
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:单样本百万像素神经头像、位置预测作为有效的预训练策略、多步分布式强化学习TD错误性质研究、基于预训练大模型扩展的可靠性研究、Shapley值特征属性估计算法、播客音乐/语音分离数据集、基于预训练视觉和语言模型的多模态开放词表视频分类、基于少项评估的实用核矩阵近似、面向图像合成的GAN分类与基准
1、[CV] MegaPortraits: One-shot Megapixel Neural Head Avatars
N Drobyshev, J Chelishev, T Khakhulin, A Ivakhnenko, V Lempitsky, E Zakharov
[Samsung AI Center & Yandex]
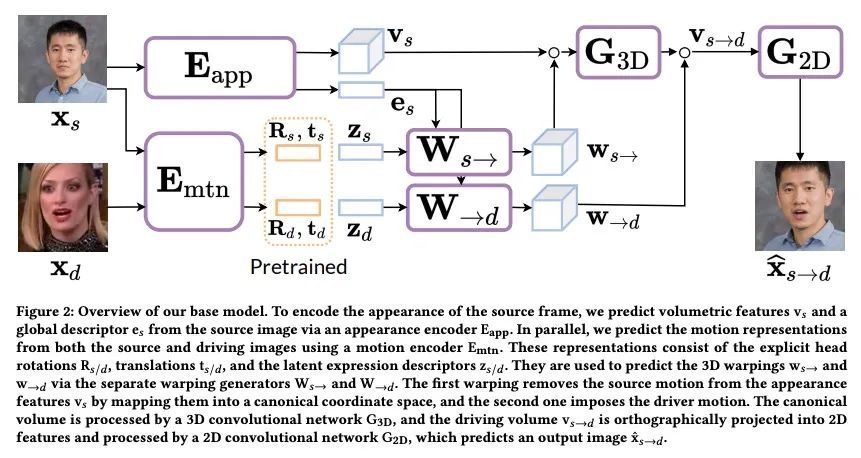
MegaPortraits:单样本百万像素神经头像。本文将神经头像技术推进到百万像素分辨率,同时专注于特别具有挑战性的交叉驱动合成任务,即驱动图像的外观与动画源图像有很大不同。本文提出一套新的神经架构和训练方法,可利用中等分辨率的视频数据和高分辨率的图像数据来实现所需的渲染图像质量水平和对新的视图和运动的泛化。实验证明了所建议的架构和方法能够产生令人信服的高分辨率神经化身,在交叉驱动场景中的表现优于竞争对手。本文还展示了如何将训练好的高分辨率神经头像模型提炼成一个轻量的学生模型,该模型可实时运行,并将神经头像的身份锁定在几十张预定义的源图像上。实时运行和身份锁定对于许多实际应用的头像系统来说是至关重要的。
In this work, we advance the neural head avatar technology to the megapixel resolution while focusing on the particularly challenging task of cross-driving synthesis, i.e., when the appearance of the driving image is substantially different from the animated source image. We propose a set of new neural architectures and training methods that can leverage both medium-resolution video data and high-resolution image data to achieve the desired levels of rendered image quality and generalization to novel views and motion. We demonstrate that suggested architectures and methods produce convincing high-resolution neural avatars, outperforming the competitors in the cross-driving scenario. Lastly, we show how a trained high-resolution neural avatar model can be distilled into a lightweight student model which runs in real-time and locks the identities of neural avatars to several dozens of pre-defined source images. Real-time operation and identity lock are essential for many practical applications head avatar systems.
https://arxiv.org/abs/2207.07621




2、[LG] Position Prediction as an Effective Pretraining Strategy
S Zhai, N Jaitly, J Ramapuram, D Busbridge, T Likhomanenko, J Y Cheng, W Talbott, C Huang, H Goh, J Susskind
[Apple Inc]
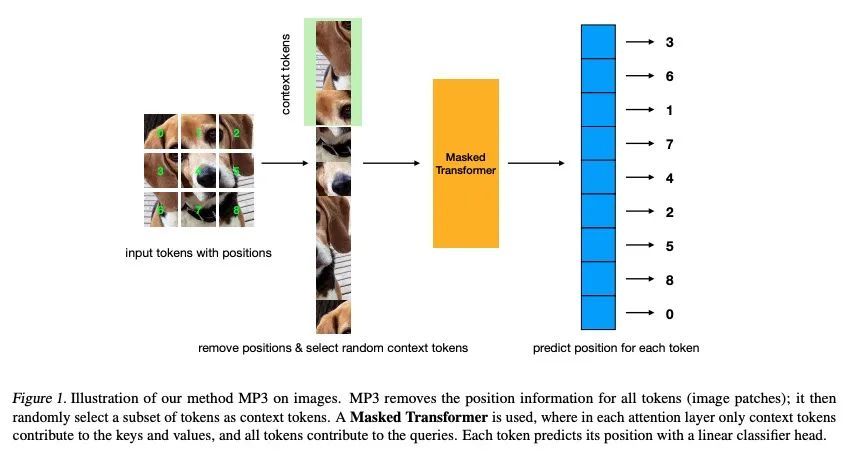
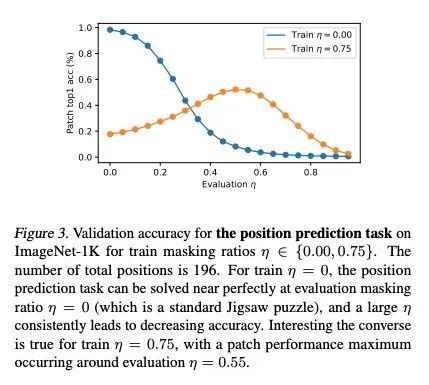
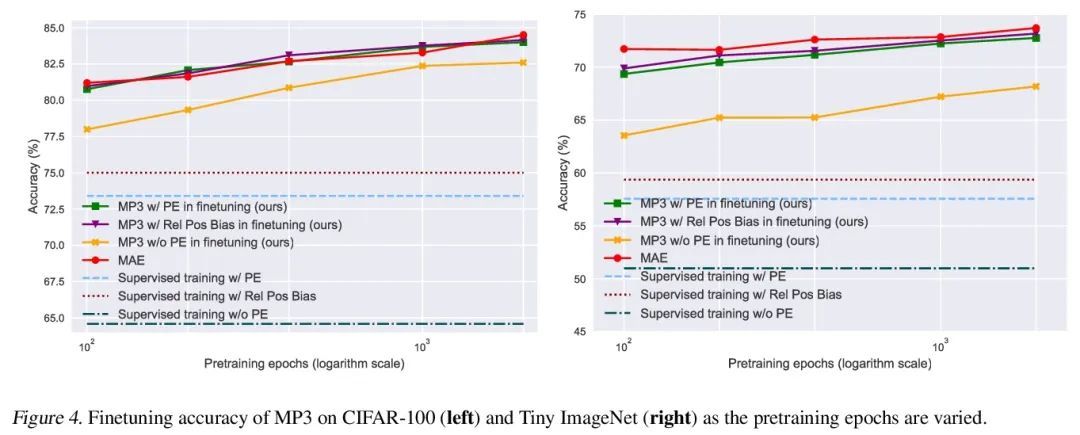
位置预测作为有效的预训练策略。Transformer在自然语言处理(NLP)、计算机视觉和语音识别等广泛的应用中获得了越来越多的欢迎,因为它们具有强大的表示能力。然而,有效地利用这种表示能力需要大量的数据,强大的正则化,或两者兼而有之,以减轻过拟合。最近,Transformer的潜力由基于掩码自编码器的自监督预训练策略进一步释放,该策略依赖于直接重建掩码输入,或从未掩码内容中进行对比。该预训练策略已被用于NLP中的BERT模型、语音中的Wav2Vec模型以及最近的视觉MAE模型,迫使模型利用自编码相关目标学习输入不同部分内容间的关系。本文提出一种新的、格外简单的内容重建替代方案——从内容中预测位置,而不为其提供位置信息。这样做需要Transformer理解输入的不同部分间的位置关系,仅从其内容来看。这相当于一个有效的实现,其中前置任务是每个输入Token的所有可能位置的分类问题。在视觉和语音基准上进行了实验,该方法比强大的监督训练基线带来了改进,并与现代无监督/自监督的预训练方法相媲美。该方法还使没有位置嵌入训练的Transformer的表现优于有完整位置信息训练的Transformer。
Transformers (Vaswani et al., 2017) have gained increasing popularity in a wide range of applications, including Natural Language Processing (NLP), Computer Vision and Speech Recognition, because of their powerful representational capacity. However, harnessing this representational capacity effectively requires a large amount of data, strong regularization, or both, to mitigate overfitting. Recently, the power of the Transformer has been unlocked by self-supervised pretraining strategies based on masked autoencoders which rely on reconstructing masked inputs, directly, or contrastively from unmasked content. This pretraining strategy which has been used in BERT models in NLP (Devlin et al., 2019), Wav2Vec models in Speech (Baevski et al., 2020) and, recently, in MAE models in Vision (Bao et al., 2021; He et al., 2021), forces the model to learn about relationships between the content in different parts of the input using autoencoding related objectives. In this paper, we propose a novel, but surprisingly simple alternative to content reconstruction – that of predicting locations from content, without providing positional information for it. Doing so requires the Transformer to understand the positional relationships between different parts of the input, from their content alone. This amounts to an efficient implementation where the pretext task is a classification problem among all possible positions for each input token. We experiment on both Vision and Speech benchmarks, where our approach brings improvements over strong supervised training baselines and is comparable to modern unsupervised/self-supervised pretraining methods. Our method also enables Transformers trained without position embeddings to outperform ones trained with full position information.
https://arxiv.org/abs/2207.07611


3、[LG] The Nature of Temporal Difference Errors in Multi-step Distributional Reinforcement Learning
Y Tang, M Rowland, R Munos, B Á Pires, W Dabney, M G. Bellemare
[DeepMind & Google Brain]
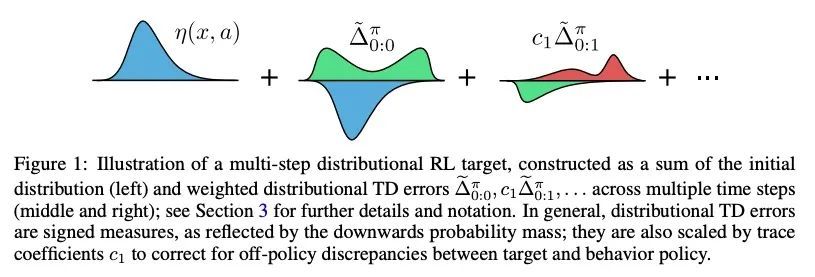
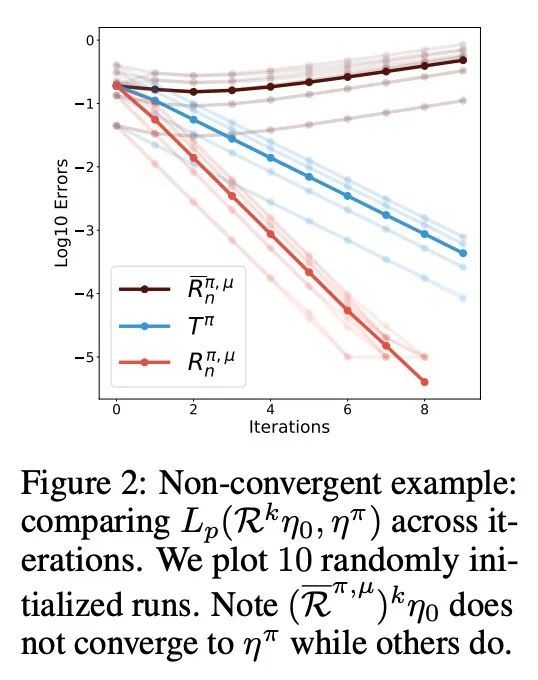
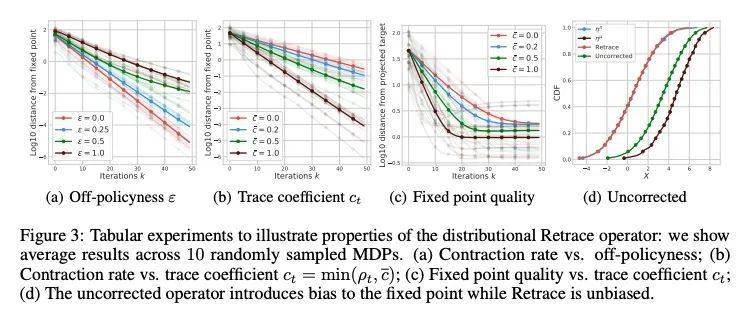
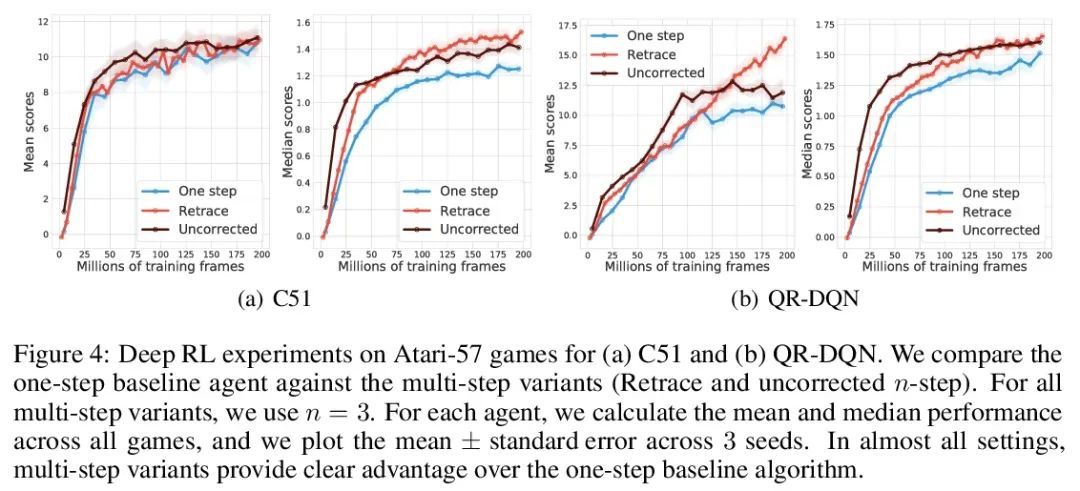
多步分布式强化学习TD错误性质研究。本文研究了分布式强化学习的多步骤off-policy learning方法。尽管基于价值的强化学习和分布式强化学习间有明显的相似性,但本研究揭示了这两种情况在多步骤设置中耐人寻味的根本区别。本文确定了一个新的路径依赖分布式TD错误的概念,这对于有原则的多步骤分布式强化学习来说是必不可少的。与基于价值的情况的区别对后视算法等概念有重要影响。本文提供了第一个关于多步off-policy分布式强化学习算法的理论保证,包括适用于现有的少量多步分布式强化学习方法的结果。本文还推导出一种新的算法——量化回归-追踪,实现了一种深度强化学习智能体QR-DQN-追踪,在Atari-57基准上显示出比QR-DQN的经验改进。总之,本文揭示了如何在理论和实践上解决多步分布式强化学习的独特挑战。
We study the multi-step off-policy learning approach to distributional RL. Despite the apparent similarity between value-based RL and distributional RL, our study reveals intriguing and fundamental differences between the two cases in the multistep setting. We identify a novel notion of path-dependent distributional TD error, which is indispensable for principled multi-step distributional RL. The distinction from the value-based case bears important implications on concepts such as backward-view algorithms. Our work provides the first theoretical guarantees on multi-step off-policy distributional RL algorithms, including results that apply to the small number of existing approaches to multi-step distributional RL. In addition, we derive a novel algorithm, Quantile Regression-Retrace, which leads to a deep RL agent QR-DQN-Retrace that shows empirical improvements over QR-DQN on the Atari-57 benchmark. Collectively, we shed light on how unique challenges in multi-step distributional RL can be addressed both in theory and practice.
https://arxiv.org/abs/2207.07570

4、[LG] Plex: Towards Reliability using Pretrained Large Model Extensions
D Tran, J Liu, M W. Dusenberry, D Phan, M Collier, J Ren, K Han, Z Wang, Z Mariet...
[Google & University of Oxford]
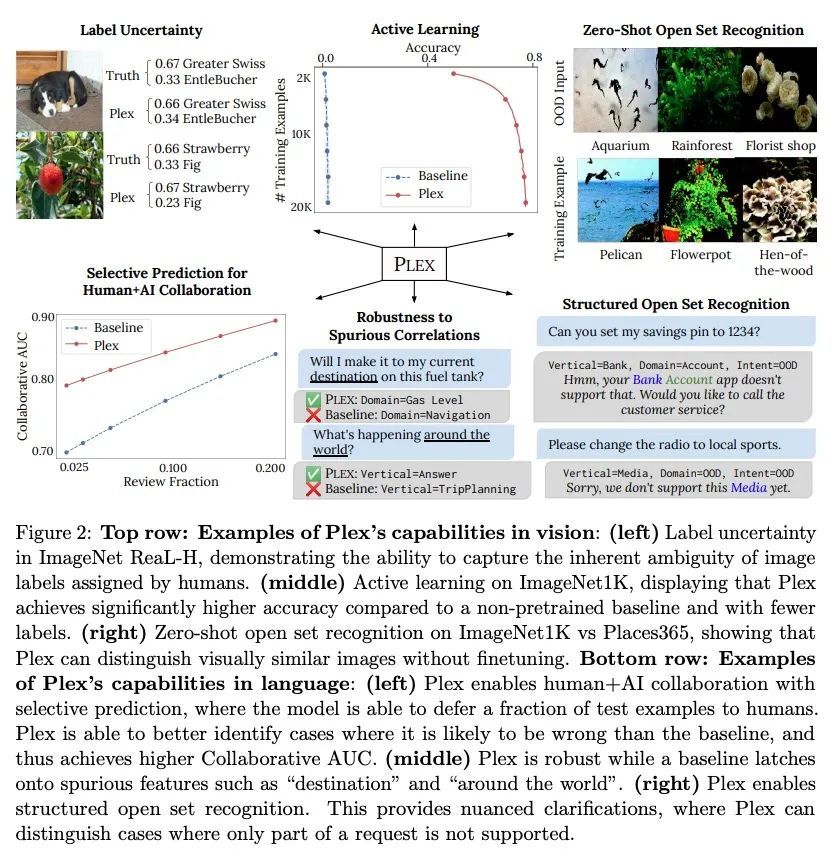
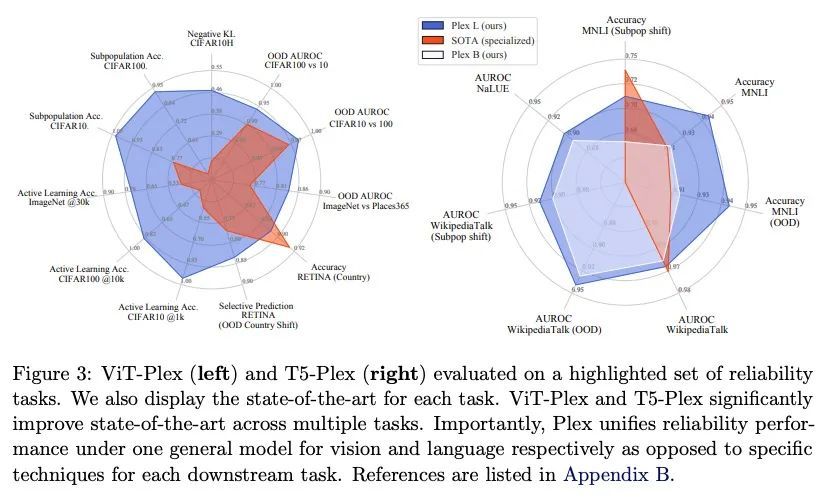
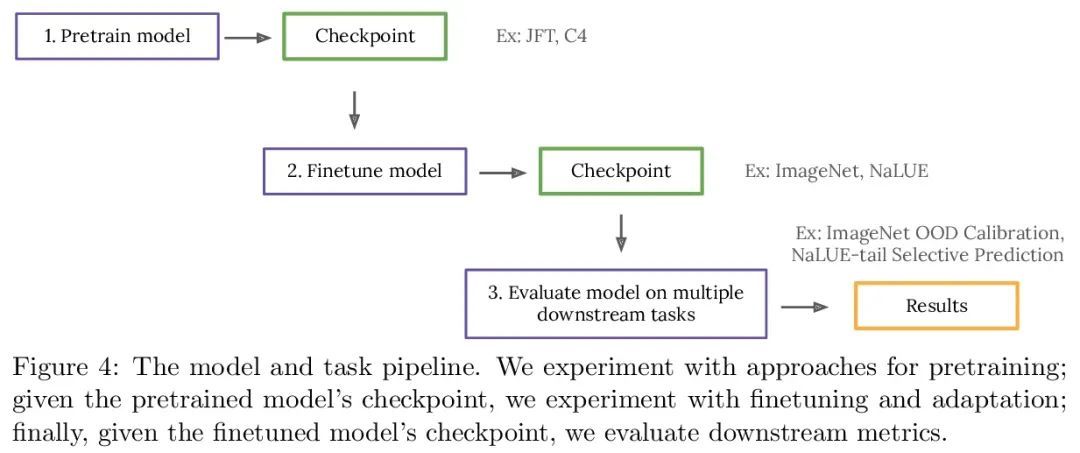
Plex:基于预训练大模型扩展的可靠性研究。人工智能的一个最新趋势是用预训练模型来完成语言和视觉任务,这些模型取得了非凡的性能,但也有令人困惑的失败。因此,以不同方式探测这些模型的能力对该领域至关重要。本文探讨了模型的可靠性,将可靠的模型定义为不仅能实现强大的预测性能,而且在许多涉及不确定性(如选择性预测、开放集识别)、鲁棒的泛化(如准确性和适当的评分规则,如分布内和分布外数据集上的对数似然)和自适应性(如主动学习、少样本不确定性)的决策任务中持续表现良好。本文在40个数据集上设计了10种任务,以评估视觉和语言领域的可靠性的不同方面。为提高可靠性,开发了ViT-Plex和T5-Plex,分别针对视觉和语言模式的预训练大模型扩展(plex)。Plex大大改善了最先进的可靠性任务,并简化了传统的协议,因为它提高了开箱即用的性能,不需要为每个任务设计分数或调整模型。本文展示了在模型规模达到1B参数和预训练数据集规模达到4B实例时的扩展效果。还展示了Plex在挑战性任务上的能力,包括零样本开放集识别、主动学习和对话式语言理解的不确定性。
A recent trend in artificial intelligence is the use of pretrained models for language and vision tasks, which have achieved extraordinary performance but also puzzling failures. Probing these models’ abilities in diverse ways is therefore critical to the field. In this paper, we explore the reliability of models, where we define a reliable model as one that not only achieves strong predictive performance but also performs well consistently over many decision-making tasks involving uncertainty (e.g., selective prediction, open set recognition), robust generalization (e.g., accuracy and proper scoring rules such as log-likelihood on inand out-of-distribution datasets), and adaptation (e.g., active learning, few-shot uncertainty). We devise 10 types of tasks over 40 datasets in order to evaluate different aspects of reliability on both vision and language domains. To improve reliability, we developed ViT-Plex and T5-Plex, pretrained large model ex tensions (plex) for vision and language modalities, respectively. Plex greatly improves the state-of-the-art across reliability tasks, and simplifies the traditional protocol as it improves the out-of-the-box performance and does not require designing scores or tuning the model for each task. We demonstrate scaling effects over model sizes up to 1B parameters and pretraining dataset sizes up to 4B examples. We also demonstrate Plex’s capabilities on challenging tasks including zero-shot open set recognition, active learning, and uncertainty in conversational language understanding.
https://arxiv.org/abs/2207.07411

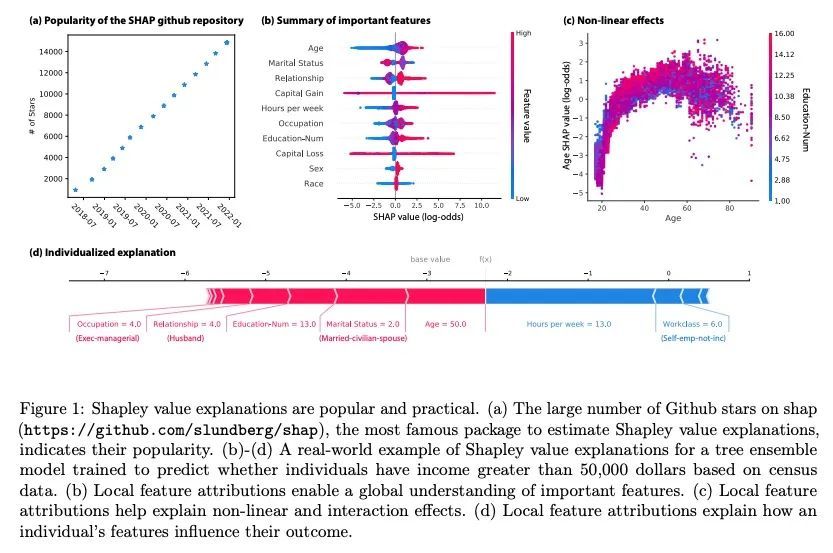
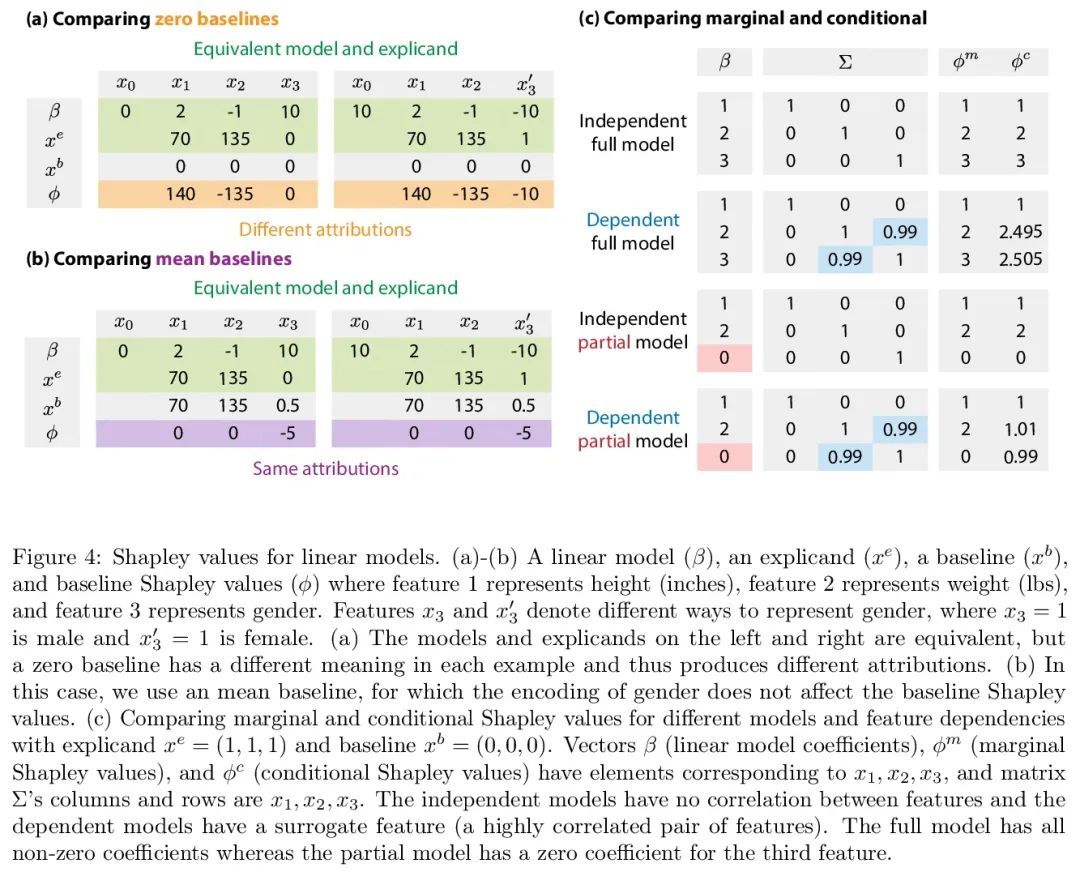
5、[LG] Algorithms to estimate Shapley value feature attributions
H Chen, I C. Covert, S M. Lundberg, S Lee
[University of Washington & Microsoft Research]
Shapley值特征属性估计算法。基于Shapley值的特征属性在解释机器学习模型方面很受欢迎;然而,从理论和计算的角度,它们的估计都很复杂。本文将这种复杂性分解为两个因素。(1)去除特征信息的方法,以及(2)可操作的估计策略。这两个因素提供了一个自然的视角,通过它可以更好地理解和比较24种不同的算法。基于不同的特征去除方法,本文描述了多种类型的Shapley值特征属性和计算每个特征的方法。基于可操作的估计策略,本文描述了两种不同系列的方法:与模型无关的近似和针对模型的近似。对于模型不可知的近似,对一类广泛的估计方法进行了评估,并将它们与Shapley值的其他等价特征联系起来。对于特定模型的近似,本文澄清了对每种方法在线性、树状和深度模型上的可操作性至关重要的假设。最后,本文确定了文献中的空白和有希望的未来研究方向。
Feature attributions based on the Shapley value are popular for explaining machine learning models; however, their estimation is complex from both a theoretical and computational standpoint. We disentangle this complexity into two factors: (1) the approach to removing feature information, and (2) the tractable estimation strategy. These two factors provide a natural lens through which we can better understand and compare 24 distinct algorithms. Based on the various feature removal approaches, we describe the multiple types of Shapley value feature attributions and methods to calculate each one. Then, based on the tractable estimation strategies, we characterize two distinct families of approaches: model-agnostic and model-specific approximations. For the model-agnostic approximations, we benchmark a wide class of estimation approaches and tie them to alternative yet equivalent characterizations of the Shapley value. For the model-specific approximations, we clarify the assumptions crucial to each method’s tractability for linear, tree, and deep models. Finally, we identify gaps in the literature and promising future research directions.
https://arxiv.org/abs/2207.07605



另外几篇值得关注的论文:
[AS] PodcastMix: A dataset for separating music and speech in podcasts
PodcastMix:播客音乐/语音分离数据集
N Schmidt, J Pons, M Miron
[Universitat Pompeu Fabra & Dolby Laboratories] https://arxiv.org/abs/2207.07403



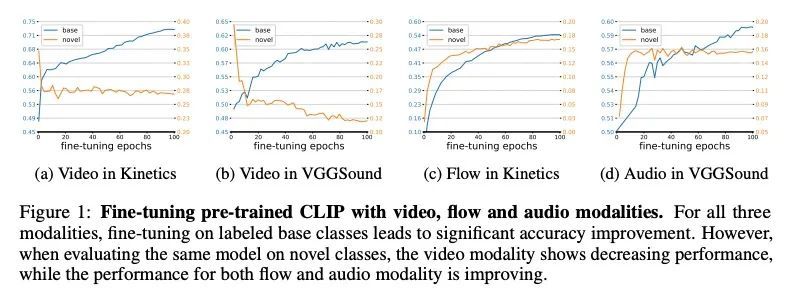
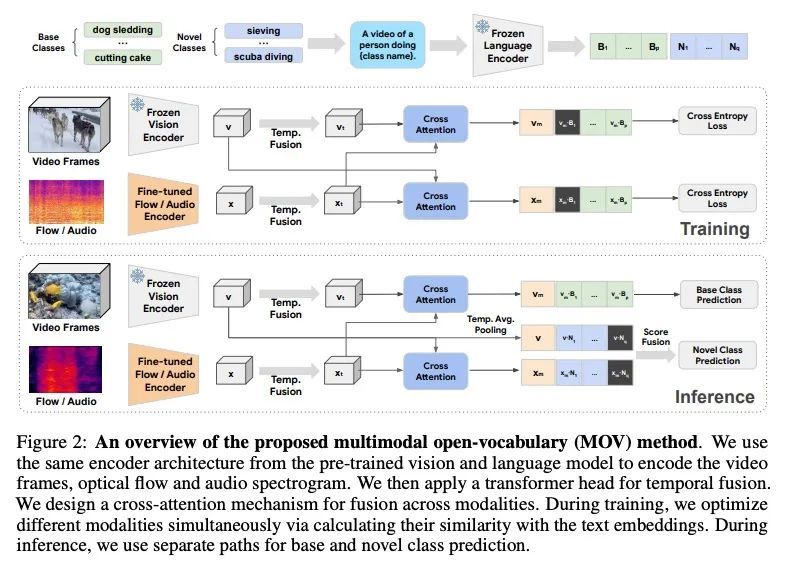
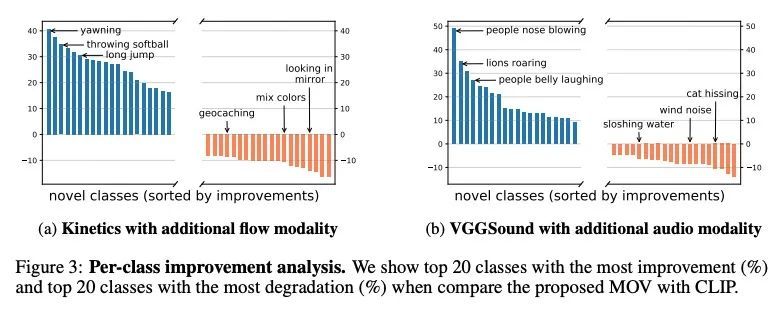
[CV] Multimodal Open-Vocabulary Video Classification via Pre-Trained Vision and Language Models
基于预训练视觉和语言模型的多模态开放词表视频分类
R Qian, Y Li, Z Xu, M Yang, S Belongie, Y Cui
[Google Research & University of Copenhagen]
https://arxiv.org/abs/2207.07646

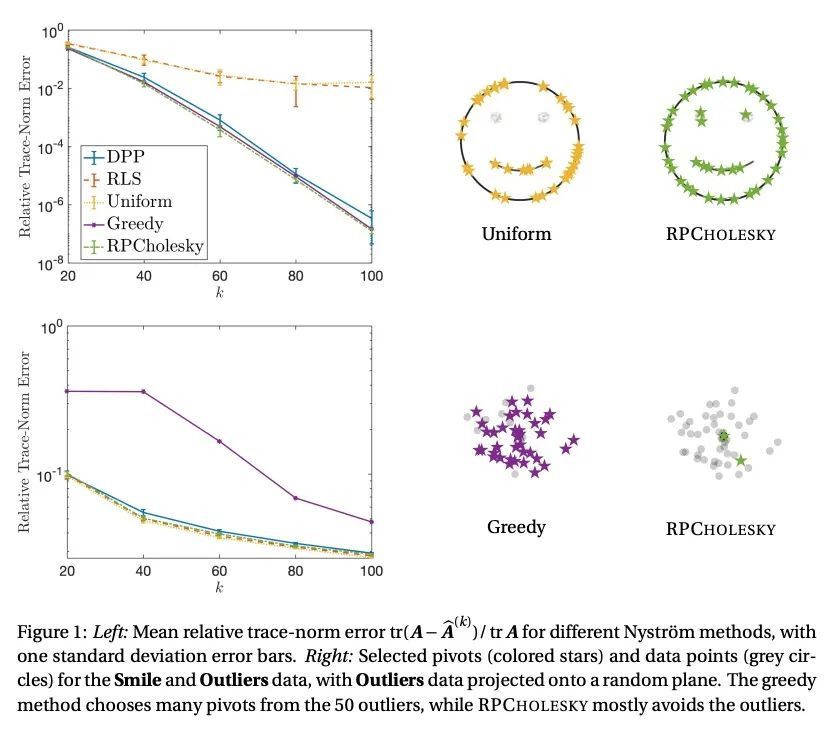
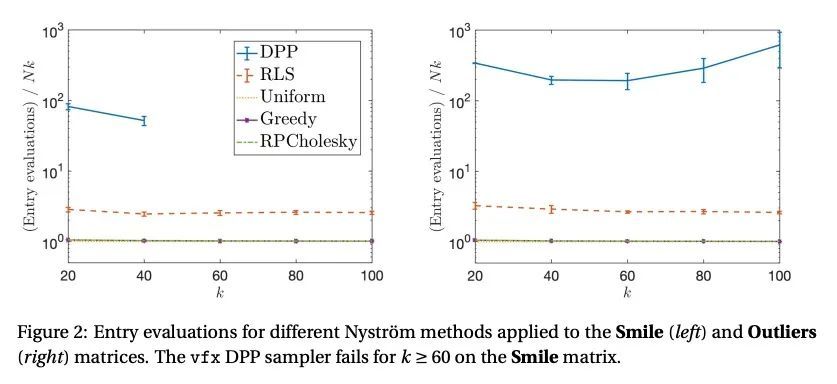
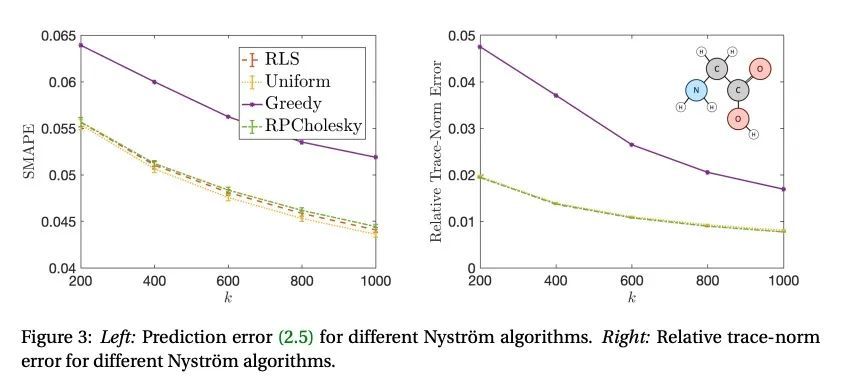
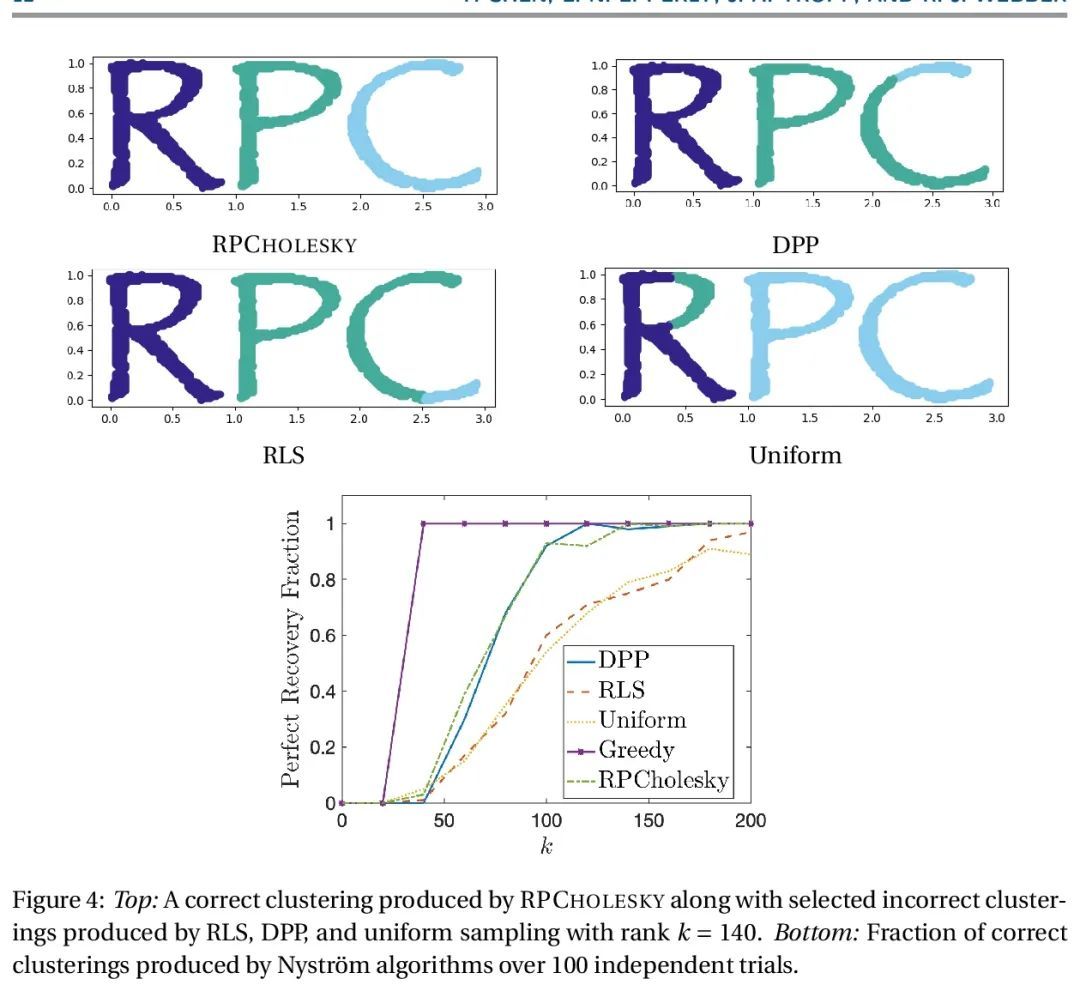
[LG] Randomly pivoted Cholesky: Practical approximation of a kernel matrix with few entry evaluations
随机旋转Cholesky:基于少项评估的实用核矩阵近似
Y Chen, E N. Epperly, J A. Tropp, R J. Webber
[California Institute of Technology, Pasadena]
https://arxiv.org/abs/2207.06503

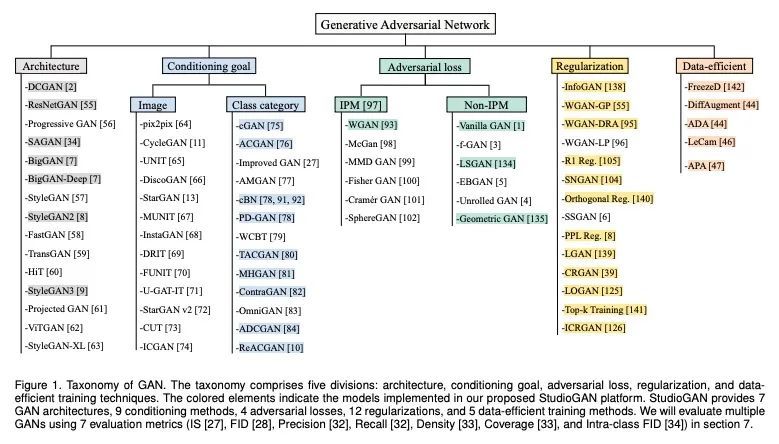
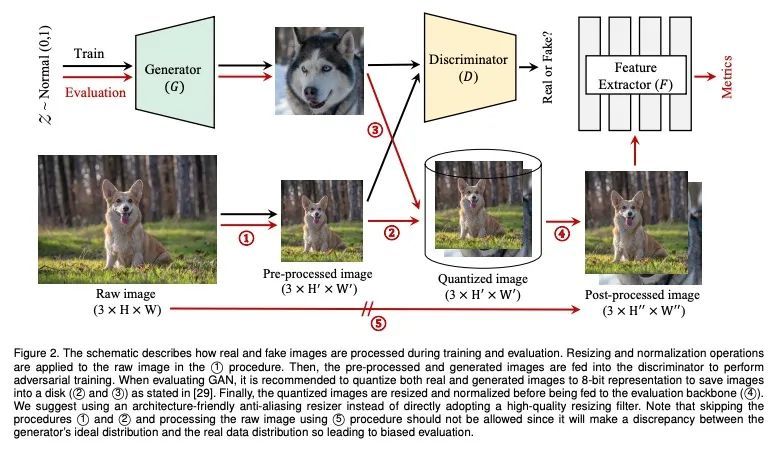
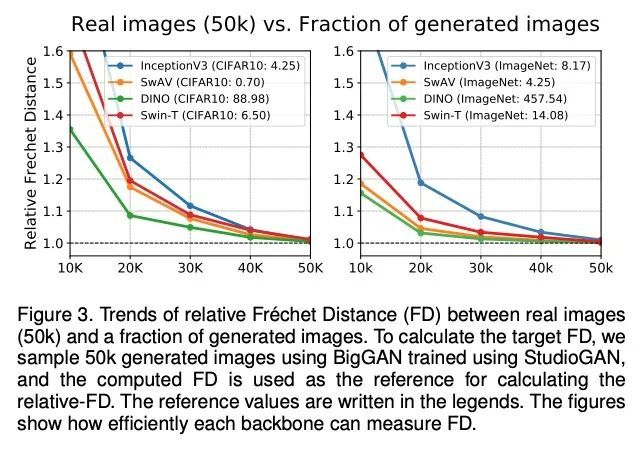
[CV] StudioGAN: A Taxonomy and Benchmark of GANs for Image Synthesis
StudioGAN:面向图像合成的GAN分类与基准
M Kang, J Shin, J Park
[POSTECH]
https://arxiv.org/abs/2206.09479


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢