

作者:Wes Robbins, Zanyar Zohourianshahzadi, Jugal Kalita
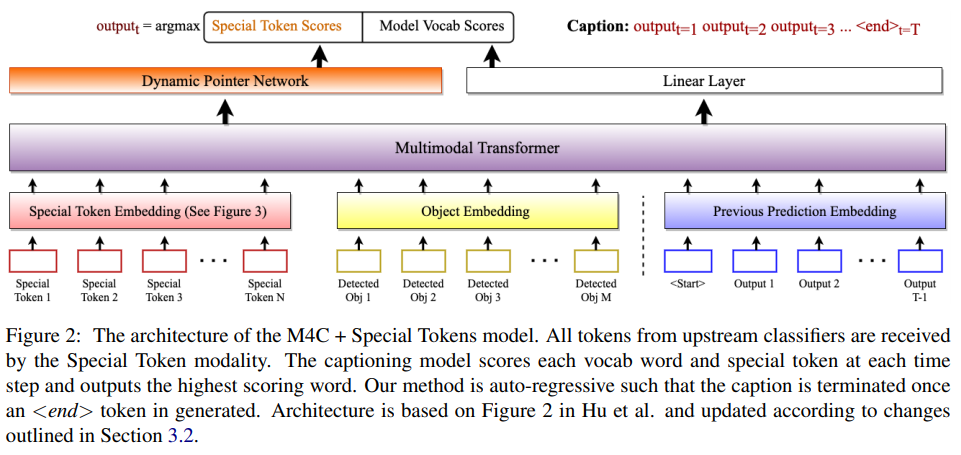
简介:本文研究作为适应性方法的特殊令牌方法从图像中提取的附加信息,以提升视觉语言模型的效果。视觉语言模型可以评估图像中的视觉上下文并生成描述性文本。虽然生成的文本可能准确且语法正确,但通常过于笼统。为了解决这个问题,最近的工作使用光学字符识别来用从图像中提取的文本来补充视觉信息。在这项工作中,作者认为视觉语言模型可以从可以从图像中提取的附加信息中受益,但当前模型并未使用这些信息。作者修改了以前的多模式框架以接受来自任意数量的辅助分类器的相关信息。特别是,作者将人名作为一组额外的标记,并创建一个新颖的图像标题数据集,以方便使用人名进行标题。数据集,字幕中的政治家和运动员 (PAC),由上下文中的知名人士的字幕图像组成。通过使用该数据集微调预训练模型,作者展示了一个模型,该模型可以通过对有限数据进行训练,自然地将面部识别标记集成到生成的文本中。对于 PAC 数据集,作者提供了关于收集和基线基准分数的讨论。


论文下载:https://arxiv.org/pdf/2207.04174.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢