
作者:Chris van der Lee, Thiago Castro Ferreira, Chris Emmery,等
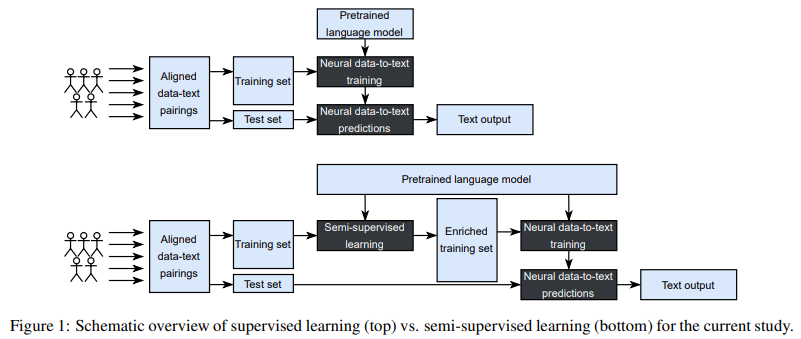
简介:本研究讨论了半监督学习与预训练语言模型相结合对数据到文本生成的影响。本研究旨在通过将仅辅以语言模型的数据到文本系统与另外通过数据增强或伪标记半监督学习方法丰富的两个数据到文本系统进行比较来回答问题:当文本生成补充大规模语言模型时:尚不知半监督学习是否仍然有用。结果表明,半监督学习在多样性指标上的得分更高。在输出质量方面,使用伪标记方法扩展具有语言模型的数据到文本系统的训练集确实提高了文本质量分数,但数据增强方法在没有训练集扩展的情况下产生了与系统相似的分数。这些结果表明,即使存在语言模型,半监督学习方法也可以提高输出质量和多样性。
论文下载:https://arxiv.org/pdf/2207.06839.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢