
论文标题:Inverted Pyramid Multi-task Transformer for Dense Scene Understanding
论文链接:https://arxiv.org/abs/2203.07997
代码链接:https://github.com/prismformore/InvPT
作者单位:香港科技大学
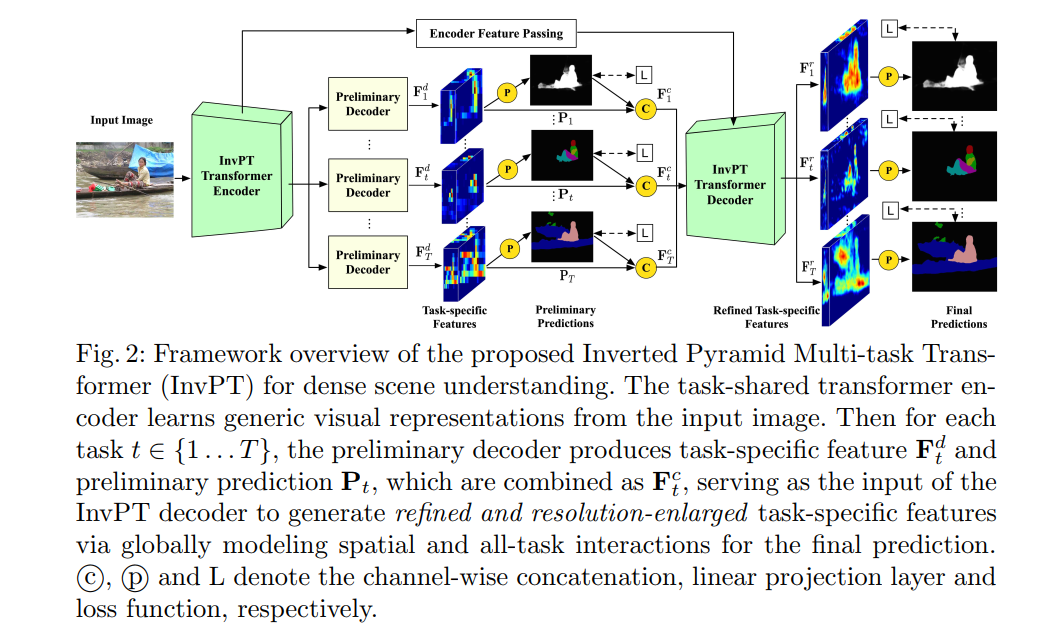
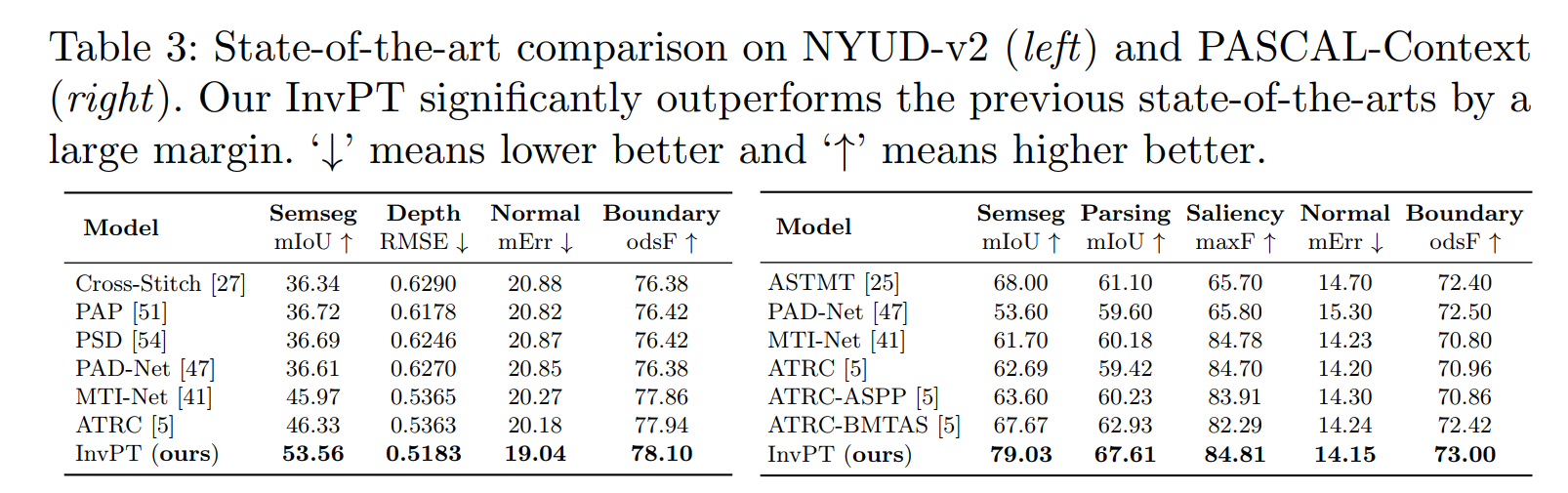
多任务密集场景理解是一个蓬勃发展的研究领域,需要对一系列相关任务同时进行感知和推理,并进行逐像素预测。由于卷积操作的大量使用,大多数现有工作在局部建模中遇到了严重的限制,而在全局空间位置和多任务上下文中学习交互和推理对于这个问题至关重要。在本文中,我们提出了一种新颖的端到端倒金字塔多任务(InvPT)Transformer,以在统一的框架中同时对空间位置和多个任务进行建模。据我们所知,这是第一项探索设计用于多任务密集预测以进行场景理解的Transformer结构的工作。此外,广泛证明更高的空间分辨率对密集预测非常有利,而由于大空间尺寸的巨大复杂性,现有的Transformer以更高的分辨率更深是非常具有挑战性的。 InvPT 提出了一个高效的 UP-Transformer 模块,以逐渐增加的分辨率学习多任务特征交互,它还结合了有效的自注意消息传递和多尺度特征聚合,以产生高分辨率的任务特定预测。我们的方法分别在 NYUD-v2 和 PASCAL-Context 数据集上实现了卓越的多任务性能,并且显着优于以前的最新技术。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢