【标题】Advancing protein language models with linguistics: a roadmap for improved interpretability
【作者团队】Mai Ha Vu, Rahmad Akbar, Philippe A. Robert, Bartlomiej Swiatczak, Victor Greiff, Geir Kjetil Sandve, Dag Trygve Truslew Haug
【发表时间】2021/07/03
【机 构】奥斯陆大学等
【论文链接】https://arxiv.org/ftp/arxiv/papers/2207/2207.00982.pdf
基于深度神经网络的语言模型(LMs)被越来越多地应用于大规模的蛋白质序列数据,以预测蛋白质的功能。然而由于其主要是黑箱模型,因此在解释上具有挑战性,目前的蛋白质LM方法并没有对序列-功能关系的基本理解,阻碍了基于规则的治疗药物开发。本文认为,从语言学,一个专门从自然语言数据中提取分析性规则的领域,获得的指导可以帮助建立更多学会了相关领域的特定规则的可解释的蛋白质LM。与自然语言LM相比,蛋白质序列数据和语言序列数据之间的差异要求在蛋白质LM中整合更多特定领域的知识。本文提供了一个基于语言学的蛋白质LM选择路线图,涉及训练数据、标记化、标记嵌入、序列嵌入和模型解释。将语言学与蛋白质LM相结合,可以开发出下一代可解释的机器学习模型,并有可能揭示出序列-功能关系背后的生物机制。
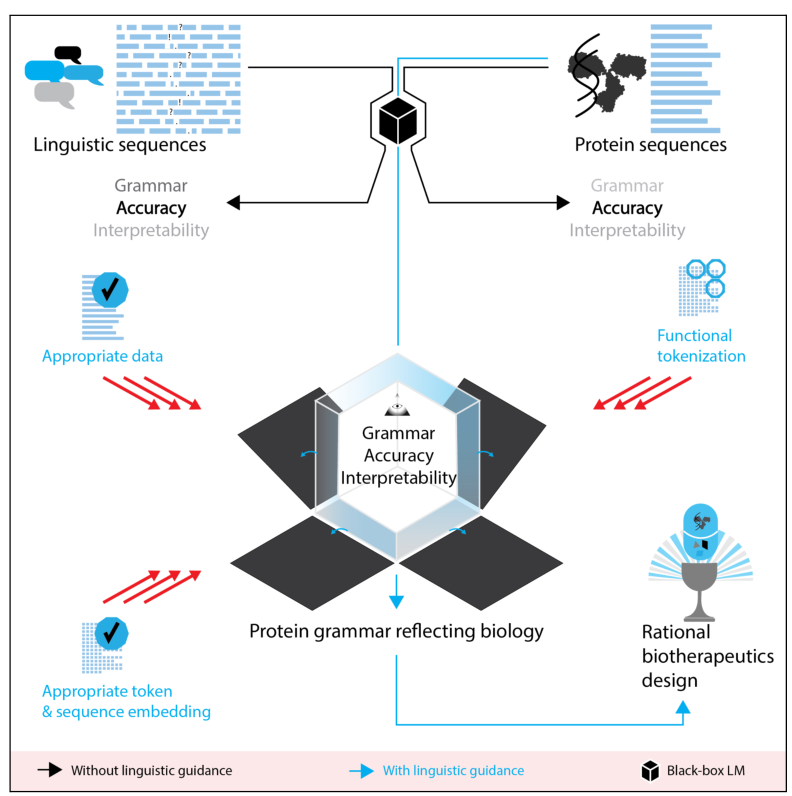
蛋白质和自然语言序列之间的相似性激发了对蛋白质序列的LMs的使用,LMs最初是对语言序列进行建模的工具。自监督的蛋白质LMs有可能识别相关的序列规则,并进一步进行实验测试,从而有助于解决生物研究中的基本问题,并加速合理的蛋白质治疗设计。然而,目前在设计和构建蛋白质LM的实践中,由于缺乏对这些模型最初是如何为语言序列建模而构建的深入了解,因此未能将这些模型恰当地适应于蛋白质序列。本文强调了LM流程的各个部分(预训练数据、tokenization、标记嵌入、序列嵌入和规则提取),并展示了理解这些步骤中每个步骤所依据的原始语言学意图如何能够为建立更合适的蛋白质LM提供信息,以回答下游感兴趣的具体问题。经过深思熟虑纳入每一点所讨论的考虑因素的蛋白质LM,就更有可能学到它们所模拟的序列的相关生物规则,因此可能更适合于成功的规则提取,可以用来进行合理的蛋白质设计。
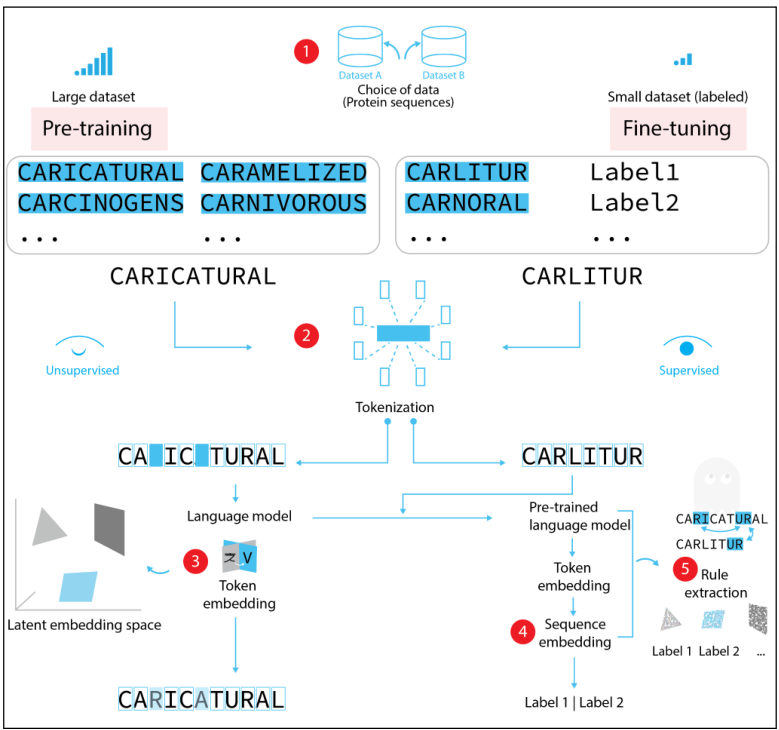
在一个蛋白质序列例子上广泛使用的深度LM流程概述。
- 1图:一个ML架构以自监督的方式进行预训练(预训练),与大型测序数据的相关任务无关(1)。随后,添加了层的预训练模型被训练来执行感兴趣的任务,例如,分类(微调)。
- 2图:微调可能涉及到需要监督的任务,因此需要标记(如蛋白质功能、疾病、临床结果)和较小的数据集。这两个步骤都需要Tokenization,将序列分割成离散的元素,通常是单一的AA,由于缺乏任务信息或生物学意义上的标记。
- 3图:预训练给token分配一个嵌入,代表它们在语言中的上下文使用。
- 4图表示在微调期间,标记嵌入被利用,如果微调任务是一种基于序列的预测形式,则计算序列嵌入。
- 5图表示到目前为止,对微调模型的解释仍处于初始阶段,这将使序列功能规则的发现成为可能,如功能相关的长距离依赖。
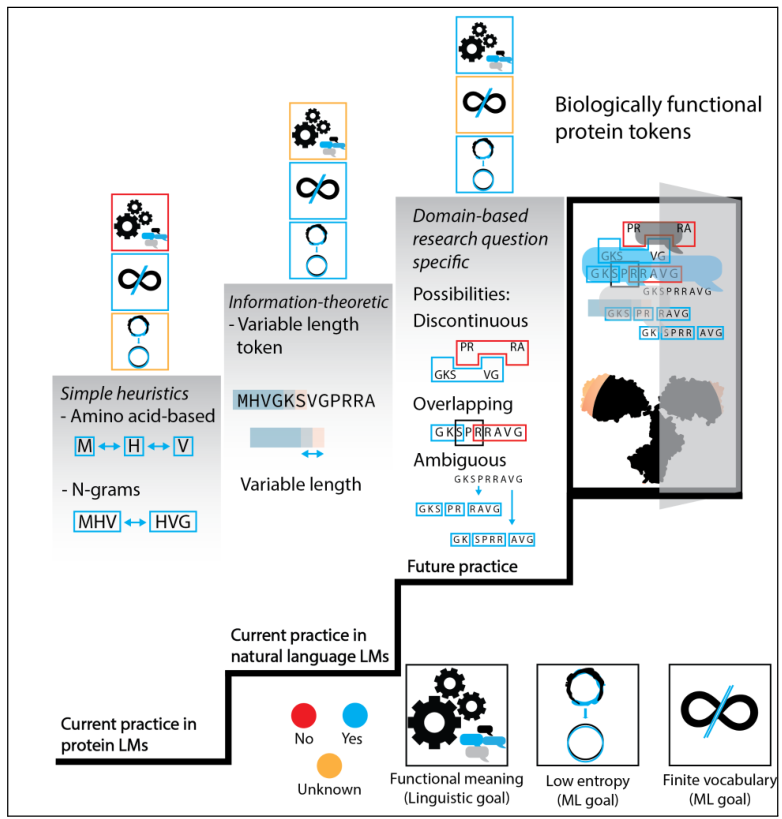
将蛋白质序列token化从目前流行的简单启发式方法推进到复杂的方法,从而产生类似于自然语言中语言学意义上的蛋白质token的生物学功能。标记化方法必须平衡三个不同的目标。语言上健全的token应该原子化地映射到定义明确的、抽象的功能意义。由于ML的技术限制,生成的可能标记集必须是有限的、数量少的(即有限词汇量),而且tokenization产生的LM在固定的词汇量下具有低熵。
目前,蛋白质LM的做法是使用简单的启发式方法,产生基于单个氨基酸或n-grams的标记。虽然这种简单的启发式方法产生了有限的、小的词汇量,但它们并没有映射到功能意义上,也不清楚生成的LM熵有多低。信息论的tokenization方法更复杂一步,目前在自然语言LM中很流行。它们的结果也是有限的,虽然比简单的启发式方法的词汇量要大,而且它们产生的LM的熵很低,但是它们是否会映射到蛋白质的功能意义上还不清楚。
最后,最复杂的方法是基于领域的tokenization,是针对研究问题的。这种方法产生的token与定义明确的功能意义相对应,但有可能导致一个任意大的、实际上非无限的词汇。它们仍然应该产生低熵的LM。基于领域的token如何表现还有待观察,但它们可能是不连续的、重叠的,而且它们可能是模糊的,这意味着对于一个给定的序列可能有多种可能的分割。基于领域的tokenization最接近于生物学上的蛋白质token,类似于自然语言中的语言学定义的token。
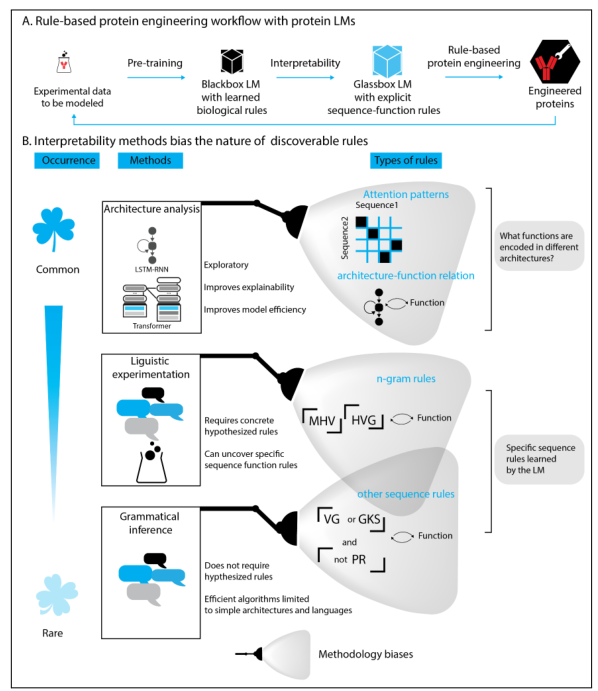
为模拟适当的实验数据而预先训练的黑盒蛋白质LM有望学习预先训练数据中的生物序列功能规则。
规则和模式提取方法可以提高LM的可解释性和可解释性,从而形成一个具有可解释序列功能规则的玻璃盒LM。然后,序列功能规则可以被用于蛋白质工程。经过实验验证的工程蛋白有可能被添加到训练数据中,以改善蛋白质LM。
可解释性方法对可发现规则的性质有偏差。不同的可解释性方法突出了关于结构和序列的不同类型的信息。
- 架构分析是目前蛋白质LM最常用的方法,用于解释黑箱LM,但它大多只能产生对架构本身的更好理解,而不是必要的具体序列功能规则。然而,对架构的更好理解对于提高模型的可解释性和效率是非常有用的。
- 语言学启发的实验,旨在通过用遵循或违反假设规则的手工制作的序列来测试,找到已知规则和LM之间的相关性。语言学启发的实验需要一个具体的假设规则(通常基于预先存在的分析),由于所有可能规则的巨大空间,这对蛋白质序列来说可能是不可行的。旨在研究各种深度神经网络架构能够学习的规则类型的研究可以提供一种方法来限制规则的搜索空间,尽管这些限制可能仍然不足以限制详尽的规则提取。
- 深度神经网络的语法推理方法,可以提取预定功率的规则不需要具体规则的先验假设,但高效的算法截至目前仅限于较简单的架构(如RNNs),还不能实际适用于更大规模的规则提取。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢