
© 作者|闵映乾
机构|中国人民大学
研究方向|自然语言处理
本文是笔者在读到几篇有关预训练语言模型的应用方向研究的论文后作的一些总结和分享,下面将对它们进行逐篇介绍。文章掺杂了笔者的一些个人见解,各位读者如果有什么问题都可以留言讨论,欢迎经常交流!另外,正文中使用的图片均来自于原论文,文中会附上原文链接,感兴趣的朋友可以自行查看原文。

以一个较为生动形象但可能不那么恰当的例子开始,如果将各位学者在AI领域的研究进程比作西天取经,希冀有朝一日得到真经,让人工智能真的成为改变世界的智能,那么近些年的预训练语言模型(PLM)可以说暂时成为了西行路上的大师兄。它所学甚多(经过了庞大的语料训练,蕴含了庞大的知识),精通七十二般变化,拔下一撮猴毛就成了一个军队(可以涉猎各种下游任务),并且神通广大,轻易翻过了原先堵在路上的几座大山(在很多任务上模型表现都超过了原有的方法),形势一片大好。
但是,西行路上终归有九九八十一难,求知的道路注定不会那么一帆风顺,PLM自身仍然有诸多问题。PLM并非万金油,也不能拿来就用,在不同的下游任务上,需要做出不同的适应和调整。而如何用好”紧箍咒“,帮助PLM认清自己,搞准定位,并掌控自己的力量,以继续提升任务表现,则是各位研究者应当思考也必须思考的问题。笔者接下来就要介绍两篇关于PLM的定位和应用走向的论文。
一、Large Language Models are Zero-Shot Reasoners
论文链接:https://arxiv.org/abs/2205.11916
正像标题所说的那样,本篇论文着重探究大规模语言模型在零样本(zero-shot)场景中学习和推理的潜力。在此之前,已经有相当多的工作表明,在有任务特定范例的情况下,PLM是很优秀的少样本(few-shot)学习者,但在zero-shot场景下的相关研究还较少。作者所使用的方法继承自Chain of Thought Prompting (CoT)[1],仅需在问题后加上“Let' think step by step”,就能在zero-shot场景下取得非常好的效果。实验表明,使用相同的prompt模板且在没有使用任何手写的few-shot例子的情况下,Zero-Shot-CoT在不同的基准任务上,例如算术(MultiArith, GSM8K, AQUARAT, SVAMP),符号推理(Last Letter, Coin Flip),和逻辑推理任务(Date Understanding, Tracking Shuffled Objects)均明显优于zero-shot LLM的表现。
方法介绍
本文采用的方法基于Chain of Thought Prompting,这是一种将问题分解,进行分步骤回答的引导策略,类似于人类思考问题时的思维链。CoT本来应用于few-shot场景下(此后都将其称为few-shot-CoT)如下图所示,普通的prompt示例直接给出了答案,而CoT方法在回答中根据问题分步骤解答:“开始时有5个球,2罐里一共有6个球,5+6是11个球,因此答案是11”,而模型的输出也按照这种分解方式,从而得到了普通prompt无法得到的正确答案。
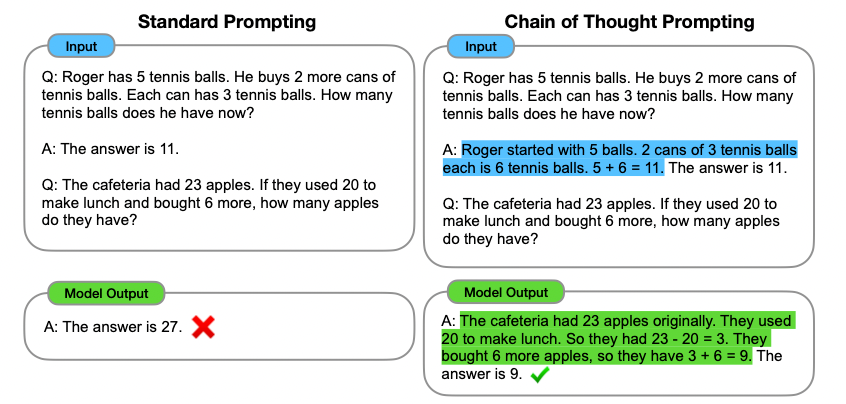
可以看出,few-shot-CoT需要比较细致的人工参与,针对每个任务来制定特定的prompt例子。而在zero-shot场景下,没有了例子的引导,作者采取了Two-stage prompting的方法,下面称为zero-shot-CoT:
第一阶段被称为推理提取。在这一步中,首先使用一个简单的模板“Q: [X]. A: [T]”,其中[X]是问题x的输入,[T]代表一个手写的触发语句,帮助提取思维链来回答问题x。例如,如果使用“Let's think step by step.”作为提示句的话,整个输入就变成了“Q: [X]. A: Let's think step by step." ,用x'来代表。x'被喂给PLM,并生成随后的句子z。
第二阶段被称为答案提取。在这一步中,使用x'和上一步中生成的句子z拼接起来,再加上这一步提取答案的触发句A,即形如[X'] [Z] [A],再喂给PLM,并根据模型生成的句子解析得到最终的答案。下面论文中对于这两步的一个简单的图示:
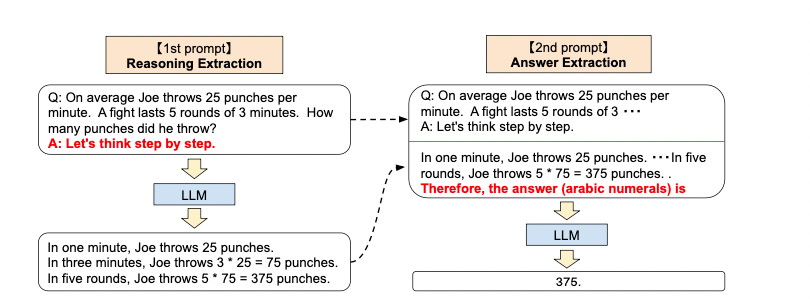
总的来说,核心思路其实是使用预训练模型对输入进行自我增强,试图让模型在没有例子的情况下也能类似思维链条一样自我推理。
实验设置与结果
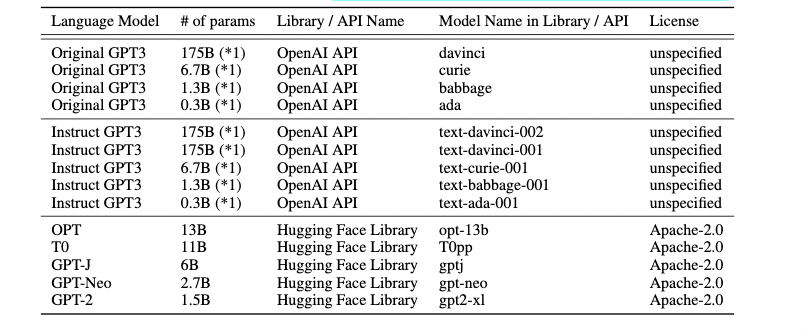
论文中共采用了多个预训练语言模型来进行实验,参数量从0.3B到175B不等:
而在方法对比上,作者使用上面提出来的zero-shot-CoT方法和标准的zero-shot方法进行比较,来验证思维链条推理在zero-shot场景下的有效性;除此之外,作者还对比了Chain of Thought Prompting[1]中的标准few-shot方法和few-shot-CoT方法,评估PLM在zero-shot场景下的推理能力。
论文在不同的基准任务上做了充分的实验,包括数学问题(SingleEq, AddSub, SVAMP, MutiArith, AQUA-RAT, GSM8k)、常识推理(Common SenseQA, Strategy QA)、符号推理(Last Letter, Coin Flip)以及逻辑推理(Date Understanding, Tracking Shuffled Objects)
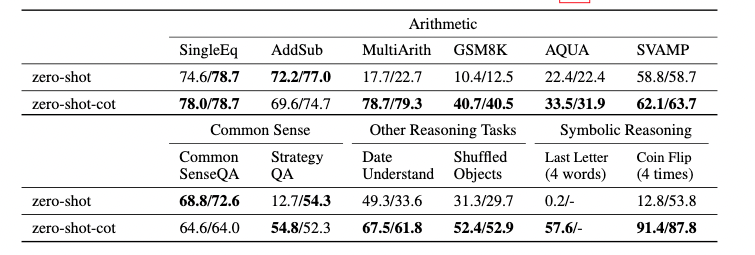
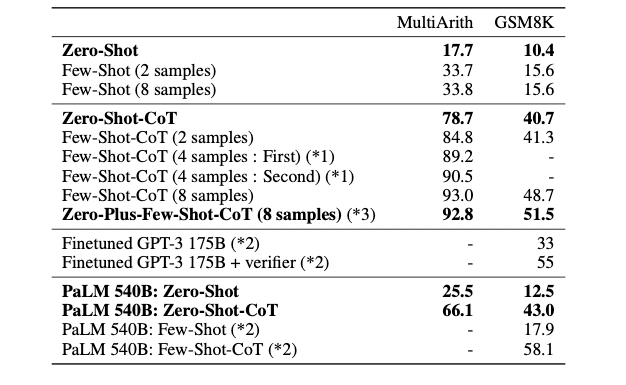
可以发现,zero-shot-CoT相比标准zero-shot方法确实普遍有提升。在常识推理任务这块,zero-shot-CoT并没有提供性能提升,但这也是意料之中的,因为few-shot-CoT在原论文中也没有提供性能提升。除此之外,作者还在MultiArith和GSM8k两个数据集上做了进一步实验,可以看到zero-shot-CoT的效果要比zero-shot的强很多;虽然zero-shot-CoT的性能不如few-shot-CoT,但是却强于标准的few-shot方法,这证明了预训练模型在零样本推理上的潜力;如果在few-shot-CoT的基础上再加上之前zero-shot-CoT的启发句,在GSM8K任务上还可以有进一步提升。
为了更好地了解zero-shot-CoT的表现,论文就错误例子进行了分析。发现两个有趣的现象:
-
在常识推理(CommonsenseQA)任务中,即使最后预测的答案不正确,zero-shot-CoT也可能会产生合理的思维链,或者是无法从多个答案中缩小到一个答案输出;
-
在算数推理(MultiArith)任务中,zero-shot-CoT和few-shot-CoT的错误模式有较大的差异。zero-shot-CoT经常在得到正确答案后输出不必要的推理步骤,使得这次预测变成了错误的预测;亦或是不推理,而是重新表述输入的问题。

最后,论文就预训练语言模型的规模和prompt语句的选取对CoT的影响做了分析。下表是各种规模的语言模型在MultiArith上的表现,零样本和少样本的标准方法结果随着模型规模的增加变化不大,但是CoT方法随着模型规模的增大表现却陡然变好,因此说明CoT方法更加适合大规模的语言模型。
论文给出了在八个不同的prompt模板下模型的表现性能,发现准确率的差异还是很大的。在实验中,“Let's think step by step”取得了最好的结果,不同的模板表述推理的方式也很不一样。

总结
本文方法实际上仍然属于prompt范畴,所以仍然拥有和prompt类似的缺点,例如模板的可解释性和鲁棒性等。本篇文章可以看作是对于大规模预训练模型在zero-shot场景下推理任务的一种尝试,相较于之前工作中的few-shot(in-context)方法,该论文方法并不需要手写的例子,并且在目前zero-shot场景下有着极好的表现。
二、Language Models are General-Purpose Interfaces
论文链接:https://arxiv.org/abs/2206.06336
本文旨在研究将预训练作为一种基础模型的通用接口方法。基础模型在各种下游任务上的有效性则是评价模型用处的重要指标。虽然在架构上有很大的融合,但是大多数模型仍然是为特定的任务或模态设计开发的。本文提出半因果的语言建模目标,联合预训练接口和编码器模块,从而将语言模型作为各种各种基础模型的通用接口,利用不同的编码器感知不同的模式信息。在模型设计上,本文总结归纳了因果建模和非因果建模的优点,并结合二者进行半因果建模,提出模型Meta Language Model(METALM)。论文中在单一语言任务和视觉语言联合的任务上都进行了实验,结果表明,本文的模型METALM在微调,零样本泛化和少样本学习方面均是优于专门模型或者效果对比专门模型有竞争性。
设计原则
-
将语言模型作为通用的任务层。大规模的语言模型不仅可以作为语言任务的通用接口还可以作为视觉任务或多模态任务的接口。语言模型有开放的输出空间,可以通用于广泛的任务,核心思路是通过自然语言来描述预测,使得下游任务匹配上基于语言模型的任务层。例如,可以将目标标签和答案转化成文本,用于分类和问答任务。这样的对于各种任务的统一对于通用任务的AI来书欧式很重要的,因为可以将表征、转换和表达统一到一共共享模块中。 -
因果语言模型有利于/更擅长零样本泛化和语境中学习。zero-shot generalization 和few-shot learning的能力对于通用任务层很关键,因为这些能力意味着模型在预训练阶段阅读过大量的文本语料,学习到了大量的知识。相较于其它模型,因果语言模型表现了更好的采样效率和更少的归纳误差。 -
非因果模型有利于/更擅长跨任务、跨语言、跨模态的转移。这主要得益于双向编码器。在非因果模型中,所有的的上下文都可以相互访问,因此在有标注数据的情况下可以实现更好的微调性能。 -
将半因果建模作为一个元预训练任务。非因果编码器学习表征不同的输入数据,因果语言模型作为一个通用任务层,将非因果编码器和因果语言模型对接,就可以兼顾上面两种建模方法的优点。针对不同的任务种类,可以将多个双向编码器安装到因果语言模型上。 -
用户和预训练模型之间的自然语言接口。基于因果语言建模的通用任务层使得用户能够通过自然语言和模型互动。首先,自然语言可以作为底层预训练或者微调模型的变成语言,由通用接口进行编译;其次,通用接口使得模型能够用自然语言呈现结果,这样预测就更加容易被理解;第三,这样的框架自然地就支持多轮对话互动,在每一轮中都可以将编码后的输入交给接口层然后以半因果的方式产生相应结果。
模型架构
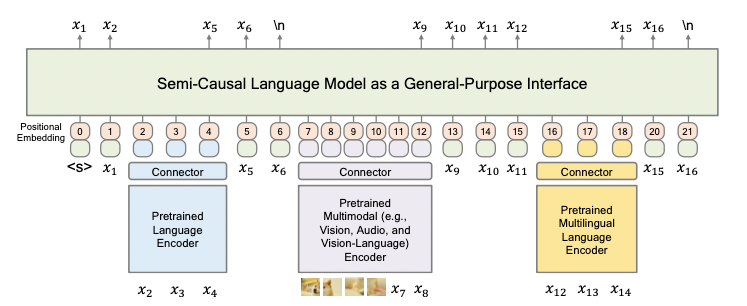
根据上述设计原则,作者设计了如下图的METALM。模型有一组专门用于不同任务的双向编码器,例如用于语言任务的、多模态任务的、多语言任务的等等;每种编码器都有相应的connector用于将不同的表示映射到同一个空间上。
该模型的输入表示可以分为两类,第一类是通过编码器获得的上下文表示,然后通过connector映射,如下图中的图像块和、这样的;第二类则是文本的词嵌入,例如图中的、。这两类的表示跟位置嵌入表示相加,然后再喂给通用接口。除此之外,connector也被用来匹配通用任务层和基础模型输出的维度。根据实验发现,线性投影和前馈神经网络都表现良好。
语言任务实验
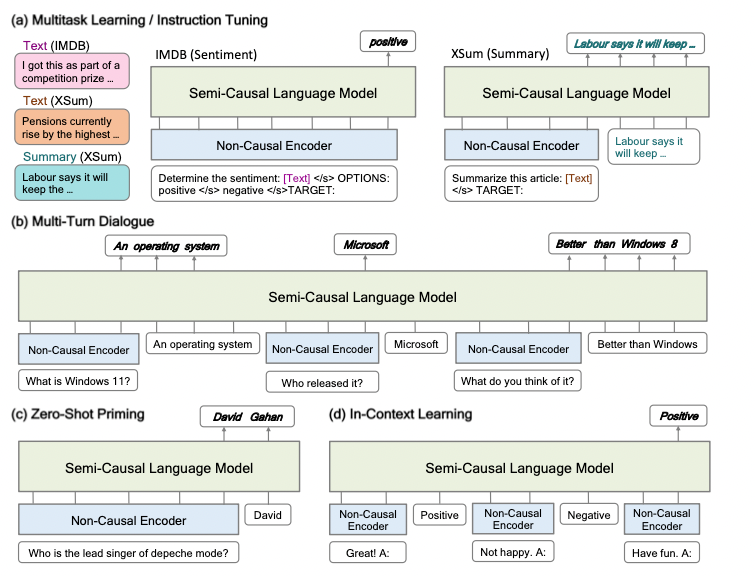
论文首先在仅有语言的数据集上进行实验,以证明METALM的多功能性和有效性。如下表,作者从多任务微调、单任务微调、指令调整以及上下文学习几个方面进行评估,每个方面都体现了METALM的能力,这些能力和任务无关,可以广泛地使用于理解、生成和互动。

下图展示了METALM是如何在不同的场景下工作的——输入的例子和指令被喂给非因果编码器,目标输出则由通用任务层产生。因为通用任务层是因果语言模型,因此预测是以生成的方式产生的,它是开放且易于理解的。
文中分别给出了METALM在四种场景下,同其他模型的比较结果(如下的四个图)。关于参数设置本文不再赘述,推荐有兴趣的朋友去原文查看。在多任务微调场景下,论文在NLU和NLG上的多个任务都进行了实验,并将结果与GPT进行对比,可以发现,除了Struct to Text任务,其他任务中METALM表现均优于GPT。
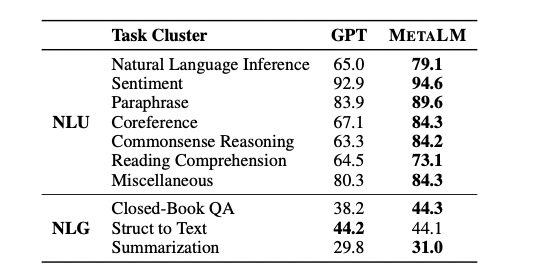
METALM和GPT在多任务微调场景下的表现对比
在单任务微调场景下,本文在MNLI上比较了GPT、BERT、RoBERTa、ELECTRA和METALM的表现,可以发现,METALM的表现仍然是最好的。
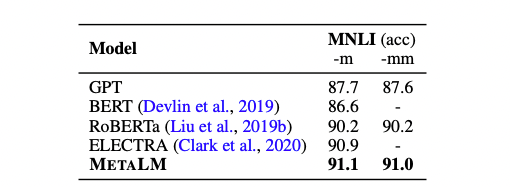
METALM和几个baseline模型在单任务微调场景下的表现对比
在指令微调零样本生成的场景下,论文仍然选择GPT作为baseline和METALM进行比较,选取了NLI、Sentiment、Paraphrase和Reading Comprehension里的多个数据集进行测试,平均效果下METALM的表现基本都是很好的。
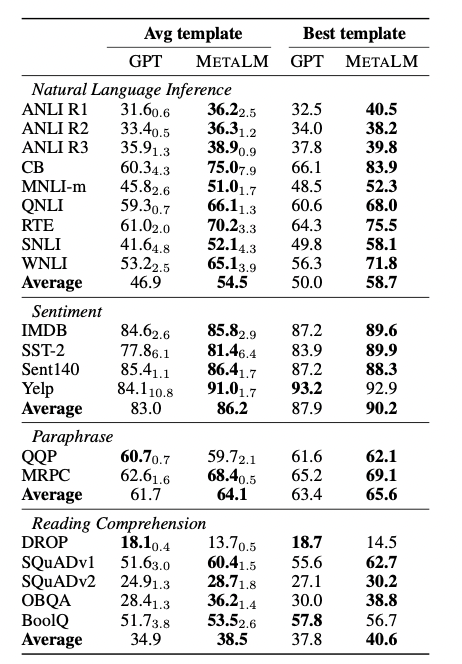
METALM和GPT模型在指令微调的表现对比
在上下文学习的场景下,论文在zero-shot和few-shot上都做了实验,表中的k表示shot的数量MetaLM在某几个数据集上表现可能稍差一些,但在平均水平上还是优于GPT的。
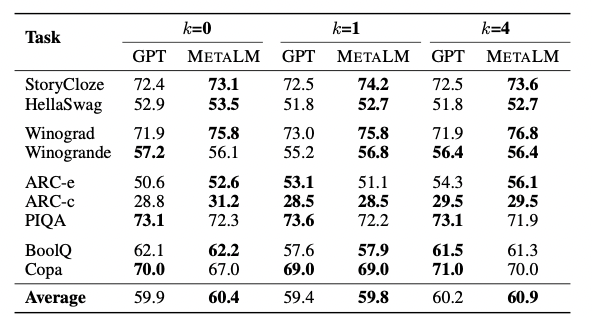
METALM和GPT在上下文学习的表现对比
视觉-语言联合任务实验
得益于前面模型设计的准则,METALM很自然地适用于多模态的联合任务。尽管输入使用了图像-文本对,但预训练任务和单纯的语言训练任务设置是类似的。预训练阶段,对图像-文本数据和纯文本数据进行联合预训练。图像内容被放在文本前面,不同模态的数据输入可以传给不同的非因果编码器。因果通用任务层经过预训练,以双向融合表示作为条件自动预测剩余的token。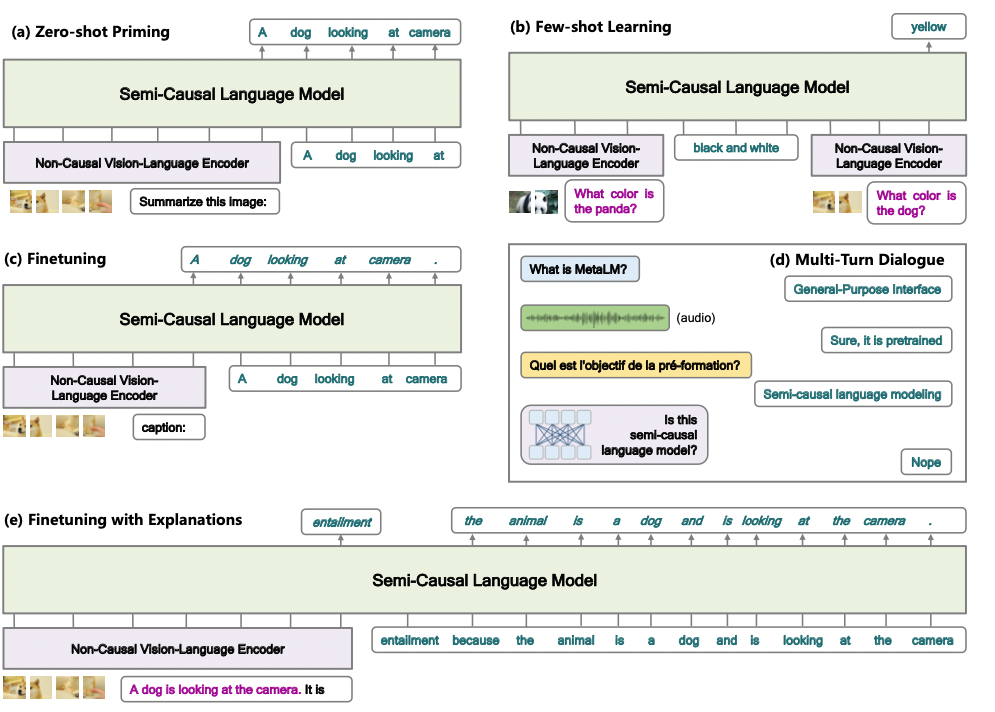
类似的,论文在零样本泛化、上下文学习以及下游任务微调这几个方面进行实验,证明METALM还是相当“能打”的。
总结
笔者介绍了两篇关于预训练模型的定位/潜力的论文,它们的模型方法相比现有工作是有竞争性的,并且思路较为新奇,个人觉得比较有趣,但并非说这些就一定是好的对的或不好的不对的方向,欢迎感兴趣的朋友参与讨论和批评指正。
引用
[1] Wei J, Wang X, Schuurmans D, et al. Chain of thought prompting elicits reasoning in large language models[J]. arXiv preprint arXiv:2201.11903, 2022.
[2] Kojima T, Gu S S, Reid M, et al. Large Language Models are Zero-Shot Reasoners[J]. arXiv preprint arXiv:2205.11916, 2022.
[3] Hao Y, Song H, Dong L, et al. Language Models are General-Purpose Interfaces[J]. arXiv preprint arXiv:2206.06336, 2022.
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢