
我们知道,batch size 决定了深度学习训练过程中,完成每个 epoch 所需的时间和每次迭代(iteration)之间梯度的平滑程度。batch size 越大,训练速度则越快,内存占用更大,但收敛变慢。
又有一些理论说,GPU 对 2 的幂次的 batch 可以发挥更好性能,因此设置成 16、32、64、128 … 时,往往要比设置为其他倍数时表现更优。
后者是否是一种玄学?似乎很少有人验证过。最近,威斯康星大学麦迪逊分校助理教授,著名机器学习博主 Sebastian Raschka 对此进行了一番认真的讨论。

Sebastian Raschka
关于神经网络训练,我认为我们都犯了这样的错误:我们选择批量大小为 2 的幂,即 64、128、256、512、1024 等等。(这里,batch size 是指当我们通过基于随机梯度下降的优化算法训练具有反向传播的神经网络时,每个 minibatch 中的训练示例数。)
据称,我们这样做是出于习惯,因为这是一个标准惯例。这是因为我们曾经被告知,将批量大小选择为 2 的幂有助于从计算角度提高训练效率。
这有一些有效的理论依据,但它在实践中是如何实现的呢?在过去的几天里,我们对此进行了一些讨论,在这里我想写下一些要点,以便将来参考。我希望你也会发现这很有帮助!
理论背景
在看实际基准测试结果之前,让我们简要回顾一下将批大小选择为 2 的幂的主要思想。以下两个小节将简要强调两个主要论点:内存对齐和浮点效率。
内存对齐
选择批大小为 2 的幂的主要论据之一是 CPU 和 GPU 内存架构是以 2 的幂进行组织的。或者更准确地说,存在内存页的概念,它本质上是一个连续的内存块。如果你使用的是 macOS 或 Linux,就可以通过在终端中执行 getconf PAGESIZE 来检查页面大小,它应该会返回一个 2 的幂的数字。
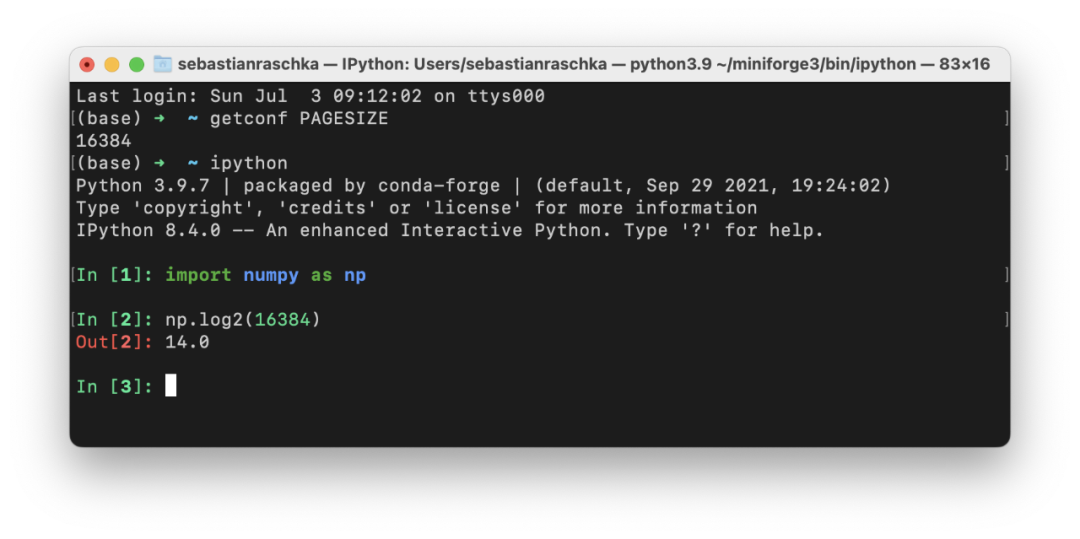
这个想法是将一个或多个批次整齐地放在一个页面上,以帮助 GPU 并行处理。或者换句话说,我们选择批大小为 2 以获得更好的内存对齐。这与在视频游戏开发和图形设计中使用 OpenGL 和 DirectX 时选择二次幂纹理类似。
矩阵乘法和 Tensor Core
再详细一点,英伟达有一个矩阵乘法背景用户指南,解释了矩阵尺寸和图形处理单元 GPU 计算效率之间的关系。因此,本文建议不要将矩阵维度选择为 2 的幂,而是将矩阵维度选择为 8 的倍数,以便在具有 Tensor Core 的 GPU 上进行混合精度训练。不过,当然这两者之间存在重叠:

为什么会是 8 的倍数?这与矩阵乘法有关。假设我们在矩阵 A 和 B 之间有以下矩阵乘法:
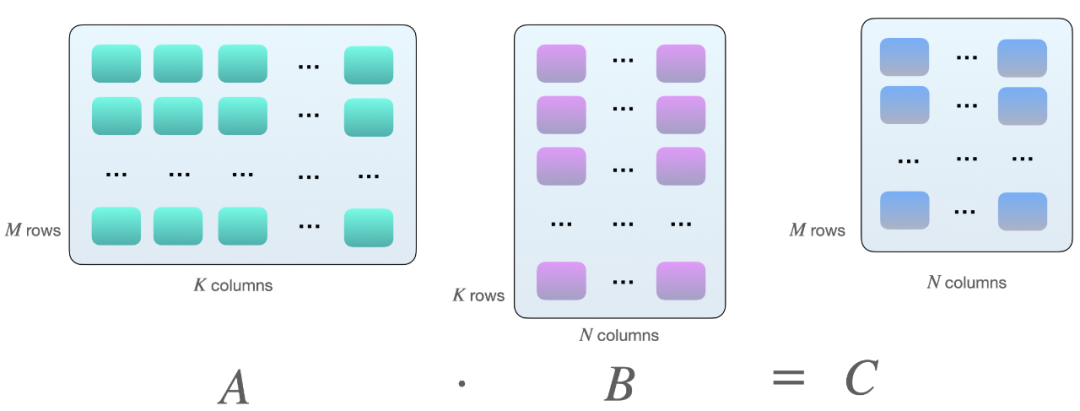
将两个矩阵 A 和 B 相乘的一种方法,是计算矩阵 A 的行向量和矩阵 B 的列向量之间的点积。如下所示,这些是 k 元素向量对的点积:
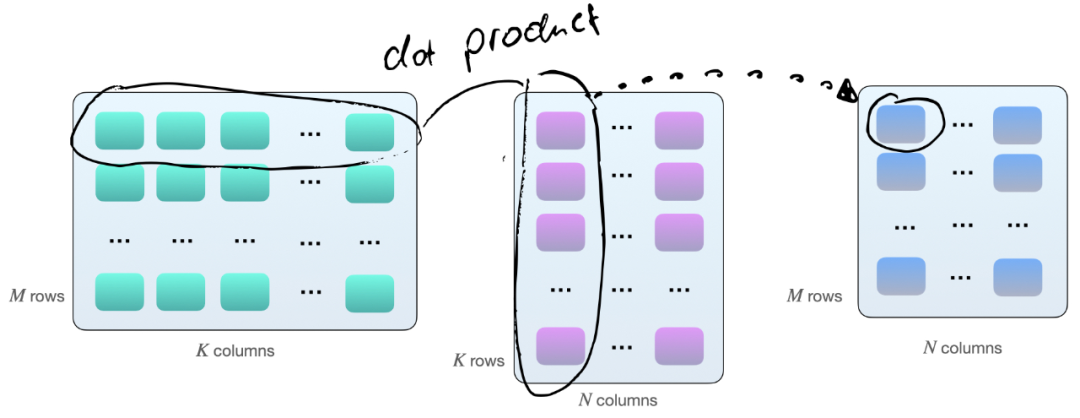
每个点积由一个「加」和一个「乘」操作组成,我们有 M×N 个这样的点积。因此,共有 2×M×N×K 次浮点运算(FLOPS)。不过需要知道的是:现在矩阵在 GPU 上的乘法并不完全如此,GPU 上的矩阵乘法涉及平铺。
如果我们使用带有 Tensor Cores 的 GPU,例如英伟达 V100,当矩阵维度 (M、N 和 K)与 16 字节的倍数对齐(根据 Nvidia 的本指南)后,在 FP16 混合精度训练的情况下,8 的倍数对于效率来说是最佳的。
通常,维度 K 和 N 由神经网络架构决定(尽管如果我们自己设计还会有一些回旋余地),但批大小(此处为 M)通常是我们可以完全控制的。
因此,假设批大小为 8 的倍数在理论上对于具有 Tensor Core 和 FP16 混合精度训练的 GPU 来说是最有效的,让我们研究一下在实践中可见的差异有多大。
简单的 Benchmark
为了解不同的批大小如何影响实践中的训练,我运行了一个简单的基准测试,在 CIFAR-10 上训练 MobileNetV3 模型 10 个 epoch—— 图像大小调整为 224×224 以达到适当的 GPU 利用率。在这里,我使用 16 位原生自动混合精度训练在英伟达 V100 卡上运行训练,它更有效地使用了 GPU 的张量核心。
如果想自己运行它,代码可在此 GitHub 存储库中找到:https://github.com/rasbt/b3-basic-batchsize-benchmark
小 Batch Size 基准
我们从批大小为 128 的小基准开始。「训练时间」对应于在 CIFAR-10 上训练 MobileNetV3 的 10 个 epoch。推理时间意味着在测试集中的 10k 图像上评估模型。
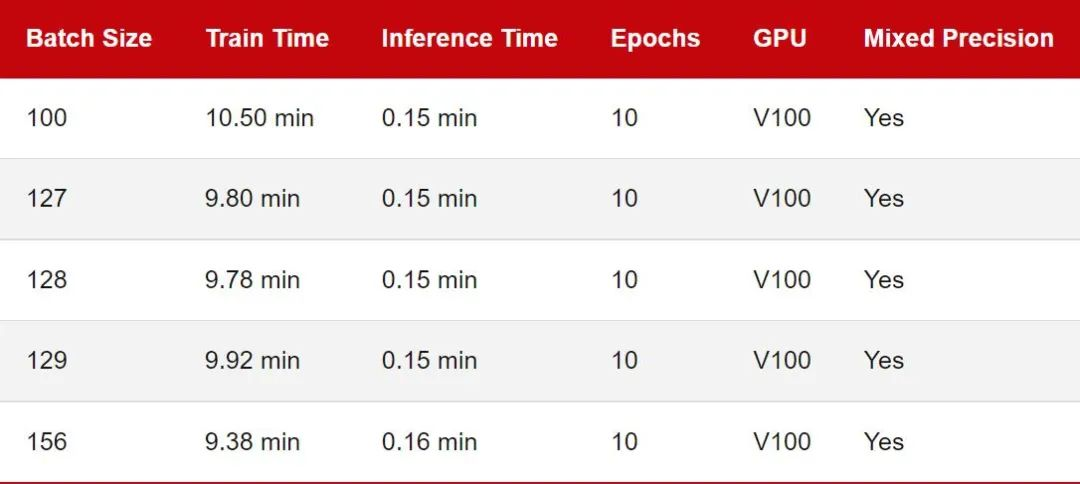
查看上表,让我们将批大小 128 作为参考点。似乎将批量大小减少一 (127) 或将批量大小增加一 (129) 确实会导致训练性能减慢。但这里的差异看来很小,我认为可以忽略不计。
将批大小减少 28 (100) 会导致性能明显下降。这可能是因为模型现在需要处理比以前更多的批次(50,000 / 100 = 500 对比 50,000 / 100 = 390)。可能出于类似的原因,当我们将批大小增加 28 (156) 时就可以观察到更快的训练时间。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢