
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:生物科学领域应用深度学习的进展和开放挑战、黎曼扩散薛定谔桥、预训练也有助于贝叶斯优化、基于随机细化的图像去模糊、面向神经机器翻译的去噪实体预训练、基于张量网络的机器学习、开放世界半监督学习新类发现学习、扩散驱动的测试时自适应、序列DeepFake操纵的检测和恢复
1、[LG] Current progress and open challenges for applying deep learning across the biosciences
N Sapoval, A Aghazadeh, M G. Nute, D A. Antunes, A Balaji...
[Rice University & UC Berkeley & University of Houston]
生物科学领域应用深度学习的进展和开放挑战。最近AlphaFold2在从蛋白质序列预测其3D结构方面的成功,突出了迄今为止深度学习在计算生物学中的最有效应用之一。深度学习(DL)允许使用由几层非线性计算单元组成的复杂模型,找到具有多层抽象的数据表示。通过深度学习在各种应用领域的成功观察,使用深度学习的功效取决于专门的神经网络架构的发展,这些架构可以捕获数据的重要属性,如空间定位(卷积神经网络-CNN)、顺序性(循环神经网络-RNN)、上下文依赖(Transformers)和数据分布(autoencoders-AE)。本文讨论了深度学习在五个广泛领域的最新进展、局限性和未来前景:蛋白质结构预测、蛋白质功能预测、基因组工程、系统生物学和数据整合以及系统发育推理。讨论了每个应用领域,涵盖了深度学习方法的主要瓶颈,如训练数据、问题范围、以及在新环境下利用现有深度学习架构的能力。最后,对生物科学领域的深度学习的特定主题和一般挑战进行了总结。
Deep Learning (DL) has recently enabled unprecedented advances in one of the grand challenges in computational biology: the half-century-old problem of protein structure prediction. In this paper we discuss recent advances, limitations, and future perspectives of DL on five broad areas: protein structure prediction, protein function prediction, genome engineering, systems biology and data integration, and phylogenetic inference. We discuss each application area and cover the main bottlenecks of DL approaches, such as training data, problem scope, and the ability to leverage existing DL architectures in new contexts. To conclude, we provide a summary of the subject-specific and general challenges for DL across the biosciences.
https://nature.com/articles/s41467-022-29268-7…




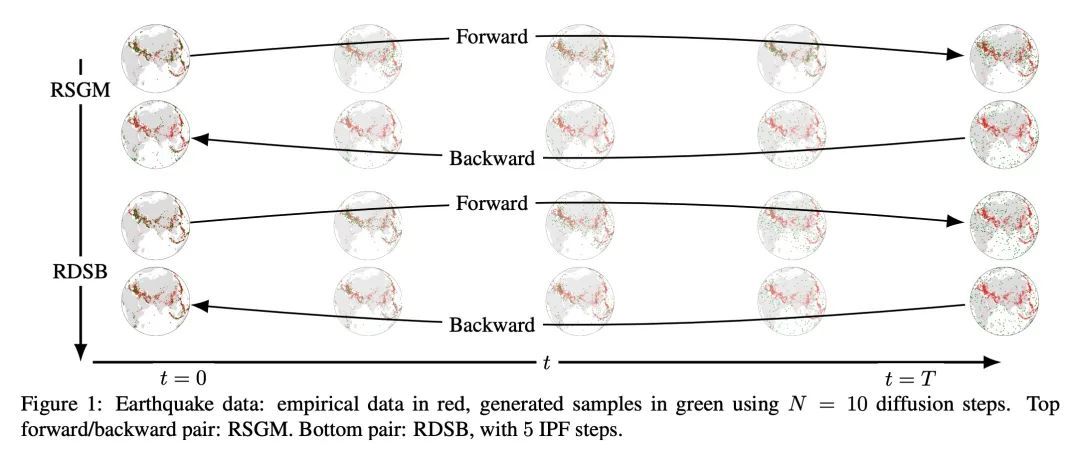
2、[LG] Riemannian Diffusion Schrödinger Bridge
J Thornton, M Hutchinson, E Mathieu, V D Bortoli, Y W Teh, A Doucet
[University of Oxford & PSL University]
黎曼扩散薛定谔桥。基于得分的生成模型在密度估计和生成建模任务上表现出最先进的性能。这些模型通常假设数据的几何形状是平坦的,然而最近的扩展已经被开发出来,以合成黎曼流形上的数据。现有的加速扩散模型采样的方法通常不适用于黎曼设置,基于黎曼分数的方法还没有自适应到数据集插值的重要任务。为了克服这些问题,本文提出黎曼扩散薛定谔桥(Riemannian Diffusion Schrödinger Bridge)。将扩散薛定谔桥推广到非欧几里得环境,并将基于黎曼分数的模型扩展到第一次逆转之后。在合成数据和真实的地球和气候数据上验证了所提出的方法。
Score-based generative models exhibit state of the art performance on density estimation and generative modeling tasks. These models typically assume that the data geometry is flat, yet recent extensions have been developed to synthesize data living on Riemannian manifolds. Existing methods to accelerate sampling of diffusion models are typically not applicable in the Riemannian setting and Riemannian score-based methods have not yet been adapted to the important task of interpolation of datasets. To overcome these issues, we introduce Riemannian Diffusion Schrödinger Bridge. Our proposed method generalizes Diffusion Schrödinger Bridge introduced in (De Bortoli et al., 2021) to the non-Euclidean setting and extends Riemannian score-based models beyond the first time reversal. We validate our proposed method on synthetic data and real Earth and climate data.
https://arxiv.org/abs/2207.03024



3、[LG] Pre-training helps Bayesian optimization too
Z Wang, G E. Dahl, K Swersky, C Lee, Z Mariet, Z Nado, J Gilmer, J Snoek, Z Ghahramani
[Google]
预训练也有助于贝叶斯优化。贝叶斯优化(BO)已经成为许多昂贵现实世界函数全局优化的流行策略。与人们普遍认为BO适合优化黑箱函数相反,实际上需要关于这些函数特征的领域知识才能成功部署BO。这种领域知识通常表现为高斯过程先验,指定了对函数的初始置信。然而,即使有专家知识,选择一个先验也不是一件容易的事。这对于复杂的机器学习模型的超参数调优问题来说尤其如此,调优目标的地貌往往难以理解。本文寻求一种替代性的做法来设置这些函数先验。所考虑的情况是,有类似函数的数据,允许预训练一个更严格的分布。为了在现实的模型训练设置中验证所提出的方法,本文收集了一个大型的多任务超参数调调优据集,在流行的图像和文本数据集以及蛋白质序列数据集上训练了几万个接近最先进的模型配置。实验结果表明,平均而言,所提出方法能比最好的竞争方法至少更有效3倍地找到好的超参数。
Bayesian optimization (BO) has become a popular strategy for global optimization of many expensive real-world functions. Contrary to a common belief that BO is suited to optimizing black-box functions, it actually requires domain knowledge on characteristics of those functions to deploy BO successfully. Such domain knowledge often manifests in Gaussian process priors that specify initial beliefs on functions. However, even with expert knowledge, it is not an easy task to select a prior. This is especially true for hyperparameter tuning problems on complex machine learning models, where landscapes of tuning objectives are often difficult to comprehend. We seek an alternative practice for setting these functional priors. In particular, we consider the scenario where we have data from similar functions that allow us to pre-train a tighter distribution a priori. To verify our approach in realistic model training setups, we collected a large multi-task hyperparameter tuning dataset by training tens of thousands of configurations of near-state-of-the-art models on popular image and text datasets, as well as a protein sequence dataset. Our results show that on average, our method is able to locate good hyperparameters at least 3 times more efficiently than the best competing methods.
https://arxiv.org/abs/2207.03084

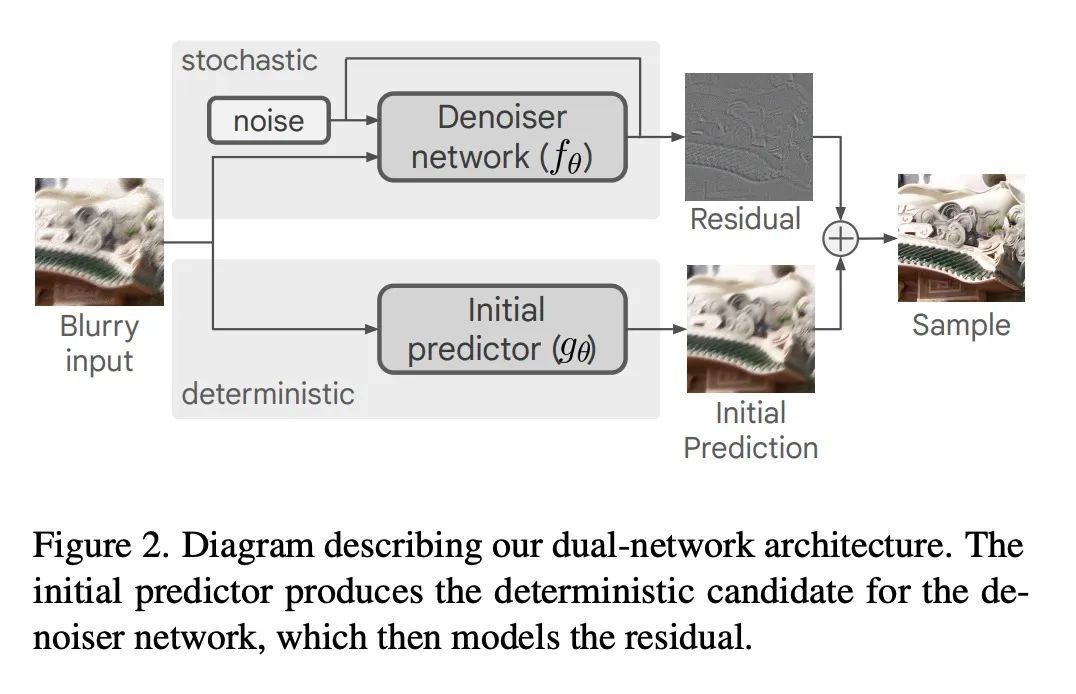
4、[CV] Deblurring via Stochastic Refinement
J Whang, M Delbracio, H Talebi, C Saharia, A G. Dimakis, P Milanfar
[University of Texas at Austin & Google Research]
基于随机细化的图像去模糊。图像去模糊是一个棘手的问题,对于一个给定的输入图像有多种合理的解决方案。然而,大多数现有的方法对干净的图像产生一个确定的估计,并被训练成最小的像素级失真。众所周知,这些指标与人类感知的相关性很差,往往导致不现实的重建。本文提出一种基于条件扩散模型的盲去模糊替代框架。与现有技术不同,该方法训练一个随机采样器,该采样器改进了确定性预测器的输出,并能为给定的输入产生一组不同的可信重建。这导致了在多个标准基准上,感知质量比现有最先进方法有了明显的改善。与典型扩散模型相比,所提出的预测和改进方法还能实现更有效的采样。结合精心调整的网络结构和推理程序,该方法在失真指标(如PSNR)方面具有竞争力。试验结果显示了基于扩散的去模糊方法的明显优势,并对广泛使用的产生单一的、确定性的重建的策略提出了挑战。
Image deblurring is an ill-posed problem with multiple plausible solutions for a given input image. However, most existing methods produce a deterministic estimate of the clean image and are trained to minimize pixel-level distortion. These metrics are known to be poorly correlated with human perception, and often lead to unrealistic reconstructions. We present an alternative framework for blind deblurring based on conditional diffusion models. Unlike existing techniques, we train a stochastic sampler that refines the output of a deterministic predictor and is capable of producing a diverse set of plausible reconstructions for a given input. This leads to a significant improvement in perceptual quality over existing state-of-the-art methods across multiple standard benchmarks. Our predict-and-refine approach also enables much more efficient sampling compared to typical diffusion models. Combined with a carefully tuned network architecture and inference procedure, our method is competitive in terms of distortion metrics such as PSNR. These results show clear benefits of our diffusion-based method for deblurring and challenge the widely used strategy of producing a single, deterministic reconstruction.
https://arxiv.org/abs/2112.02475



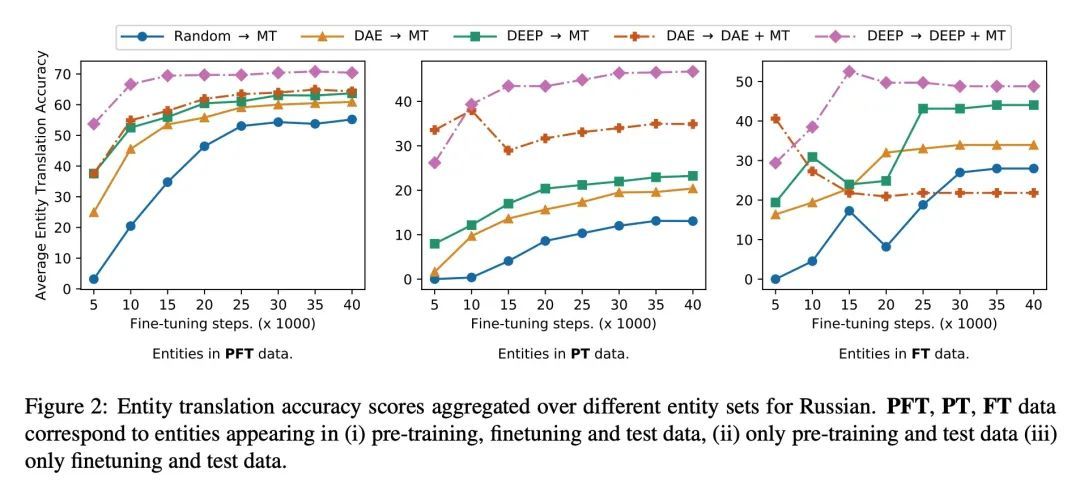
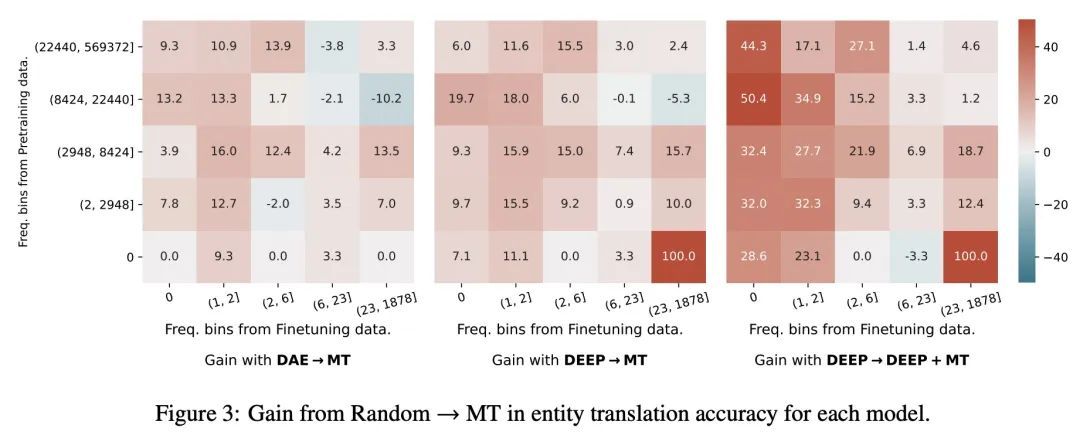
5、[CL] DEEP: DEnoising Entity Pre-training for Neural Machine Translation
J Hu, H Hayashi, K Cho, G Neubig
[University of Wisconsin-Madison & New York University & CMU]
DEEP:面向神经机器翻译的去噪实体预训练。已有研究表明,机器翻译模型通常对训练语料库中不常见的命名实体产生较差的翻译。早期的命名实体翻译方法主要集中在音译上,忽略了翻译的句子上下文,而且在领域和语言覆盖上有局限性。为解决这一局限性,本文提出DEEP,一种去噪实体预训练方法,利用大量的单语数据和知识库来提高句子内命名实体翻译的准确性。此外,本文研究了一种多任务学习策略,在实体增强的单语数据和平行数据上微调预训练神经机器翻译模型,以进一步提高实体翻译。在三种语言对上的实验结果表明,DEEP的结果比强去噪自动编码基线有了明显改善,在英语-俄语翻译中获得了高达1.3的BLEU和高达9.2的实体精度的增益。
It has been shown that machine translation models usually generate poor translations for named entities that are infrequent in the training corpus. Earlier named entity translation methods mainly focus on phonetic transliteration, which ignores the sentence context for translation and is limited in domain and language coverage. To address this limitation, we propose DEEP, a DEnoising Entity Pretraining method that leverages large amounts of monolingual data and a knowledge base to improve named entity translation accuracy within sentences. Besides, we investigate a multi-task learning strategy that finetunes a pre-trained neural machine translation model on both entity-augmented monolingual data and parallel data to further improve entity translation. Experimental results on three language pairs demonstrate that DEEP results in significant improvements over strong denoising auto-encoding baselines, with a gain of up to 1.3 BLEU and up to 9.2 entity accuracy points for English-Russian translation.
https://arxiv.org/abs/2111.07393



另外几篇值得关注的论文:
[LG] Tensor networks in machine learning
基于张量网络的机器学习
R Sengupta, S Adhikary, I Oseledets, J Biamonte
[Skolkovo Institute of Science and Technology]
https://arxiv.org/abs/2207.02851



[CV] OpenLDN: Learning to Discover Novel Classes for Open-World Semi-Supervised Learning
OpenLDN:开放世界半监督学习新类发现学习
M N Rizve, N Kardan, S Khan, F S Khan, M Shah
[UCF & Mohamed bin Zayed University of AI]
https://arxiv.org/abs/2207.02261





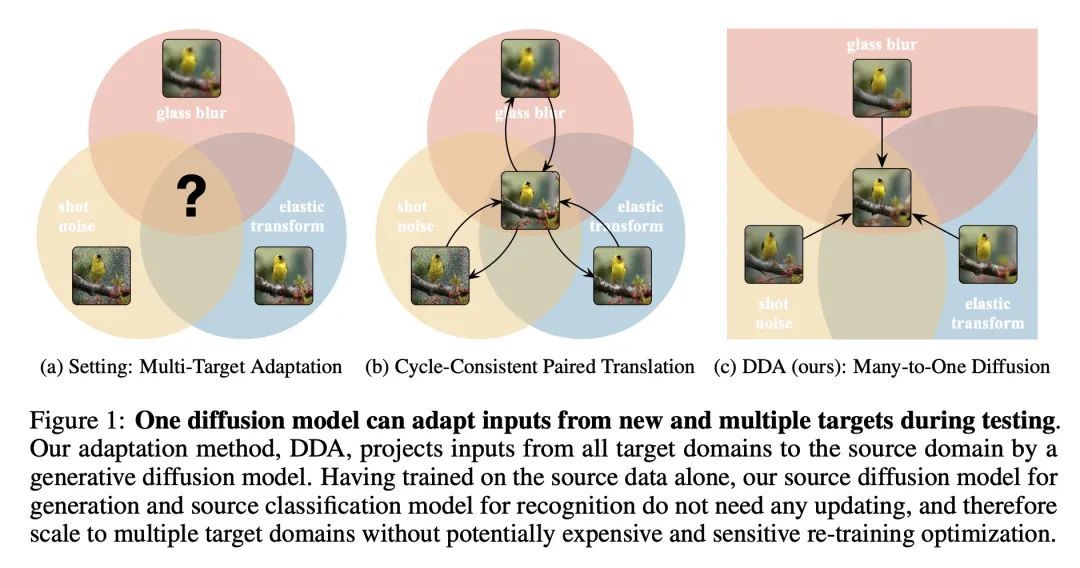
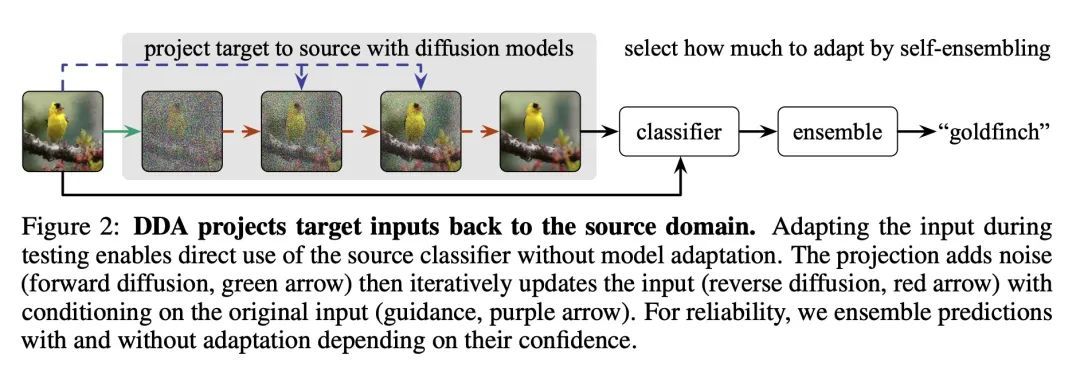
[LG] Back to the Source: Diffusion-Driven Test-Time Adaptation
回归源域:扩散驱动的测试时自适应
J Gao, J Zhang, X Liu, T Darrell, E Shelhamer, D Wang
[SJTU & UC Berkeley & DeepMind]
https://arxiv.org/abs/2207.03442



[CV] Detecting and Recovering Sequential DeepFake Manipulation
序列DeepFake操纵的检测和恢复
R Shao, T Wu, Z Liu
[Nanyang Technological University]
https://arxiv.org/abs/2207.02204





内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢