
作者:Benyou Wang, Xiangbo Wu, Xiaokang Liu,等
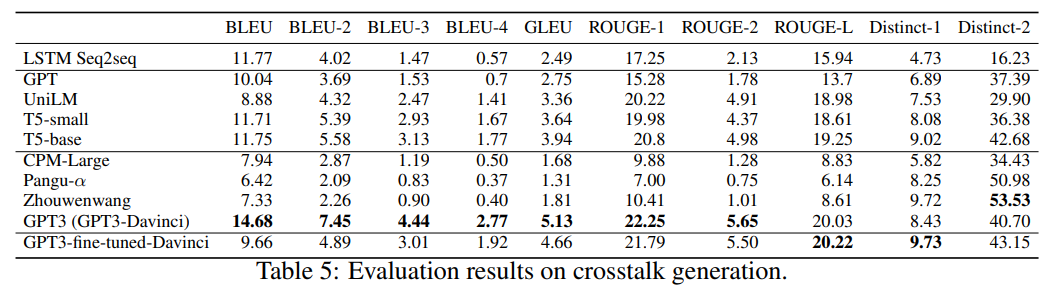
简介:语言是人类交流的主要工具,其中幽默是最吸引人的部分之一。使用计算机生成像人类一样的自然语言,也就是自然语言生成 (NLG),已广泛用于对话系统、聊天机器人、机器翻译以及计算机辅助创建,例如创意生成、脚本编写。然而,自然语言的幽默方面研究相对较少,尤其是在预训练语言模型的时代。在这项工作中,作者旨在初步测试 NLG 是否可以像人类一样产生幽默。作者建立了一个新的数据集,其中包含大量数字化的中国相声脚本(称为 C3简而言之),这是一种自 1800 年代以来流行的中国表演艺术,称为“相声”。(为了方便非中文使用者,作者在本文中将“Xiangsheng”称为“crosstalk”。)作者对各种生成方法进行了基准测试,包括从头开始训练的 Seq2seq、微调的中规模 PLM 和大规模 PLM(有和没有微调)。此外,作者还进行了人工评估,表明 1)大规模预训练大大提高了串扰生成质量;2) 即使是从最好的 PLM 生成的脚本也与我们的预期相去甚远,只有 65% 的人为串扰质量。作者得出结论:使用大规模 PLM 可以大大改善幽默的生成,但仍处于起步阶段。

论文下载:https://arxiv.org/pdf/2207.00735.pdf
数据和基准测试代码的下载地址:https://github.com/anonNo2/crosstalk-generation
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢