

麦吉尔大学CS巨佬刘学教授团队2022年发表在arxiv的一篇综述更新了第二个版本,链接为
https://arxiv.org/abs/2203.10480
介绍
这篇文章主要做了三件事:
- 提出了一个动态图神经网络的范式:Three Stages Recurrent Temporal Learning Framework
- 包括属性自更新(Attribute Self-Updating)、联系过程(Association Process)和消息传递(Message Passing)
- 列出不同的动态图学习目标,包括下一时间状态、缺失标签和事件发生间隔
- 调研了离散时间动态图(DTDG)和连续时间动态图(CTDG)两种主流的动态图场景
动态图机器学习
本文认为图学习主要有三种task:预测点、预测边、预测(子)图
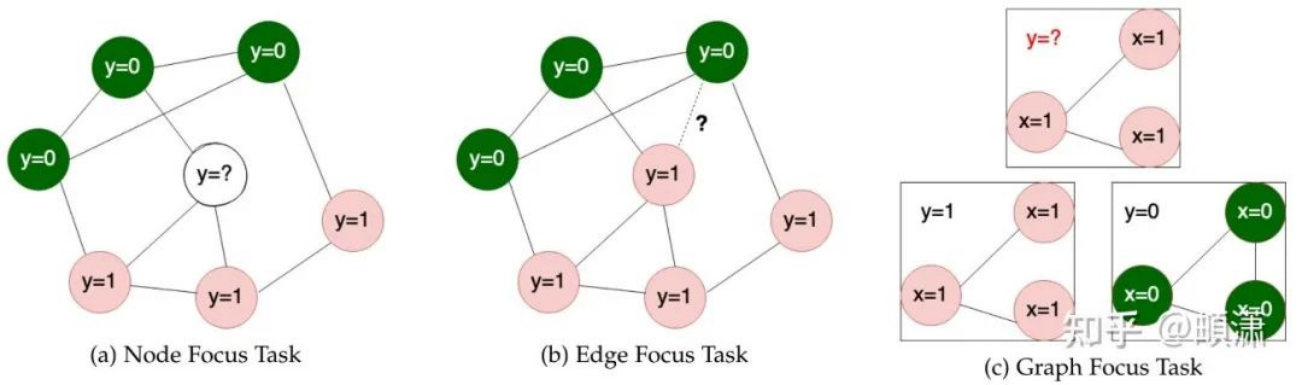
不同的图学习任务
对于动态图,主要有三种task:
- Extrapolation Learning:预测下一个时间点的点或边的状态
- Interpolation Learning:预测缺失的标签
- Time Prediction:预测下一个事件(点或边的变化)的发生时间

有监督动态图学习
三阶段循环时序学习框架(Three Stages Recurrent Temporal Learning Framework)
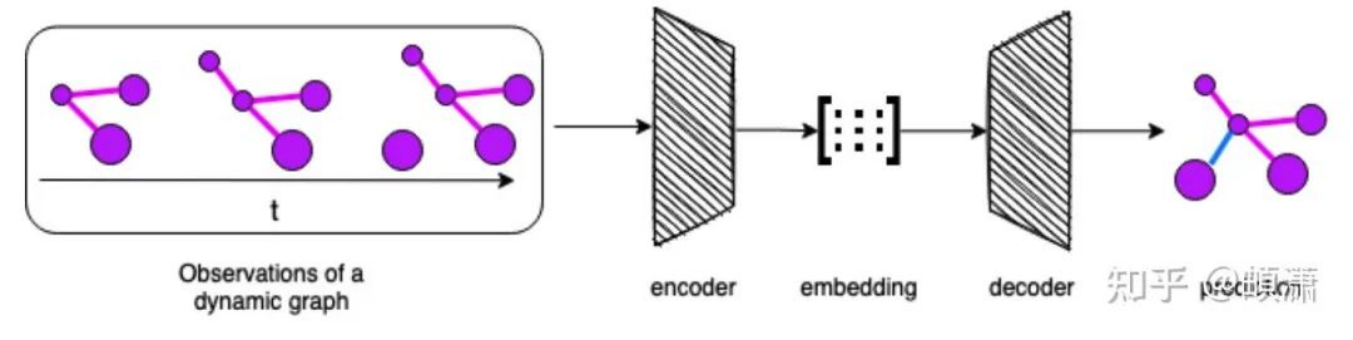
对于动态图学习,主要分为两个大步骤:
- 更新下一个snapshot的图上点和边的状态
- 根据task设置output函数
针对于第一个步骤,本文提出了Three Stages Recurrent Temporal Learning Framework来细化,分别为:
- 属性自更新(Attribute Self-Updating):外界因素影响图上点和边的属性
- 联系过程(Association Process):针对图上边的操作,包括生成、去除和修改
- 消息传递(Message Passing):和之前的工作定义相同,对邻居进行聚合
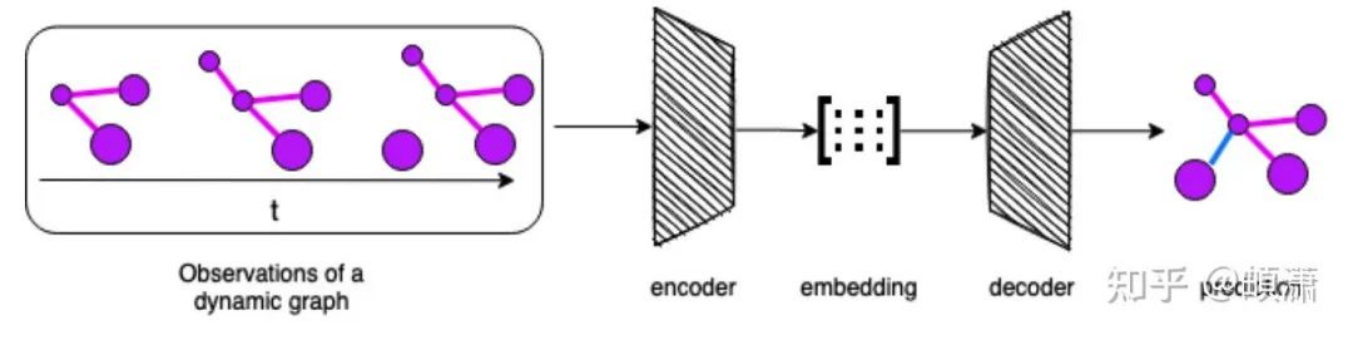
属性自更新(Attribute Self-Updating)、连接过程(Association Process)和消息传递(Message Passing)
文中对此进行了举例:
- TGN和APAN使用了node memory来完成Attribute Self-Updating
- Know-Evolve、DyRep和TGAT在Attribute Self-Updating中继承观测状态里最后一个(点和边的)状态
离散时间动态图(DTDG)学习
定义:在每个可观测的若干离散timestamp里,会有一个给定图的snapshot
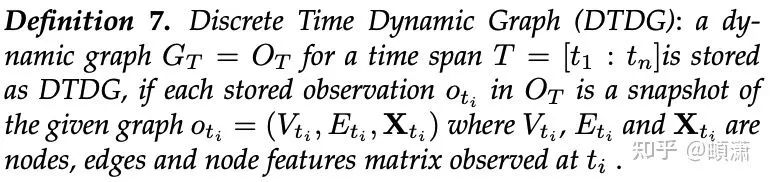
针对DTDG,文中给出两种最常见的框架
- 静态图encoder+序列decoder
- 动态图encoder+简单decoder
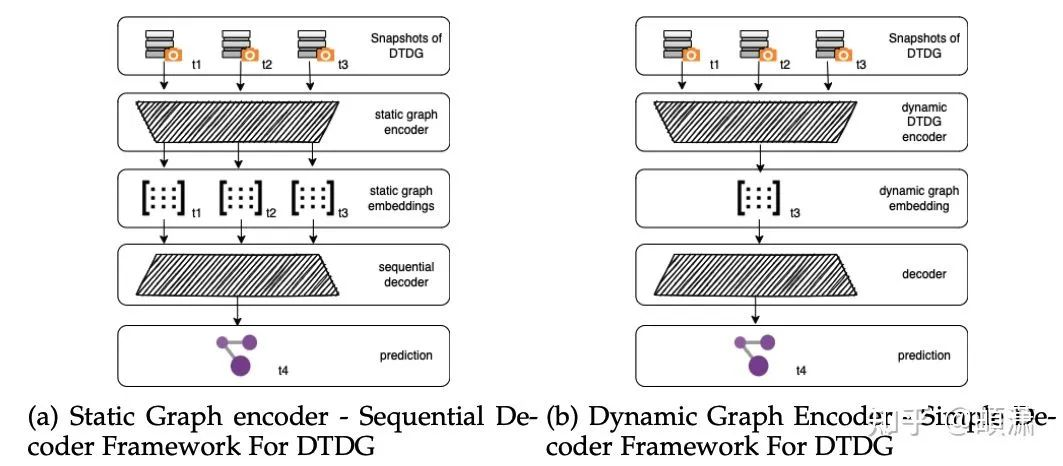
DTDG的常见Encoder-Decoder框架
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢