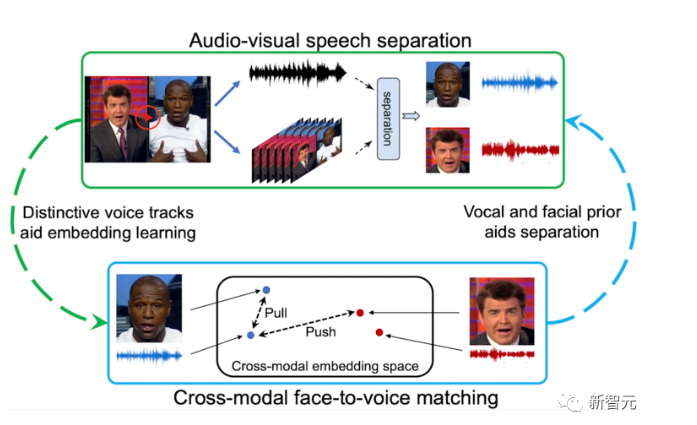
Meta的这项研究主要包括三个模型,分别是视觉声觉匹配模型(Visual Acoustic Matching model)、基于视觉的去混响模型(Visually-Informed Dereverberation)、音视频分离模型(Visual Voice)。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

Meta的这项研究主要包括三个模型,分别是视觉声觉匹配模型(Visual Acoustic Matching model)、基于视觉的去混响模型(Visually-Informed Dereverberation)、音视频分离模型(Visual Voice)。
内容中包含的图片若涉及版权问题,请及时与我们联系删除
沙发等你来抢

评论
沙发等你来抢