
OpenAI官方博客最近更新了一篇文章,介绍了如何规避DALL·E 2输出内容风险性的几个主要方法,文章主要内容如下:
为了与广大观众分享 DALL·E 2 的魔力,我们需要降低与强大的图像生成模型相关的风险。为此,我们设置了各种防护措施,以防止生成的图像违反我们的内容政策。这篇文章的重点是预训练缓解措施,这些防护措施的一个子集,直接修改 DALL·E 2 从中学习的数据。特别是,DALL·E 2 使用来自互联网的数以亿计的字幕图像进行训练,我们删除并重新加权其中一些图像以改变模型的学习内容。
这篇文章分为三个部分,每个部分描述了不同的预训练缓和措施:
在第一部分,我们描述了我们如何从 DALL·E 2 的训练数据集中过滤掉暴力和色情图像。如果没有这种缓解措施,模型将学会在提示时生成图形或显式图像,甚至可能无意中返回这些图像以响应看似无害的提示。
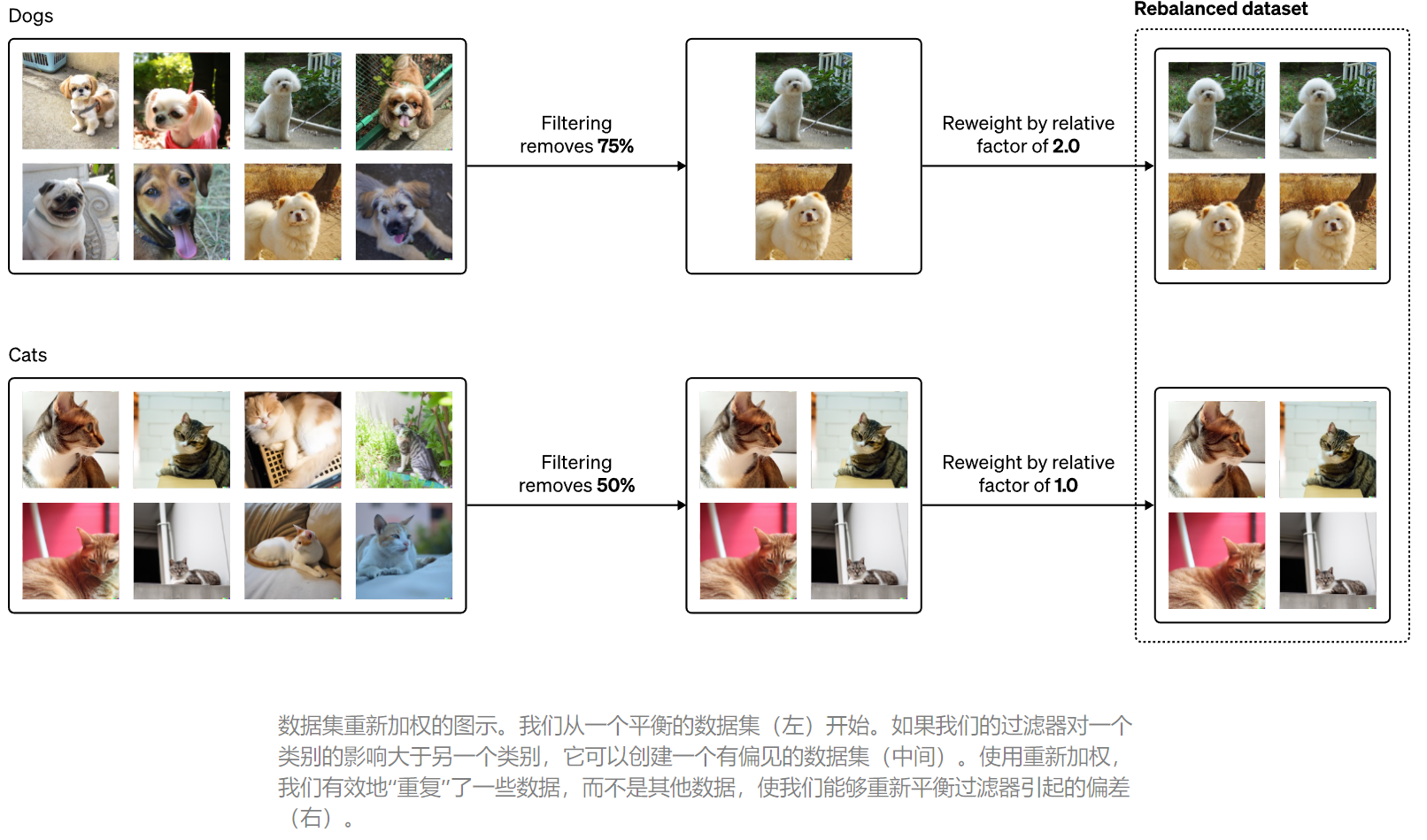
在第二部分中,我们发现过滤训练数据可以放大偏差,并描述我们减轻这种影响的技术。例如,如果没有这种缓解措施,我们注意到,与在原始数据集上训练的模型相比,在过滤数据上训练的模型有时会生成更多描绘男性的图像和更少描绘女性的图像。
在最后一部分,我们转向记忆的问题,发现像 DALL·E 2 这样的模型有时可以重现他们训练过的图像,而不是创建新的图像。在实践中,我们发现这种图像反流是由在数据集中多次复制的图像引起的,并通过删除与数据集中其他图像在视觉上相似的图像来缓解该问题。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢