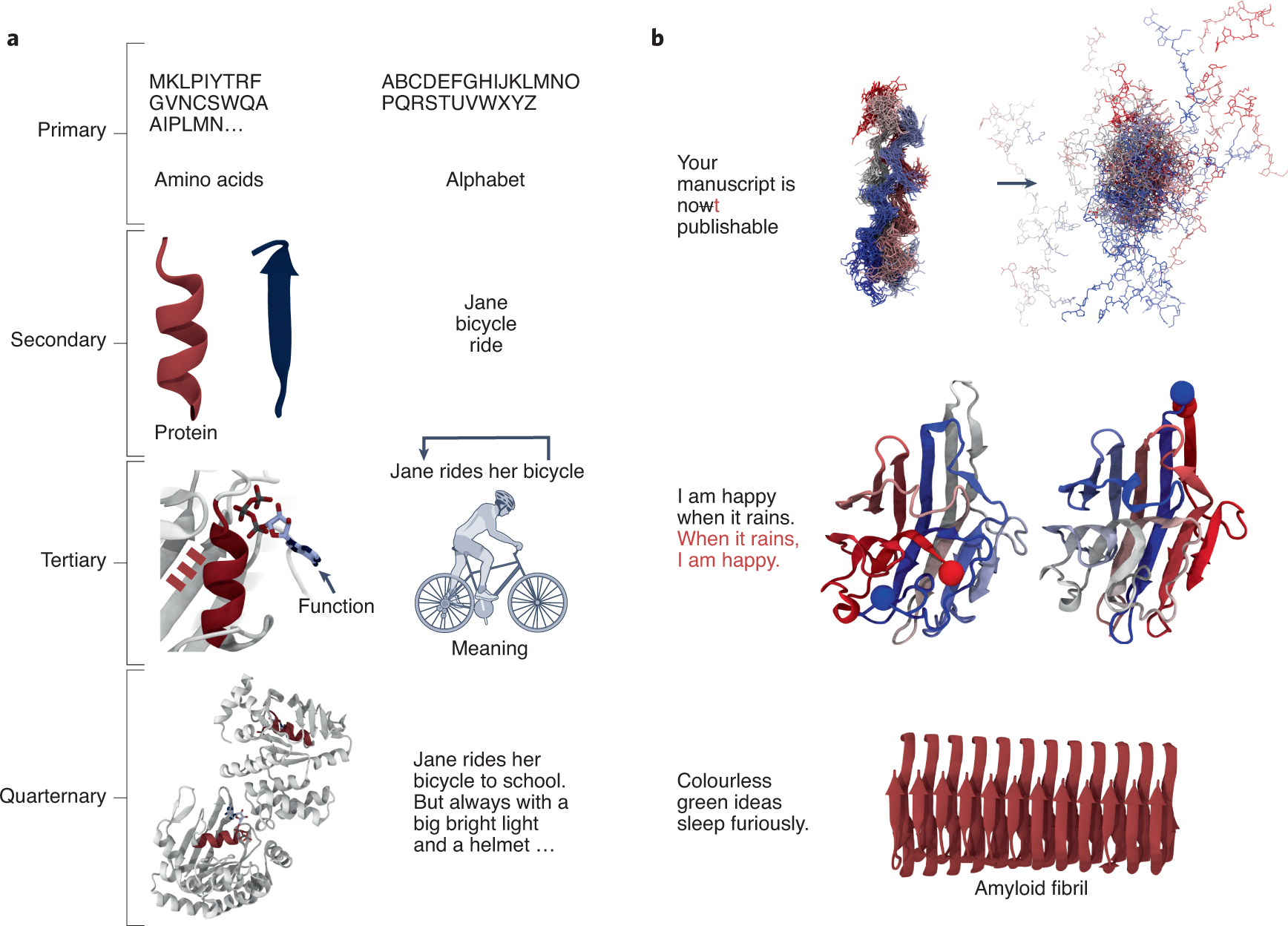 上图展示了语言和蛋白质的差异。
上图展示了语言和蛋白质的差异。
a, 蛋白质序列(初级结构)由其字母表中的字符串联表示:20个标准氨基酸。这些氨基酸形成三维二级结构元素,如α-螺旋和β-片,就像单词组合成承载意义的句子,排列形成承载功能的三级结构。蛋白质结构域进一步组装成更大的四级复合物,类似于句子构建文本。
b,语言和蛋白质之间的相似性跨越了其他例子。句子中的错误可能是致命的,就像蛋白质功能的错义突变。句子和序列可以被替换,保留它们的意义和功能,语法上正确的句子并不能保证逻辑意义,就像折叠结构不能保证功能。
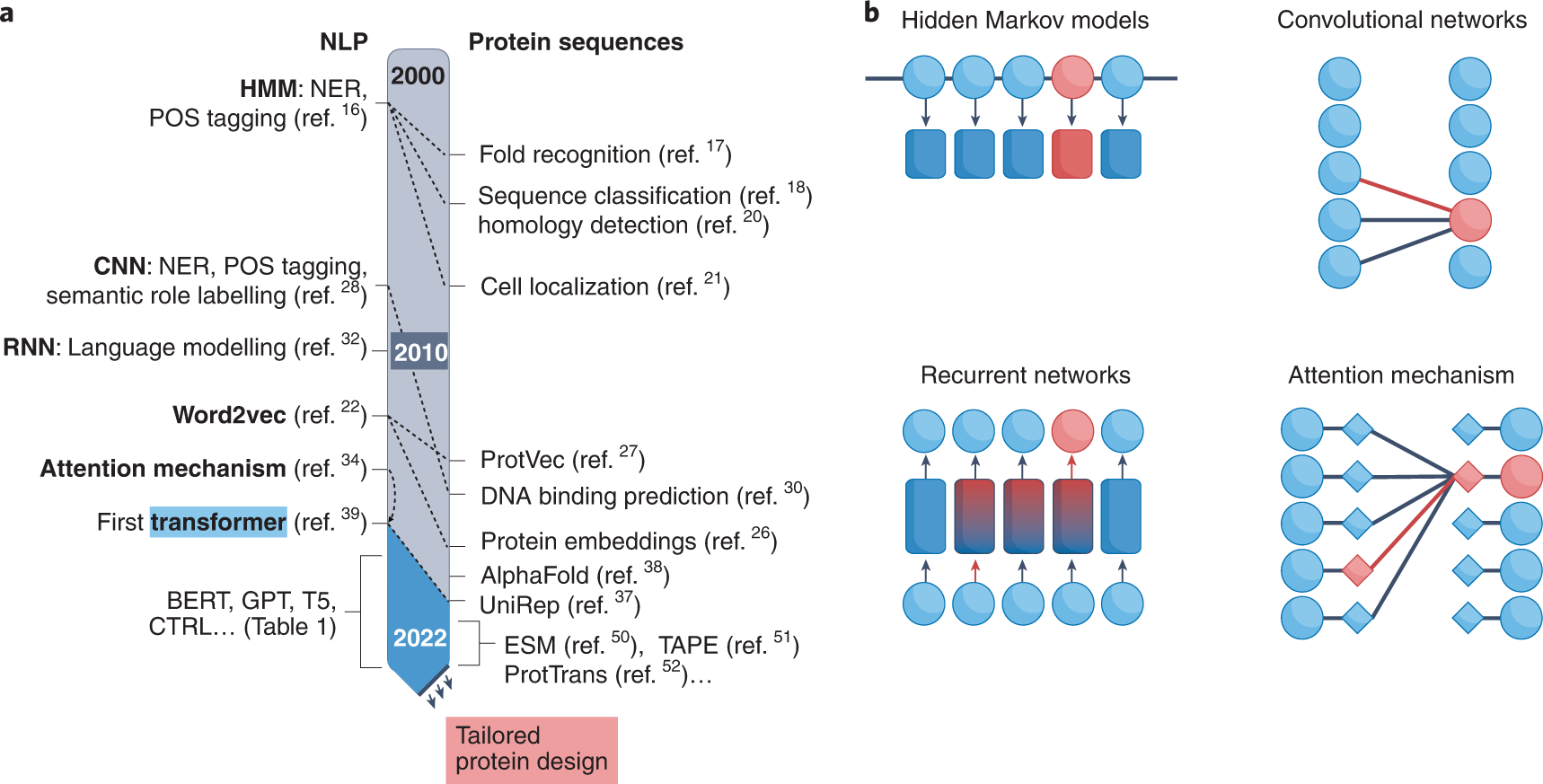
上图总结了两个领域之间的相似之处。虽然不明显,但NLP领域一直影响着蛋白质研究,将解决NLP问题的技术迁移到蛋白质序列上。几十年来,NLP问题一直采用浅层机器学习方法,如支持向量机(SVM)或隐马尔科夫模型(HMM),用于解决文本分类和标记问题。HMMs和SVMs也被广泛用于蛋白质的分类和标记问题,如折叠识别、序列分类和细胞定位,并且仍然是序列同源性检测的最先进方法。
a图展示了NLP方法及其在蛋白质研究中的应用的最新时间表。NLP的每一个突破都反映在多年后的蛋白质研究应用中。
b图对NLP最常用方法进行了图形解释。虽然隐马尔科夫模型(HMMs)是随机过程,但卷积网络(CNNs)、递归网络(RNNs)和注意力机制是神经网络,或参与神经网络。
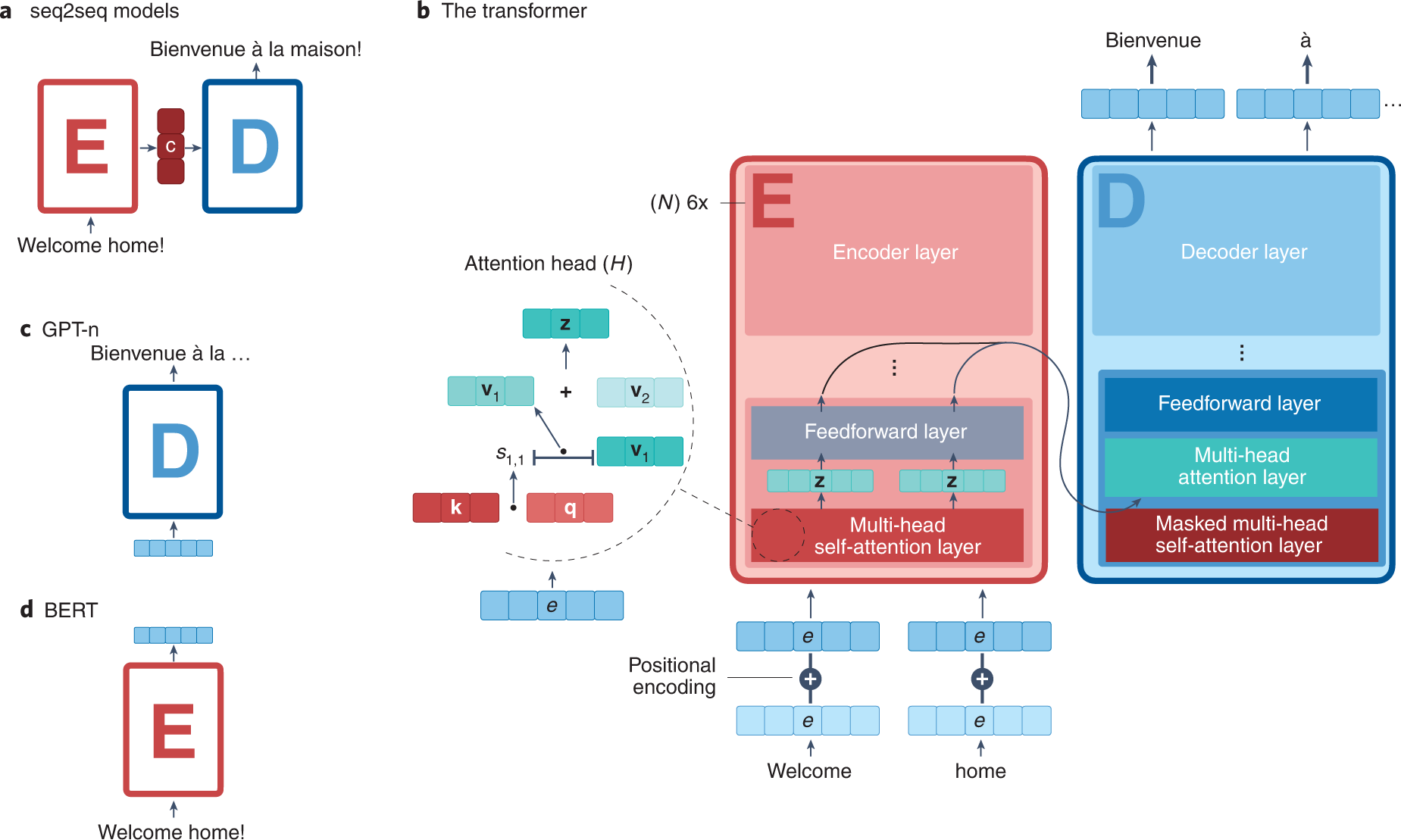
上图展示了一些蛋白领域涉及到的常用的Transformer架构,seq2seq模型提出了处理连续输入的编码器(E)和解码器(D)模型,这些输入被编码为上下文(c)向量。原始的Transformer结构由编码器和解码器模型组成,每层有六个堆栈。GPT-n Transformer是基于原始Transformer的,但只包含解码器模型(c),而BERT只使用编码器(d)。
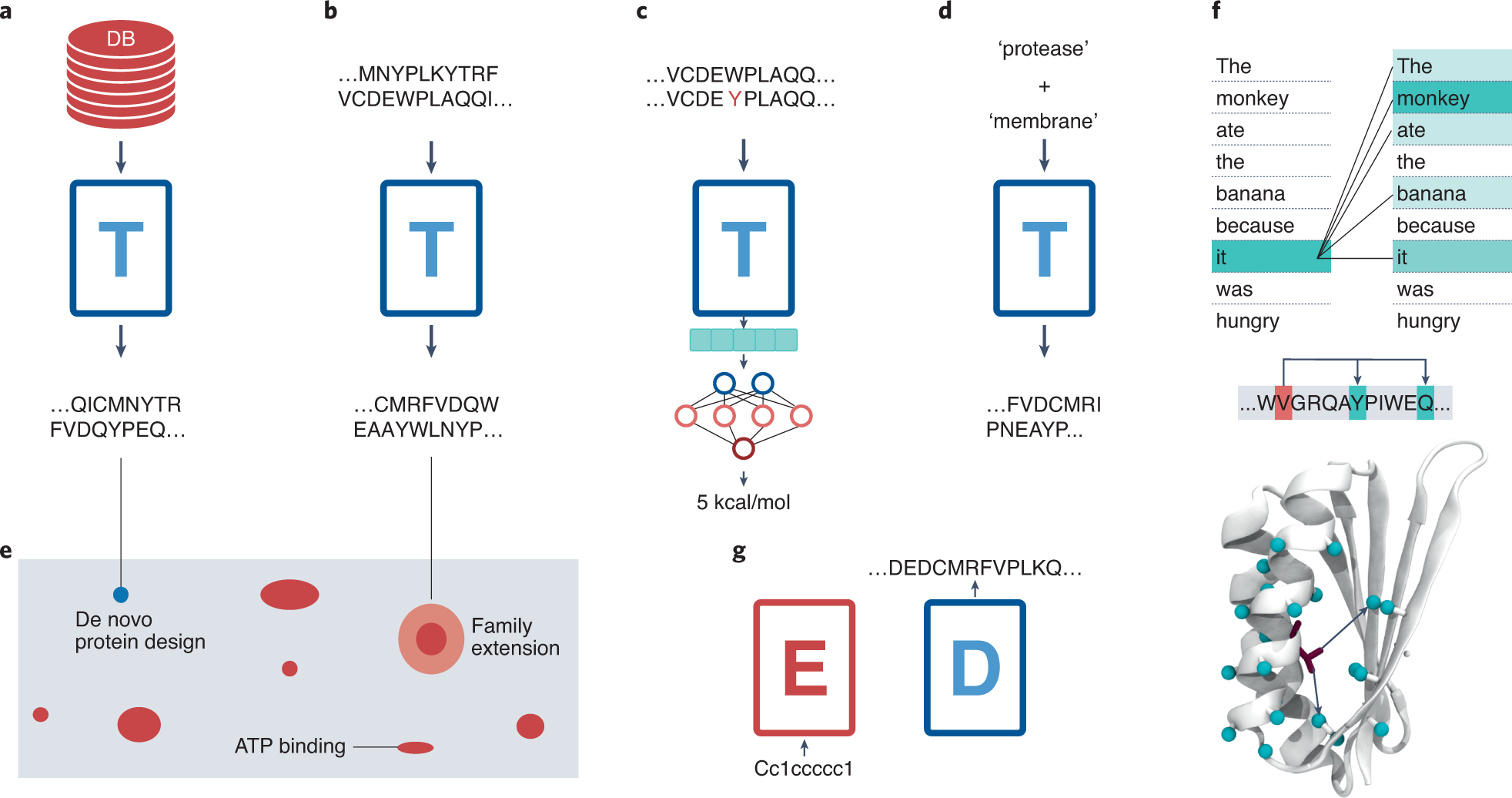
a, 用蛋白质序列数据库训练Transformer(T)后,有可能产生新的蛋白质序列(如e所示)。 b, 在一个蛋白质家族上微调预训练的模型将产生与该家族兼容的新序列。
c, 最后一层的向量表示可以通过与耦合模型的训练用于各种下游任务,例如,预测蛋白质的稳定性。尽管这些最后的模型一直专注于零样本的序列设计,但它们也具有执行其他任务的潜力。一方面,由于它们最后一层的激活是有效的输入表征,DARK或ProtGPT2架构也可以与其他模型耦合,以预测功能损失或突变效应。另一方面,生成模型可以通过对特定类型的数据进行微调来控制文本的方向,所以蛋白质语言模型也有可能在对用户定义的序列进行微调后设计出一个特定的家族或折叠。这些进展显示了自回归变换器在蛋白质设计中的美好前景,同时为蛋白质工程任务打开了一扇新的大门。
d, 条件Transformer将能够生成具有某些属性的序列,如'蛋白酶'或'膜'结合。这种情况下,直接生成具有训练集中所包含的属性的序列,如结合ATP、折叠成全β结构或与膜结合。类似于控制标签的组合,如风格+主题("诗歌 "+"政治"),提供特定的文本,蛋白质特性的融合可以创造新的功能,如 "水解酶 "+"PET结合 "或 "膜结合 "+"蛋白酶"。
e. 蛋白空间示意展示,研究出现在整个蛋白质空间的几个区域的属性标签,如 "膜蛋白 "或 "ATP结合",将是非常重要的。输出的序列也许可以为这些属性提供迄今未知的解决方案,序列空间未开发区域的蛋白质,并提供了解其结构对这些功能特征的要求的手段
f, 注意机制的可视化打开了理解Transformer模型的大门,与其他技术一起,可用于理解蛋白质设计原则,如所需的相互作用。注意机制本身对应于对输入特征的重要性评分,这允许将原始分数可视化为显著性热图。本图说明了一个句子的自注意力,其中一个特定的注意层在 "它 "这个词和其他词之间归属了几个注意分数。以类似的方式,蛋白质序列将对应于氨基酸之间的注意力分数的表示。
最近,人们努力将Transformer的XAI带入用户友好界面。例如,exBERT(https://exbert.net)能够使在任何语料库上训练的任何Transformer的内部表示法可视化。它可以为所有不同的注意层可视化自我注意的用户定义的句子,选择特定的词并可视化每一层的网络语料部分预测,或者在显示最高相似度匹配的训练语料库中搜索它们。将exBERT改编成一个蛋白质训练的Transformer,可以使蛋白质中的氨基酸之间的关系互动可视化,并与POS标签类似,预测它们的属性。同样,在训练语料库中搜索蛋白质片段并找到相似度最高的匹配,可以阐明蛋白质之间的新关系。尽管这一领域仍处于起步阶段,但将Transformer的内部运作可视化的可能性可以为更好地理解蛋白质的折叠和设计带来巨大的机会。
g, 机器翻译模型,如来自原始Transformer,可实现受体和酶的设计。通过反转机器翻译模型,也许能够生成与编码器输入SMILES兼容的序列。这样的模型可以在受体蛋白的工程方面有巨大的应用,包括预测识别和结合特定配体的序列,这是受体和生物传感器设计的一大进步。考虑到IBM最近对化学反应的矢量表示进行编码的方法,可以设想另一个模型,把化学反应作为输入,产生蛋白质序列作为输出。这种模型将为酶的设计提供一种创新的途径,包括能够催化自然界中没有的反应的工程酶。这种方法有可能支持生物战略,例如,逆转环境污染。
创新点
- 本文设想了将目前的NLP方法转移到蛋白质研究领域的六个直接应用。按照目前的NLPTransformer对蛋白质序列的适用程度排序,可以(1)在蛋白质空间的未观察到的区域生成序列,(2)对天然蛋白质家族的序列进行微调,以扩展其剧目,(3)利用其编码的矢量表示作为其他下游模型的输入,用于蛋白质工程任务。(4)生成具有特定功能特性的条件序列,(5)利用编码器-解码器Transformer设计完全新颖和目的驱动的受体和酶,以及(6)对序列-结构-功能关系获得更全面的理解,包括通过解释这些语言模型支配蛋白质折叠的规则。毋庸置疑,这些进展并非没有挑战,模型的大小和功能注释的困难都是最值得注意的两个问题。
- 此外,正如早期研究指出的那样,基准将是比较模型性能的首要条件,这在序列生成方面尤其具有挑战性。迄今为止,大多数生成性模型都是在其二级结构、球状蛋白或与自然序列的相似性方面进行评估的。然而,对生成的序列进行适当的评估,最终需要实施高通量的实验特征分析。正如在以前的工作中所进行的那样86,对这些序列的可表达性的评估将是至关重要的。
- 此外,最终至关重要的是评估这些序列的相关功能,如其催化活性,超过目前的蛋白质工程策略--可能是在实验反馈改进模型的迭代回合中。尽管有这些困难,本文相信基于Transformer的蛋白质语言模型将彻底改变蛋白质设计领域,并为许多当前和未来的社会挑战提供新的解决方案。本文希望本文的想法能够达到人工智能和生物化学界,并鼓励将NLP方法应用于蛋白质研究。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢