

论文标题:TransFusion: Robust LiDAR-Camera Fusion for 3D Object Detection with Transformers
作者单位:香港科技大学,华为IAS BU, 香港城市大学
论文:
https://openaccess.thecvf.com/content/CVPR2022/papers/Bai_TransFusion_Robust_LiDAR-Camera_Fusion_for_3D_Object_Detection_With_Transformers_CVPR_2022_paper.pdf
代码:https://github.com/xuyangbai/transfusion
导读
尽管传感器融合在这一领域越来越受欢迎,但对于较差的图像条件(如照明不良和传感器不对中)的鲁棒性尚未得到充分研究。现有的融合方法容易受到这些条件的影响,主要是由于激光雷达点与图像像素之间通过标定矩阵建立的硬关联。我们提出TransFusion,一个强大的解决方案,以LiDAR-camera融合与软关联机制,以处理低劣的图像条件。具体来说,我们的TransFusion由卷积骨干和基于Transformers解码器的检测头组成。解码器的第一层使用稀疏的object queries集预测来自LiDAR点云的初始边界框,其第二层解码器自适应地将object queries与有用的图像特征融合,充分利用空间和上下文关系。Transformers的注意力机制使我们的模型能够自适应地决定从图像中获取什么信息和从什么位置获取信息,从而形成一个鲁棒和有效的融合策略。此外,我们还设计了一种图像引导的query初始化策略来处理点云中难以检测的对象。

贡献
在nuScenes和Waymo上,LiDAR-only 方法要比多模态的方法效果好。但是很显然,光靠LiDAR是不够的,有些小物体就几个点,很难识别,但是在高分辨率的图像上还是比较清晰可见的。目前的融合方法粗略分为3类:结果级、提案级和点级。
result-level:FPointNet,RoarNet等,包括 FPointNet 和 RoarNet ,使用2D 检测器来播种 3D proposal,然后使用 PointNet 进行对象定位。
proposal-level:MV3D,AVOD等。由于感兴趣区域通常含有大量的背景噪声,这些粗粒度融合方法的结果并不理想。包括 MV3D和 AVOD,通过在共享proposal的每种模式中应用 RoIPool 在区域proposal级别执行融合。 由于矩形感兴趣区域 (RoI) 通常包含大量背景噪声,因此这些粗粒度融合方法的结果并不令人满意。
point-level :分割分数:PointPainting,FusionPainting,CNN特征:EPNet,MVXNet,PointAugmenting等。最近,大多数方法都尝试进行点级融合,效果不错。 首先基于校准矩阵找到 LiDAR points和image pixels之间的硬关联(hard association),然后通过逐点拼接,使用关联像素的分割分数或 CNN 特征来增强 LiDAR 特征。
尽管有了令人印象深刻的改进,这些点级融合方法仍存在两个主要问题:首先,它们通过元素级联或相加将激光雷达特征与图像特征融合,在图像特征质量较低的情况下,性能严重下降。其次,寻找稀疏的LiDAR点与密集的图像像素之间的硬关联,不仅浪费了大量具有丰富语义信息的图像特征,而且严重依赖于两个传感器之间的高质量校准,而由于固有的时空偏差,这种校准往往难以获得。
总的来说就是两个问题:(1)图像特征的质量无法保证(2)传感器外参不准,很小的误差会造成对齐失败。
我们的关键思想是重新定位融合过程的重点,从硬关联到软关联,以导致鲁棒性退化图像质量和传感器不对准。具体来说,我们设计了一种使用两个Transformers解码器层作为检测头的顺序融合方法。我们的第一个解码器层利用稀疏的object queries集来根据LiDAR特性生成初始的边界框。与2D中独立于输入的对象查询[2,45]不同,我们使对象查询具有输入依赖性和类别感知性,从而使查询具有更好的位置和类别信息。接下来,第二个变压器解码器层自适应融合对象查询与有用的图像特征相关的空间和上下文关系。我们利用局域诱导偏差,在初始边界框周围对交叉注意进行空间约束,以帮助网络更好地访问相关位置。我们的融合模块不仅为目标查询提供了丰富的语义信息,而且由于激光雷达点与图像像素之间的关联是一种软的、自适应的方式,因此对较差的图像条件具有更强的鲁棒性。最后,针对点云中难以检测的对象,引入了图像引导的查询初始化模块,在查询初始化阶段引入了图像引导。贡献:
(1)我们的研究探讨了并揭示了鲁棒融合的一个重要方面,即软关联机制。
(2)我们提出了一种新的基于Transformers的激光雷达-摄像机融合模型用于三维检测,该模型细致地进行了粗粒度融合,对退化的图像质量和传感器不对中显示了卓越的鲁棒性。
(3)我们介绍了几个简单而有效的调整对象查询,以提高质量的初始边界框预测的图像融合。图像引导的查询初始化模块也被设计用来处理点云中难以检测到的对象
方法
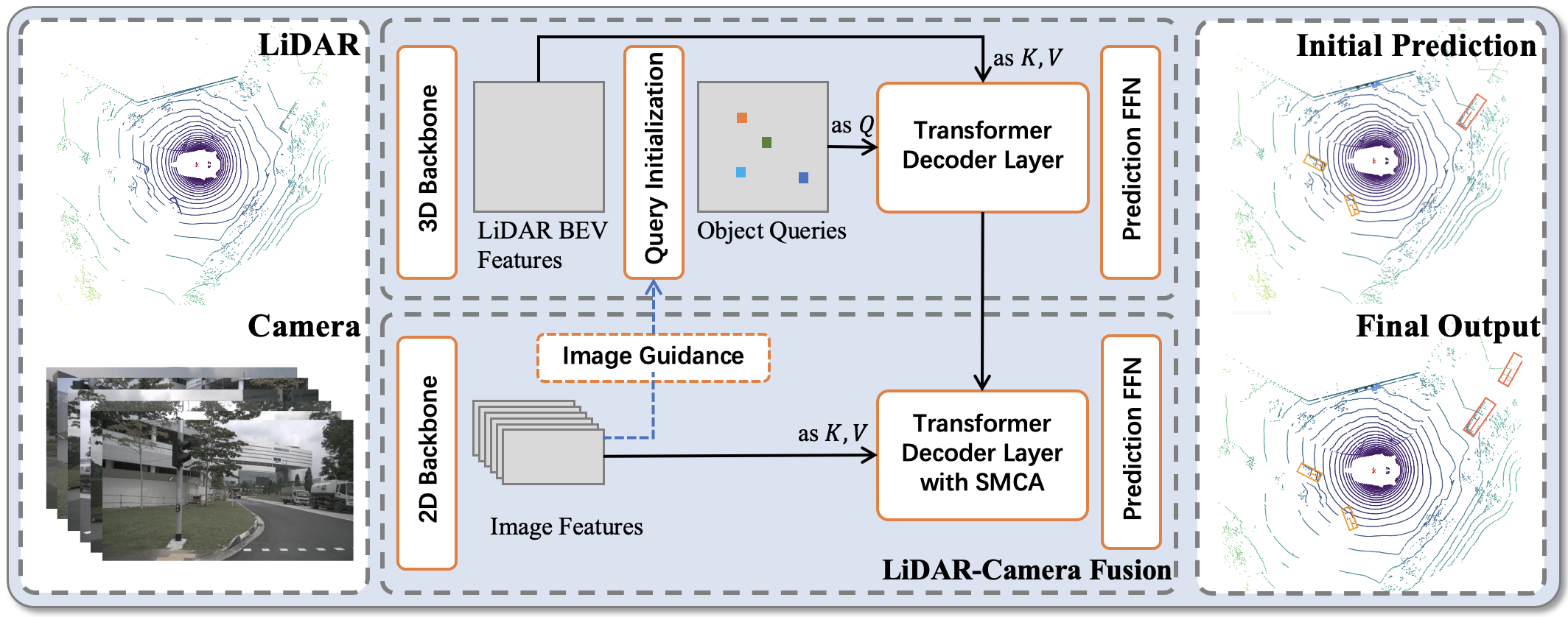
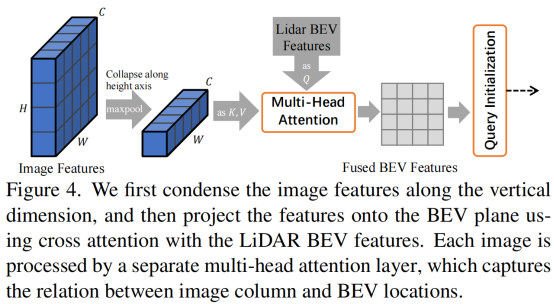
如上图所示,给定一个LiDAR BEV feature map和image feature map,我们的基于Transformer的检测头首先利用LiDAR信息将Object query解码为初始的边界框预测,然后通过注意力机制将Object query与有用的图像特征融合,进行LiDAR-camera融合。
3.1. Preliminary: Transformer for 2D Detection

DETR
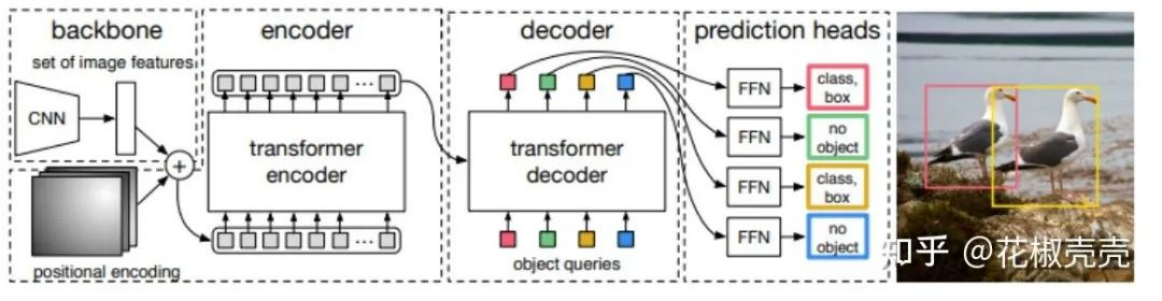
从DETR开始,Transformer开始被大量用到目标检测中。DETR使用了一个CNN提取图像特征,并使用Transformer架构将一小组学习到的embeddings(称为object queries)转换为一组预测。后续有一些方法给object queries进一步加入了位置信息。在我们的工作中,每个object queries包含一个提供对象定位的query position和一个query feature 编码实例信息,如框的大小、方向等。
3.2. Query Initialization
Input-dependent. 在开创性的著作[2,45,71]中,query position作为网络参数随机生成或学习,而与输入的数据无关。这种独立于输入的query position需要额外的阶段(解码器层)来为他们的模型[2,71]学习向真实对象中心移动的过程。最近,在二维目标检测[57]中发现,通过更好的object queries初始化,可以弥补1层结构和6层结构之间的差距。受此启发,我们提出了一种基于center heatmap的输入相关初始化策略,以实现仅使用一个解码层的竞争性能。
具体而已,给定一个XYD的LiDAR BEV特征,我们首先预测一个特定类的热图,X*Y*K,XY是特征图的尺寸,K是种类数量。然后,我们将热图看作X × Y × K对象候选,并选择所有类别的前n个候选对象作为我们的初始object queries。为了避免空间过于封闭的查询,在[66]之后,我们选择局部最大元素作为我们的对象查询,其值大于或等于它们的8个连接的邻居。否则,需要大量queries覆盖BEV平面。所选候选对象的位置和特征用于初始化query positions 和 query features。这样,我们的初始对象查询将位于或接近潜在的对象中心,消除多个解码器层来细化位置的需要。
Category-aware. BEV平面上的物体均为绝对尺度,同一类别之间的尺度方差较小。为了利用这些属性更好地进行多类检测,我们通过为每个object queries类别嵌入,使object queries具有类别感知性。具体地说,使用每个被选中候选的类别(例如Sˆijk属于第k个类别),我们通过将一个热门类别向量线性投影到Rd向量产生的类别嵌入,明智地对查询特征进行元素求和。类别嵌入具有两个方面的优点:一方面,它可以作为建模自注意模块中对象-对象关系和交叉注意模块中对象-上下文关系的有用边信息;另一方面,在预测时,它可以传递对象有价值的先验知识,使网络关注于类别内的方差,从而有利于属性预测。
3.3. Transformer Decoder and FFN
解码结构遵循DETR,object queries与特征映射(点云或图像)之间的交叉注意将相关上下文聚集到候选对象上,而object queries之间的自注意导致了不同候选对象之间的成对关系。query positions通过多层感知器(MLP)嵌入到d维位置编码中,并根据查询特征逐一的地进行元素求和。这使得网络能够同时对上下文和位置进行推理。
N个包含丰富实例信息的object queries被前馈网络(FFN)独立地解码为方框和类标签。从object queries预测的有中心点偏移,log(l),log(w),log(h).偏航角sin(α), cos(α) ,x,y方向的速度,我们还预测了一个类概率。每个属性由一个单独的两层1×1卷积计算。通过并行地将每个object queries解码为预测,我们得到一组预测{ˆbt, pˆt}N t作为输出,其中ˆbt是第i个查询的预测边界框。类似3DETR,我们采用了辅助解码机制,在每个解码器层后增加了FFN和监督(即每一个解码层算一个LOSS)。因此,我们可以从第一解码器层得到初始的边界盒预测。我们在LiDAR-camera融合模块中利用这些初始预测来约束交叉注意,如下一节所述。
3.4. LiDAR-Camera Fusion
图像特征提取 我们没有基于激光雷达点与图像像素之间的硬关联来获取多视图图像特征。相反,我们保留所有图像特征FC∈RNv×H×W ×d作为我们的存储库,并利用Transformer解码器中的交叉注意机制,以稀疏密集、自适应的方式进行特征融合。
SMCA for Image Feature Fusion
为了降低硬关联策略对传感器标定的敏感性和图像特征的劣等性,我们利用交叉注意机制建立LiDAR与图像之间的软关联,使网络能够自适应地确定从图像中获取什么信息和什么位置。
受到[9]的启发,我们设计了一个空间调制交叉注意(SMCA)模块,该模块通过一个二维圆形高斯掩模来衡量交叉注意,该模块围绕着每个查询的投影2D中心(仅利用点云的预测结果根据外参投影到图像上)。二维高斯权值掩码M的生成方法与CenterNet类似。然后这个权重图与所有注意力头之间的交叉注意图相乘。这样,每个object queries只关注投影2D框周围的相关区域,这样网络就可以根据输入的LiDAR特征更好更快地学习到选择哪些图像特征。注意力图如下图3所示。
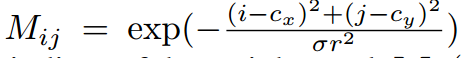

该网络通常倾向于关注接近对象中心的前景像素,忽略无关像素,为对象分类和边界框回归提供了有价值的语义信息。在SMCA之后,我们使用另一个FFN,使用包含LiDAR和图像信息的object queries来产生ffinal bound box预测。
3.5. Label Assignment and Losses
参照DETR,我们发现预测对象与真实对象之间的二部匹配匈牙利算法[13]。
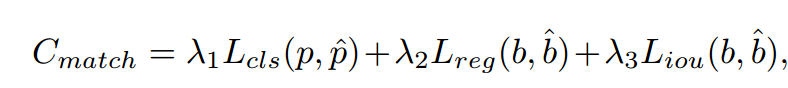
3.6. Image-Guided Query Initialization
因为我们的对象查询目前只使用激光雷达的特点,它可能导致次优的检测召回率。从经验来看,我们的模型已经实现了高召回率,并在基线上显示了优越的性能(第5节)。然而,为了进一步利用高分辨率图像的能力来检测小目标,并使我们的算法在稀疏情况下更鲁棒激光雷达点云,我们提出了一个图像引导查询初始化策略。利用LiDAR和相机信息选择object queries。
实验
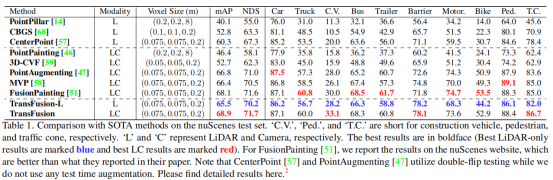
本文主要在nuScenes、Waymo Open两个数据集上进行了实验分析。在nuScenes上的实验结果如上表所示,如表1所示,我们的TransFusion-L已经显著优于最先进的激光雷达方法(+5.2%mAP,+2.9%NDS),甚至超过了一些多模态方法。我们将这种性能增益归因于Transformer解码器的关系建模能力以及所提出的查询初始化策略。
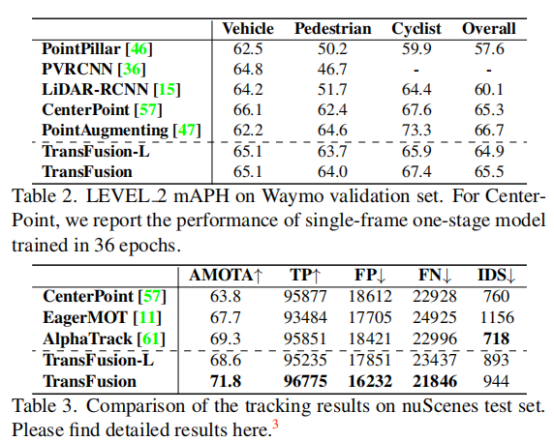
作者在表2中报告了在Waymo验证集上,本文的模型在所有三个类上的性能。其中,融合策略将行人和自行车班的mAPH分别提高了0.3倍和1.5倍。我们怀疑由图像组件所带来的相对较小的改进有两个原因。首先,图像的语义信息可能对Waymo的粗粒度分类的影响较小。其次,来自第一个解码器层的初始边界盒已经具有精确的位置,因为Waymo中的点云比其他场景中的更密集。如表3所示,我们的模型显著优于中心点,并在nuScenes跟踪的排行榜上设置了新的最先进的结果。
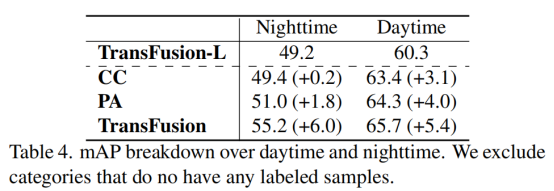
作者首先根据nuScenes提供的场景描述将验证集分为白天和夜间,并在表4中显示了不同情况下的性能增益。我们的方法在夜间带来了一个更大的性能提高,其中较差的光照会对基于硬关联的融合策略CC和PA产生负面影响。
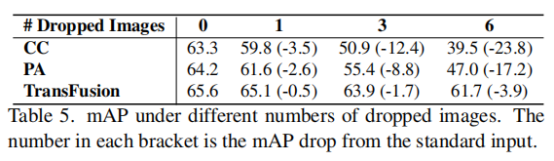
如表5所示,与其他融合方法相比,TransFusion具有更好的鲁棒性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢