
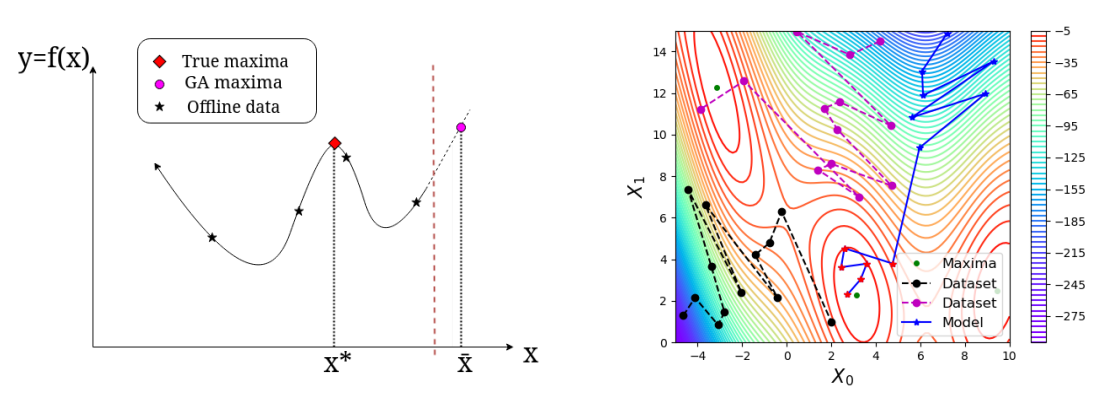
左图展示了一个一维问题上的离线BBO实例。这红色虚线为取值域边界。因此,正确的最优值是x∗,而拟合函数的梯度上升法将输出域外分布点x¯。
右图展示了二维Branin函数的轨迹示例,两条虚线表示本文离线数据集中的轨迹,实线是指模型轨迹,蓝点表示探索,红点表示利用。
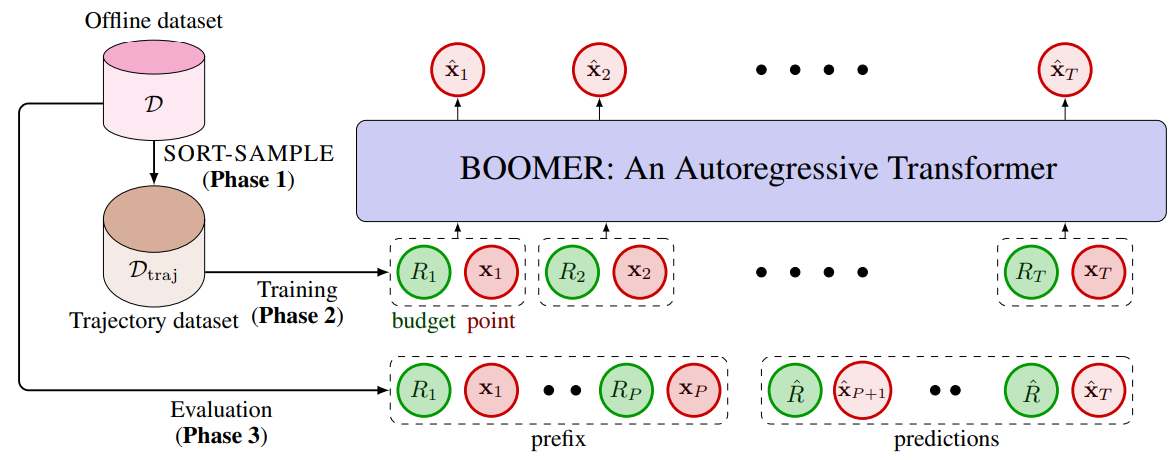
上图为BOOMER的原理图。BOOMER由3个连续的阶段组成:轨迹构建、自回归建模,推出评估。在第一阶段,使用SPORT-SAMPLE将离线数据集D转换成一个轨迹数据集D_traj。在第二阶段,为D_traj学习一个自回归模型。在第三阶段,将该模型置于一个离线前缀序列上,并进一步展开以获得候选,推出Q个候选点来评估该模型。这其中Rˆ为Evaluation Regret Budget
上图展示了在Branin benchmark上的结果,该基准为一个在定义域中有3个全局最优(−0.398)的二元函数,对于离线优化,本文在域中均匀地取样N=5000个点,并从这个集合中去除根据函数值的前10%,以去除接近优化点的点,使任务更具挑战性。然后,本文根据SORT-SAMPLE策略构建400条每条长度为64的轨迹。在评估过程中,本文初始化四个前缀为32的轨迹,并将其展开进行评估。长度为32的轨迹,再展开32步,并输出最佳结果,这样就消耗了128的查询预算。
BOOMER成功地泛化了本文离线数据集中的最佳点之外,离线数据集最优点为−6.119,BOOMER得到了全局最优−1.79 ± 0.843。梯度上升基线使用离线数据集来训练一个前向模型(一个2层的NN)来映射x到y,然后对x进行梯度上升来推断其最优值,效果为−3.953 ± 4.258。
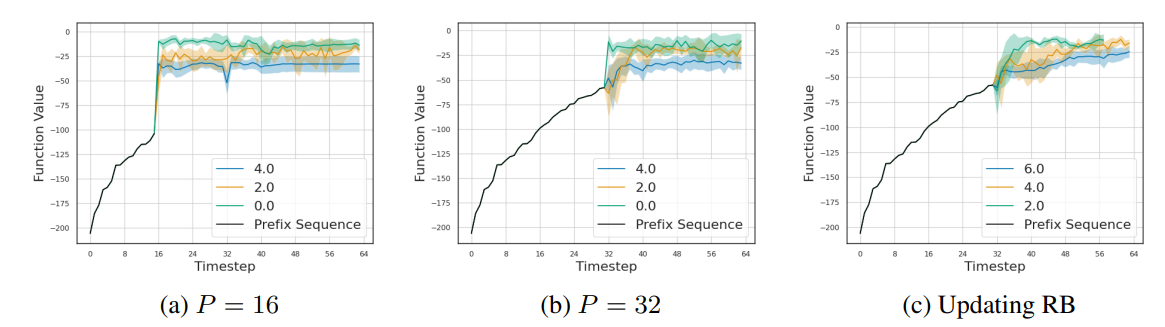
Branin任务在多个Rˆ值下的推出轨迹。图(b)显示了前缀长度为32的轨迹,在图(a)中,将前缀长度改为16,而在图(c)中,在后缀子序列中更新评估RB。可以看到,与高Rˆ相比,低Rˆ推出的质量更高的点。为了验证本文将regret预算作为控制探索和开发程度的旋钮的语义,在图5c中,本文还绘制了更新后缀中RB值的轨迹。如果RB变成非正值,就停止推出。很明显,对于较小的Rˆ,代理模型迅速加速到高质量的区域并不断地开发,而对于高Rˆ,它逐渐转移到高质量的点。这表明Rˆ是如何控制从探索到开发的转变速度的。

接下来,本文在Design-Bench的5个复杂的真实世界任务上评估BOOMER。这些任务被认为具有挑战性,因为它们具有高维度、离线数据集中的低质量点、某些情况下的近似oracle,以及具有狭窄最优区域的高度敏感landscape。
总的来说,BOOMER获得了0.772的平均分和2.4的平均排名,这在所有基线中是最好的。BOOMER在TF-Bind-10(离散)和D'Kitty(连续)这两个任务上取得了最佳结果。此外,本文在七个任务中的五个任务中名列前二。在TF-Bind-8、TF-Bind-10、Ant和D'Kitty上,BOOMER显示出比MINs或CbAS等生成方法以及COMs等前向映射方法的明显改进。本文还注意到,虽然BOOMER在Ant中排名第二,但它的标准差(0.012)比表现最好的方法CMA-ES低得多,后者的标准差为0.928。在所有的任务中,BOOMER的平均标准差也是最低的,这表明BOOMER与其他方法相比,对不良初始化的敏感性较低。
创新点
本文提出了BOOMER,一个新的生成框架,用于使用离线数据预训练黑盒优化器。BOOMER包括一个三阶段的过程。在第一阶段,使用一个新颖的PORTSAMPLE策略从离线数据中生成轨迹,这些轨迹使用排序启发式方法从探索过渡到开发。本文进一步提供一种机制,通过Regret Budget来控制探索和开发的程度。在第二阶段和第三阶段,本文使用自回归变换器训练本文的模型,并使用它来生成使黑盒函数最大化的候选点。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢