
随着摩尔定律的放缓,在相同的技术工艺节点上开发能够提升芯片性能的其他技术变得越来越重要。在这项研究中,英伟达使用深度强化学习方法设计尺寸更小、速度更快和更加高效的算术电路,从而为芯片提供更高的性能。
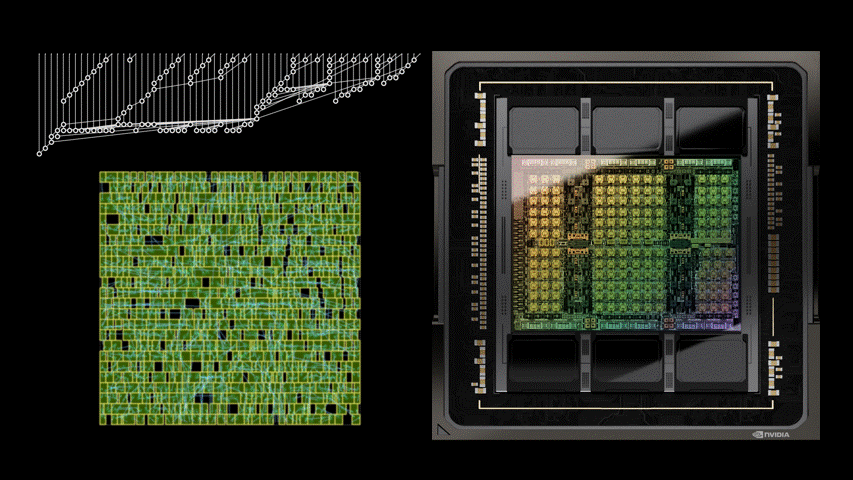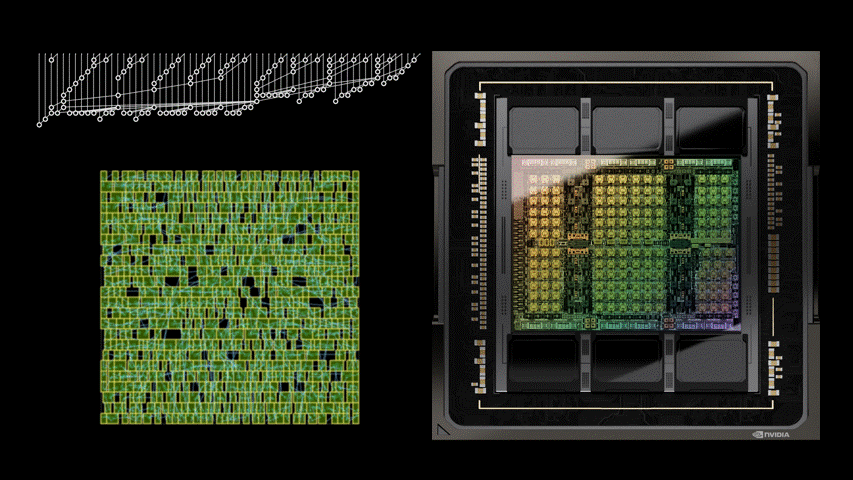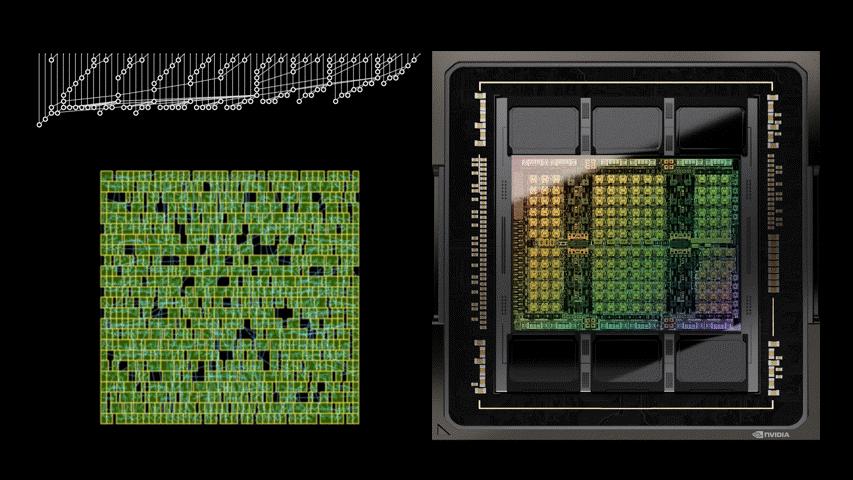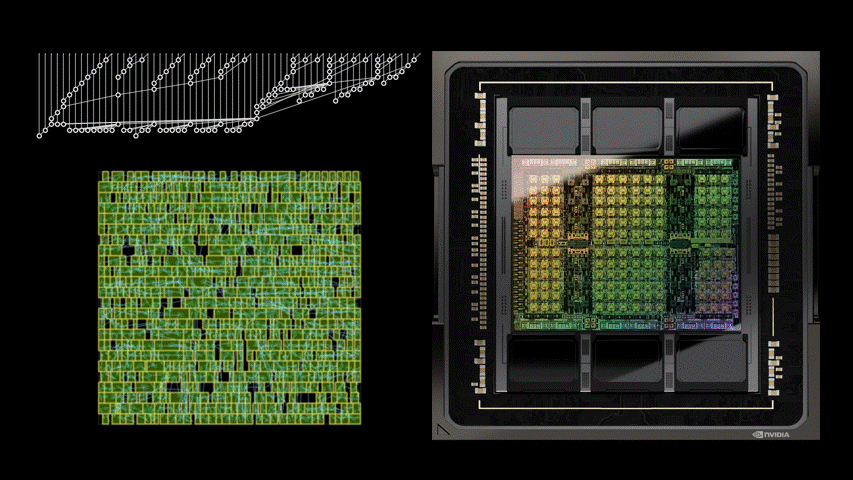
大量的算术电路阵列为英伟达 GPU 提供了动力,以实现前所未有的 AI、高性能计算和计算机图形加速。因此,改进这些算术电路的设计对于提升 GPU 性能和效率而言至关重要。
如果 AI 学习设计这些电路会怎么样呢?在近期英伟达的论文《PrefixRL: Optimization of Parallel Prefix Circuits using Deep Reinforcement Learning》中,研究者证明了AI不仅可以从头开始设计这些电路,而且AI设计的电路比最先进电子设计自动化(EDA)工具设计的电路更小、更快。
论文地址:https://arxiv.org/pdf/2205.07000.pdf
最新的英伟达Hopper GPU架构中拥有近13000个AI设计的电路实例。下图 1 左 PrefixRL AI设计的64b加法器电路比图1右最先进EDA工具设计的电路小25%。
电路设计概览
计算机芯片中的算术电路是由逻辑门网络(如NAND、NOR和XOR)和电线构成。理想的电路应具有以下属性:
- 小:更小的面积,更多电路可以封装在芯片上;
- 快:更低的延迟,提高芯片的性能;
- 更低功耗。
在英伟达的这项研究中,研究者关注电路面积和延迟。他们发现,功耗与感兴趣电路的面积密切相关。电路面积和延迟往往是相互竞争的属性,因此希望找到有效权衡这些属性的设计的帕累托边界。简言之,研究者希望每次延迟时电路面积是最小的。
因此,在PrefixRL中,研究者专注于一类流行的算术电路——并行前缀电路。GPU中的各种重要电路如加速器、增量器和编码器等都是前缀电路,它们可以在更高级别上被定为为前缀图。
那么问题来了:AI智能体能设计出好的前缀图吗?所有前缀图的状态空间是很大的O(2^n^n),无法使用蛮力方法进行探索。下图2为具有4b电路实例的PrefixRL的一次迭代。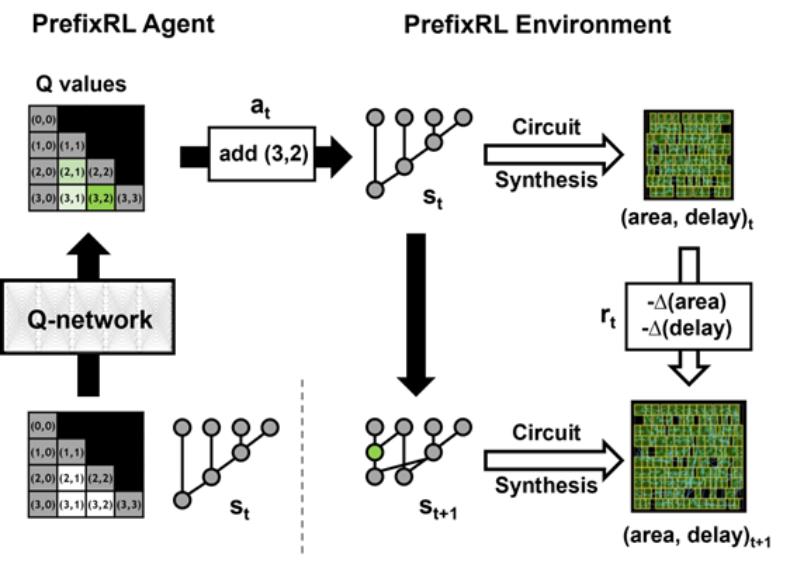
研究者使用电路生成器将前缀图转换为一个带有电线和逻辑门的电路。接下来,这些生成的电路通过一个物理综合工具来优化,该工具使用门尺寸、复制和缓冲器插入等物理综合优化。
由于这些物理综合优化,最终的电路属性(延迟、面积和功率)不会直接从原始前缀图属性(如电平和节点数)转换而来。这就是为什么AI智能体学习设计前缀图但又要对从前缀图中生成的最终电路的属性进行优化。
研究者将算术电路设计视为一项强化学习(RL)任务,其中训练一个智能体优化算术电路的面积和延迟属性。对于前缀电路,他们设计了一个环境,其中RL智能体可以添加或删除前缀图中的节点,然后执行如下步骤:
- 前缀图被规范化以始终保持正确的前缀和计算;
- 从规范化的前缀图中生成电路;
- 使用物理综合工具对电路进行物理综合优化;
- 测量电路的面积和延迟特性。
在如下动图中,RL智能体通过添加或删除节点来一步步地构建前缀图。在每一步上,该智能体得到的奖励是对应电路面积和延迟的改进。

原图为可交互版本。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢