
本文分享Recsys2022上最新的一篇工作:Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5) 。标题非常吸引人。将推荐系统问题用自然语言处理框架来建模,提出了一种通用的建模框架,包含:预训练(Pretrain)、个性化提示学习(Personalized Prompt)、预测(Predict)的范式(Paradigm),简称为P5。

论文链接:
https://arxiv.org/abs/2203.13366
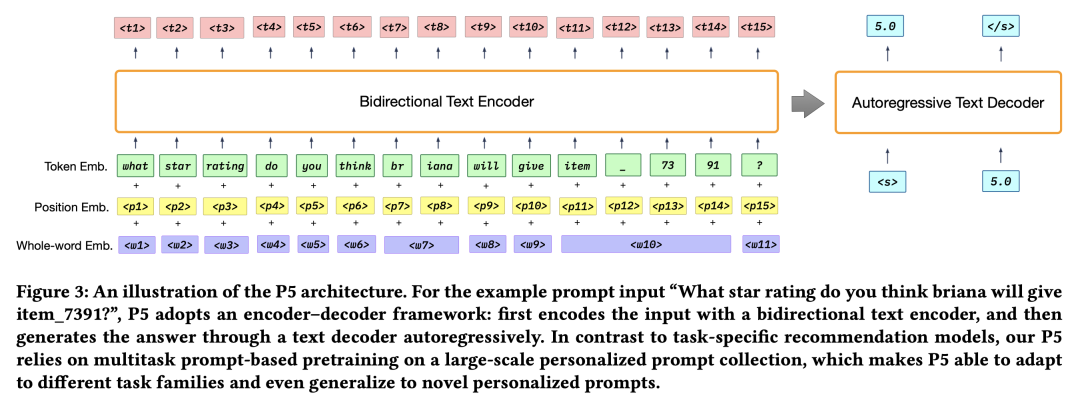
在P5中,推荐系统中的user-item交互行为数据、item的元数据、用户特征(如评论数据)被转成通用的"自然语言序列"格式,集成到个性化prompt模板中,作为模型的输入。在预训练阶段,P5使用统一的模型和目标来进行多任务预训练,因此拥有适用不同下游推荐任务的能力。
下游应用时,使用自适应的个性化prompts来实现“千人千面”,能够在下游任务中实现零样本或少样本泛化,省去微调工作。
P5的核心优势在于:
-
将推荐模型置身于”NLP环境“中,在个性化prompt的帮助下,重新形式化各类推荐系统任务输入为NLP语言序列。由于NLP模型在文本prompt模板特征上能够充分挖掘和表达语义,使得推荐系统可以充分捕获蕴含在训练语料中的知识。 -
P5将各类推荐系统问题融合在一个统一的Text-to-Text Encoder-Decoder架构,建模成条件文本生成问题,并使用相同的语言模型损失来预训练,而不是每个任务用特定的损失函数。 -
训练时使用instruction-based prompts,使得模型在下游应用时可以实现零样本或少样本泛化,比如泛化到其它领域或未见过的items,一定程度解决推荐系统的冷启动问题。
本文的核心贡献在于:
-
是第一个提出将各类推荐系统任务用统一的pretrain,prompt,predict的条件语言生成框架来建模。
-
提出了一系列个性化prompts,涵盖五类推荐系统任务。
-
在五种的推荐系统benchmarks,作者做了实验来阐明该方法的有效性。既能在训练时已知的prompt上表现很好,也具备零样本泛化的能力,在新的个性化prompt或新item上实现高质量的泛化。
作者表明希望本文的工作能够引领新一代推荐系统技术,通过本文提出的P5框架催生新的通用推荐引擎,并推动关于推荐系统问题看作自然语言处理过程以及相关的个性化基础模型的研究。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢