
近日,Karphathy谈到了他对于自然语言重要意义的理解,并转发了一篇关于自然语言和泛化性关系的博客文章(https://evjang.com/2021/12/17/lang-generalization.html),摘录如下:
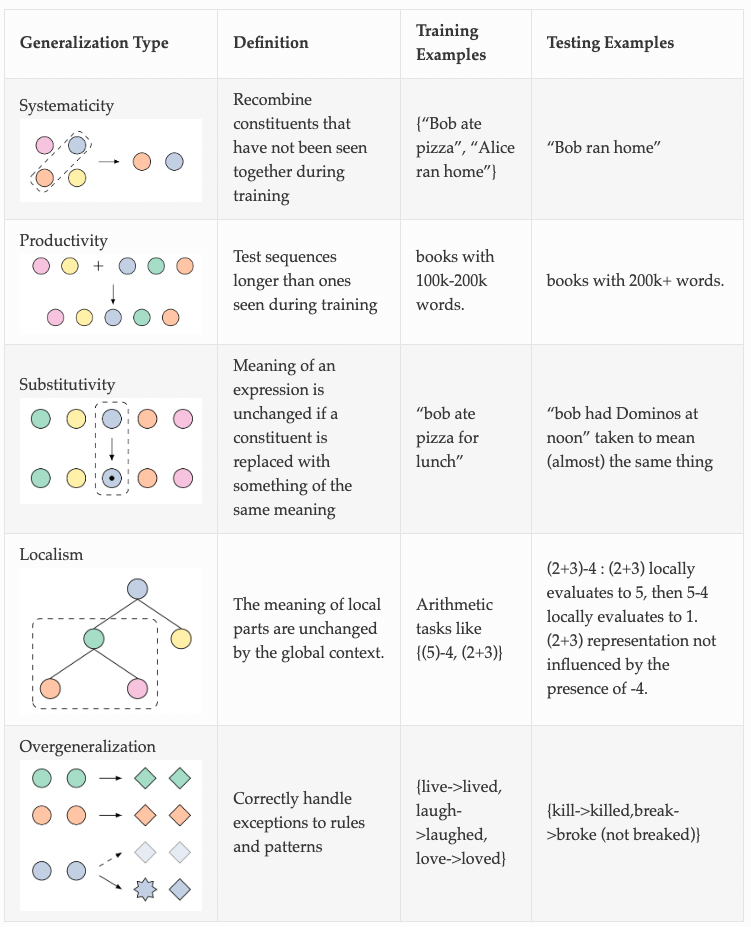
我们都希望 ML 模型能够更好地泛化,但是很难定义“泛化”。我认为语言的结构是概括的结构。如果语言模型也捕捉到泛化相对于语言的底层结构,那么也许我们可以使用语言模型将泛化“螺栓泛化”到非语言领域,例如机器人技术。
在我的文章“Just ask for Generalization”中,我认为一些优化能力,例如从次优轨迹的强化学习,通过泛化可能比通过构造更好地实现。无论如何,我们必须在部署时泛化到看不见的情况,那么为什么不把泛化能力作为一等公民,然后“只求最优”作为看不见的情况呢?这种设计理念的一个推论是,我们应该丢弃为“数据海绵”引入优化瓶颈的归纳偏差:如果归纳偏差只是“伪装的数据”,它可能不仅不再为高数据制度,但实际上阻碍了归纳偏差不再适用的示例的模型。
将尽可能多的人工编写代码推向“语言 + 深度学习魔法”听起来很有趣,但是从业者如何执行这个“只是要求泛化”的秘诀呢?如果我们想通过深度神经网络推断最佳行为而不进行明确的训练,我们需要回答棘手的问题:给定一个模型族和一些训练数据,我们可以期望模型泛化到哪些类型的测试示例? “要求太多”是多少?
无论如何,如何定义泛化? ML 理论为我们提供了一些基本定义,如泛化差距和额外风险(即训练和测试损失之间的差异),但这些定义对于估计达到训练数据中未见的定性能力程度所需的条件没有用。例如,如果我正在训练一个家用机器人能够在任何家庭中洗碗,那么在学习的策略开始在任何厨房中起作用之前,我需要在多少个家庭中收集训练数据?这个实际问题有很多形式的伪装:
“哪些数据未分发?”
“我的模型 + 数据对对抗样本是否稳健?”
“我们如何训练模型知道他们不知道的东西?”
“什么是外推?”
文章作者为Eric Zhang,他曾是谷歌机器人项目的资深研究科学家,现为Halodi Robotics 的高级副总裁。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢