
【标题】PAC: Assisted Value Factorisation with Counterfactual Predictions in Multi-Agent Reinforcement Learning
【作者团队】Hanhan Zhou, Tian Lan, Vaneet Aggarwal
【发表日期】2022.6.22
【论文链接】https://arxiv.org/pdf/2206.11420.pdf
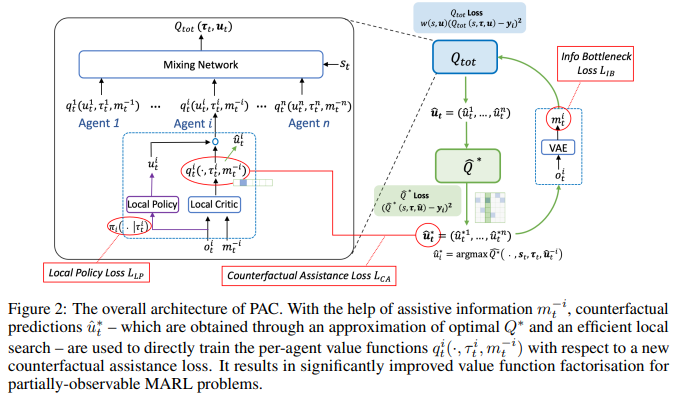
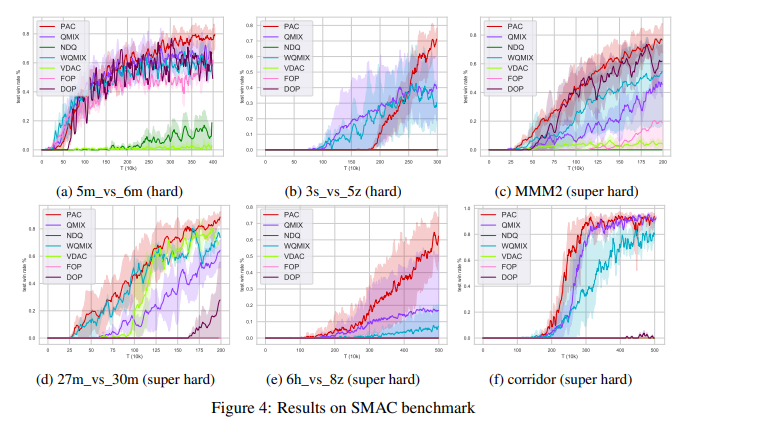
【推荐理由】随着价值函数分解方法的发展,多智能体强化学习(MARL)取得了重大进展。由于单调性,它允许通过最大化因式分解的每个智能体的效用来优化联合动作值函数。本文表明,在部分可观察的MARL问题中,agent对其自身动作的排序可能会对可表示函数类施加并发约束(跨不同状态),从而在训练过程中导致显著的估计错误。为此提出了PAC,通过最佳联合行动选择的反事实预测生成的辅助信息的新框架,为价值函数因式分解提供了明确的帮助。提出了一种基于变分推理的信息编码方法,用于从估计基线收集反事实预测并进行编码。为了实现去中心化执行,还从最大熵MARL框架中导出了因式分解的每个智能体策略。在多智能体捕食者-食饵和一组星际争霸II微观管理任务上评估了所提出的PAC。研究表明在所有基准上,PAC的结果都优于最先进的基于价值和基于策略的多智能体强化学习算法。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢