
最近一个大趋势就是将各类任务统一在一个大一统框架下。大规模预训练语言模型已成功打通各类文本任务,使得不同的NLP任务上,都可以用这种统一的sequence生成框架作为基础模型,只需要通过prompt的方式,指导模型生成目标结果。
这种大一统的sequence生成框架在NLP任务成功的关键是任务描述和任务输出都可以序列化成text tokens。
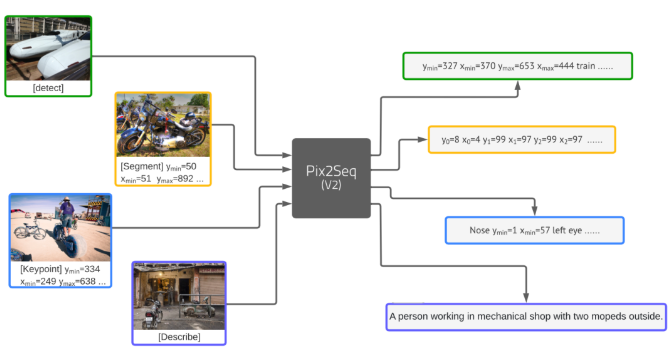
但CV任务输入输出都更加多样,那不是得为不同的任务定制不同的模型和损失函数?这也是CV任务大一统框架的瓶颈。
以自然语言为输出的任务,比如image captioning、visual question answering这类任务,天然可以转化为生成text token sequence。但模型的输出形式还存在很多其他的形式,例如bounding box、dense masks等。
Pix2Seq在这样的动机下诞生了:既然输出形式不同是难点,能否将各类输出形式都统一成token sequence?
这种大一统的Pix2Seq框架,已经能够在这四个核心视觉任务上,媲美那些专门为各任务定制的state-of-the-art。

论文题目:
A Unified Sequence Interface for Vision Tasks
论文链接:
https://arxiv.org/abs/2206.07669
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢