
【标题】Robust optimal well control using an adaptive multi-grid reinforcement learning framework
【作者团队】Atish Dixit, Ahmed H. ElSheikh
【发表日期】2022.7.7
【论文链接】https://arxiv.org/pdf/2207.03253.pdf
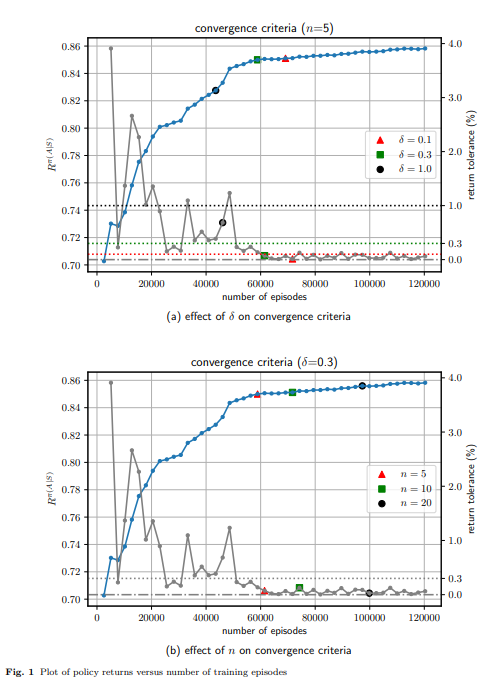
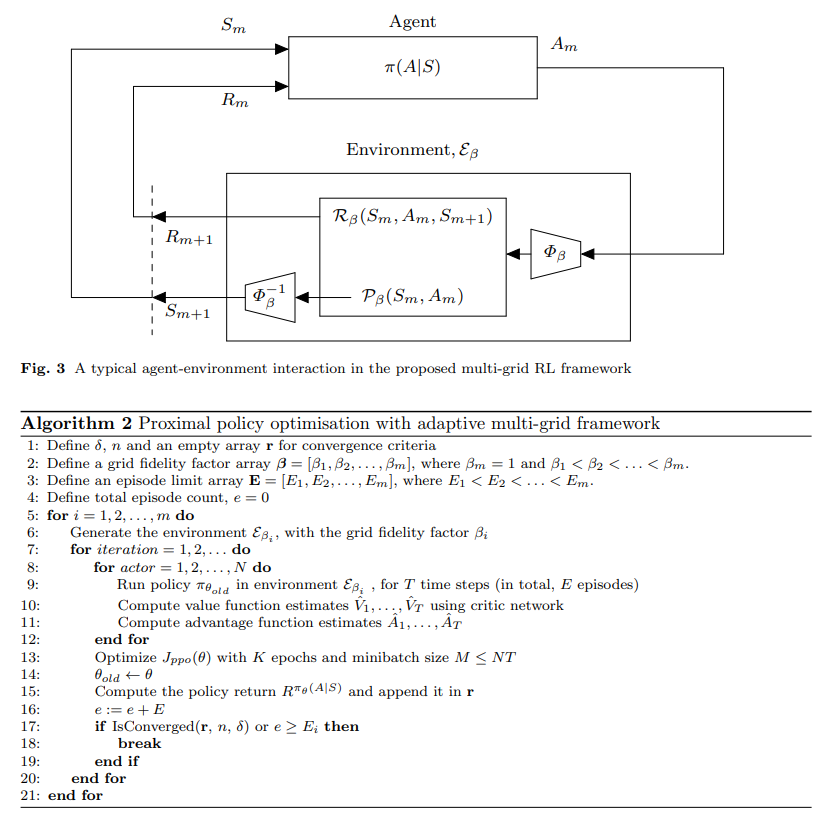
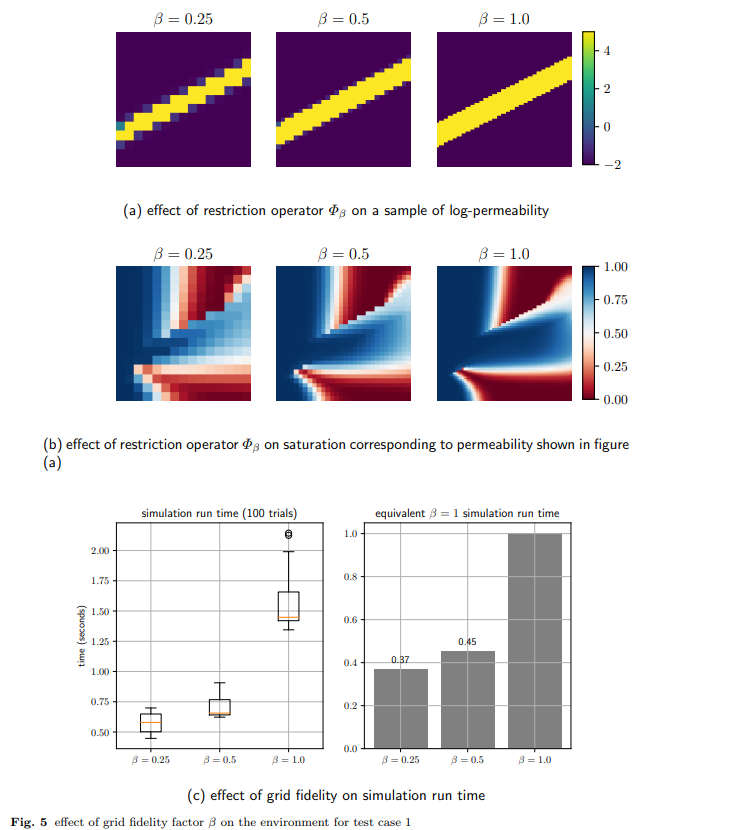
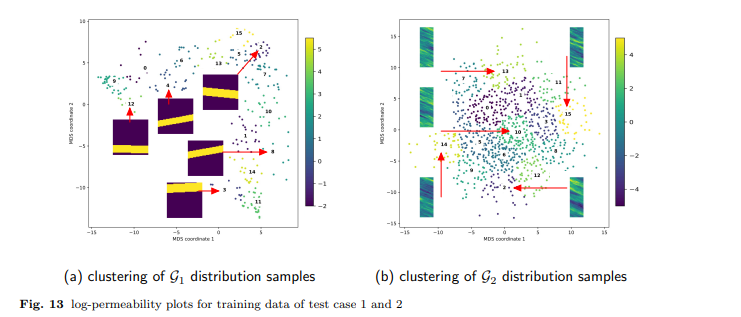
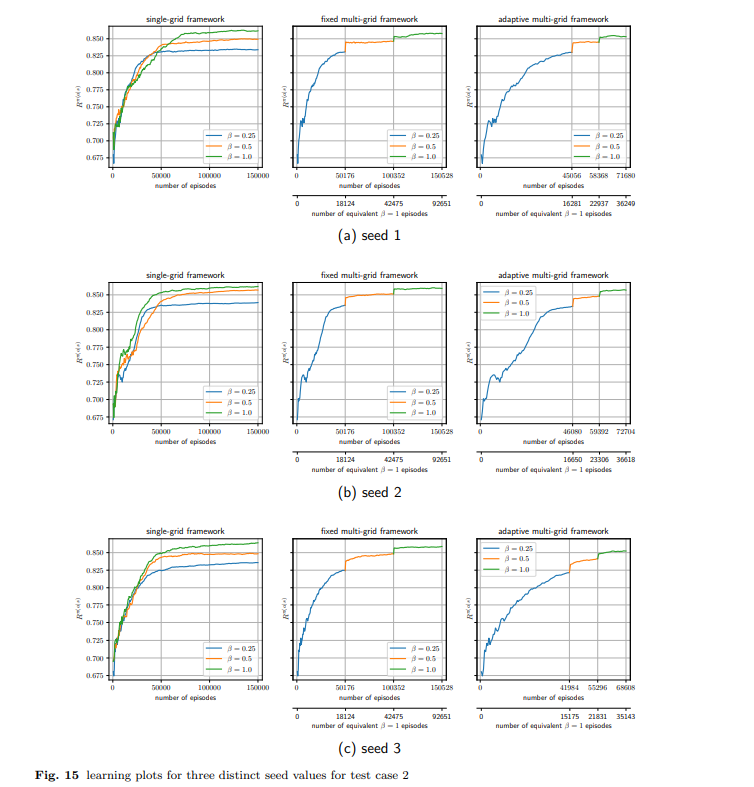
【推荐理由】强化学习是一种很有前景的工具,用于解决模型参数高度不确定、系统在实践中部分可观测的鲁棒最优井控问题。然而,鲁棒控制策略的RL通常依赖于执行大量仿真。对于计算密集型模拟的情况,这很容易变得难以计算。为此,受迭代数值算法中使用的几何多重网格方法原理的启发,引入了一种自适应多重网格RL框架。RL控制策略最初是通过使用底层偏微分方程(PDE)的粗网格离散化进行计算高效的低保真度仿真来学习的。随后,模拟保真度以自适应方式提高到最高保真度模拟,该模拟对应于模型域的最佳离散化。该框架使用最先进的、基于无模型策略的RL算法,即近端策略优化(PPO)算法进行了演示。结果显示了从SPE-10模型2基准案例研究中获得的鲁棒最优井控问题的两个案例研究。使用该框架,计算效率显著提高,节省了单个精细网格对应物60-70%的计算成本。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢