
作者:Jon Saad-Falcon、 Amanpreet Singh、 Luca Soldaini、等
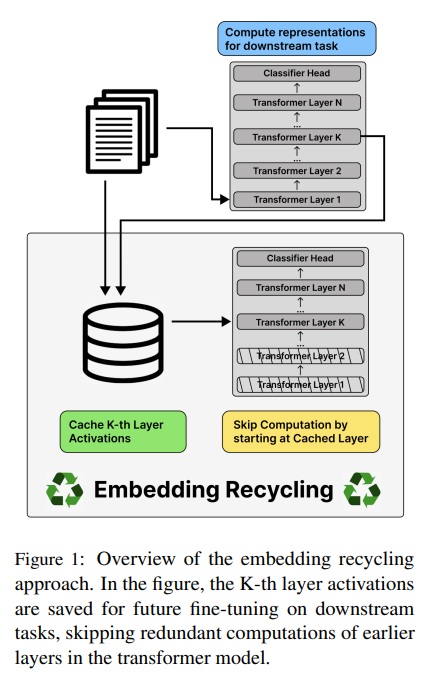
简介:本文研究语言模型的嵌入回收(缓存来自预训练的中间层的输出)以降低计算成本。使用大型神经模型进行训练和推理非常昂贵。然而,对于许多应用领域,虽然新任务和模型频繁出现,但被建模的底层文档大部分保持不变。作者研究如何通过嵌入回收 (ER) 降低此类设置中的计算成本:在执行训练或推理时重用来自先前模型运行的激活。与之前专注于冻结小分类头进行微调的工作相比,这通常会导致性能显着下降,作者建议缓存来自预训练的中间层的输出为新任务建模和微调剩余层。作者表明,作者的方法在训练期间提供了 100% 的加速,对推理提供了 55-86% 的加速,并且对科学领域中的文本分类和实体识别任务的准确性影响可以忽略不计。对于一般领域的问答任务,ER 提供了类似的加速效果,并略微降低了准确性。最后,作者确定了 ER 的多个开放挑战和未来方向。
论文下载:https://arxiv.org/pdf/2207.04993.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢