
「题目」:COLD BREW: DISTILLING GRAPH NODE REPRESENTATIONS WITH INCOMPLETE OR MISSING NEIGHBORHOODS
「作者」:Wenqing Zheng, Edward W Huang, Nikhil Rao, Sumeet Katariya, Zhangyang Wang, Karthik Subbian
「论文链接」:https://openreview.net/forum?id=1ugNpm7W6E
「代码」:https://github.com/amazon-research/gnn-tail-generalization
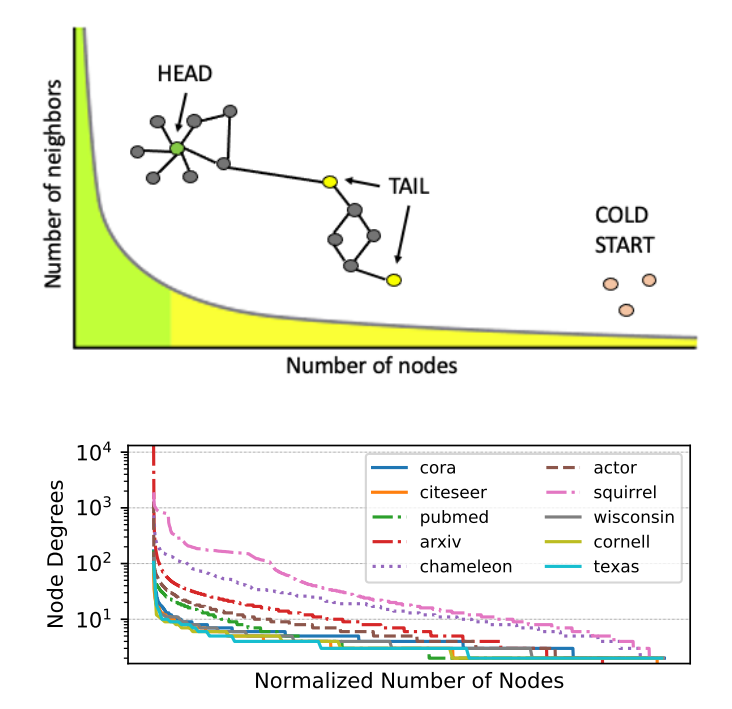
图 1:顶部:图节点可能具有幂律(“长尾”)连接分布,大部分节点(黄色)几乎没有邻居。底部:现实世界数据集中的长尾分布,使得现代 GNN 无法泛化到尾/冷启动节点
Introduction
图神经网络 (GNN) 在图分类、节点分类、链接预测和推荐等广泛的任务中实现了最先进的结果。大多数 GNN 依赖于消息传递的原理,从其(多跳)邻域聚合每个节点的特征。GNN 的成功依赖于「密集和高质量连接的存在」。
但是,许多现实世界图中存在的长尾节点度分布。具体来说,节点度分布本质上是幂律分布,大多数节点的连接很少。许多信息检索和推荐应用都面临严格冷启动(Strict Cold Start, SCS)的场景, 其中一些节点没有连接的边。诚然,预测这些节点比图中的尾节点更具挑战性。「在这些情况下,由于邻域的稀疏性或缺失,现有的 GNN 表现不佳。」
在本文中,作者提出了具有真正归纳能力的 GNN 模型:可以为图中的“孤立”节点学习有效的节点嵌入。这种能力对于充分发挥大规模 GNN 模型在具有「长尾和许多孤立节点」的现代工业规模数据集上的潜力非常重要。
Cold Brew 框架解决了两个关键问题:-(1)如何有效地提炼教师的知识以进行尾部和冷启动,以及(2)学生如何利用这些知识。作者通过使用知识蒸馏学习潜在的节点嵌入来回答这两个问题,这既避免了“过度平滑”,又发现了潜在的邻域, SCS 节点缺少这些。与传统的知识蒸馏(Hinton et al., 2015)相比,本文的目标不是训练一个更简单的学生模型来像更复杂的教师一样执行。相反,是训练一个在泛化到尾部或 SCS 样本方面优于教师的学生模型。
此外,为了帮助选择冷启动友好模型架构,作者提出了一个称为特征贡献率 (FCR) 的指标,用于量化节点特征对特定下游任务数据集中邻接结构的贡献。FCR 指示了推广到尾节点和冷启动节点的难度级别,并指导在 Cold Brew 中对教师和学生模型架构的原则选择。
本文主要的方法
本文的关键思想如下:GNN 将节点特征映射到 d 维嵌入空间,由于节点的数量 N 通常远大于嵌入维数 d,因此最终会得到该空间的过完备集使用嵌入作为基础。这意味着任何节点表示都可以转换为 K<<N 个现有节点表示的线性组合的可能性。本文目标是训练一个学生模型,该模型可以准确地发现目标孤立节点的最佳 K 个现有节点嵌入的组合。将此过程称为潜在/虚拟邻域发现,这相当于使用 MLP 来“模仿”教师 GNN 学习的节点表示。
作者采用知识蒸馏程序来提高尾部和冷启动节点的学习嵌入质量。使用教师 GNN 模型通过利用图结构将节点嵌入到低维流形上。然后,学生的目标是学习从节点特征到该流形的映射,而无需了解教师所拥有的图。进一步的目标是让学生模型推广到教师模型失败的 SCS 案例,而不仅仅是像标准知识蒸馏那样模仿教师。
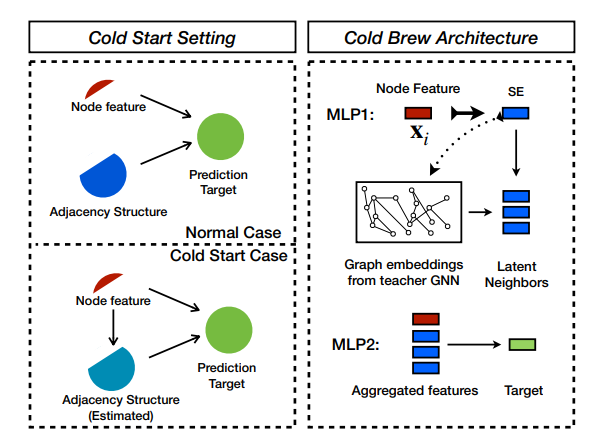
冷启动设置下Cold Brew框架的师生
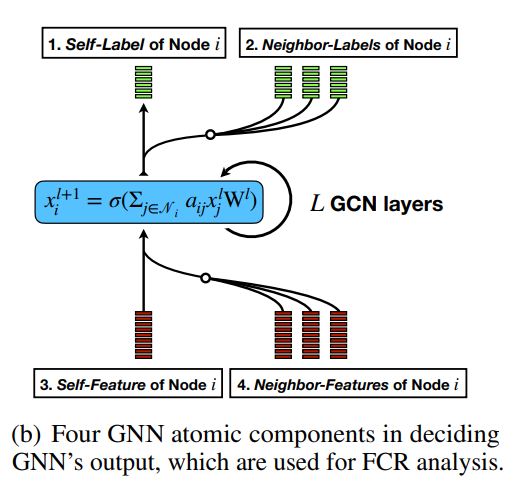
知识蒸馏决定 GNN 输出的四个 GNN 原子组件,用于 FCR 分析
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢