
目前CV领域中包括两种典型的训练模式,第一种是传统的图像分类训练,以离散的label为目标,人工标注、收集干净、大量的训练数据,训练图像识别模型。第二种方法是最近比较火的基于对比学习的图文匹配训练方法,利用图像和其对应的文本描述,采用对比学习的方法训练模型。这两种方法各有优劣,前者可以达到非常高的图像识别精度、比较强的迁移能力,但是依赖人工标注数据;后者可以利用海量噪声可能较大的图像文本对作为训练数据,在few-shot learning、zero-shot learning上取得很好的效果,但是判别能力相比用干净label训练的方法较弱。今天给大家介绍一篇CVPR 2022微软发表的工作,融合两种数据的一个大一统对比学习框架。

论文题目:Unified Contrastive Learning in Image-Text-Label Space
下载地址:https://arxiv.org/pdf/2204.03610.pdf
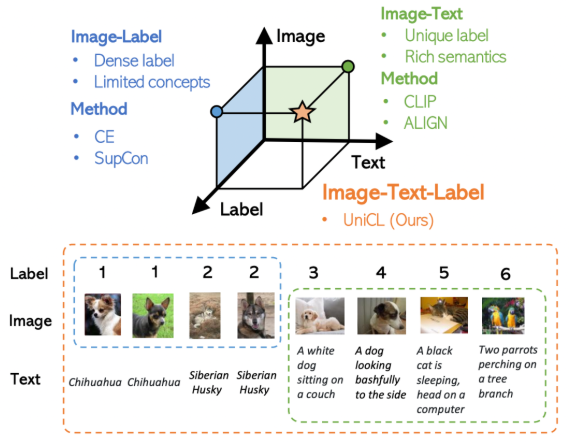
CVPR 2022微软发表的这篇工作,希望同时利用图像、文本、label三者的信息,构建一个统一的对比学习框架,同时利用两种训练模式的优势。下图反映了两种训练模式的差异,Image-Label以离散label为目标,将相同概念的图像视为一组,完全忽视文本信息;而Image-Text以图文对匹配为目标,每一对图文可以视作一个单独的label,文本侧引入丰富的语义信息。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢