
作者:Dustin Tran, Jeremiah Liu, Michael W. Dusenberry,等
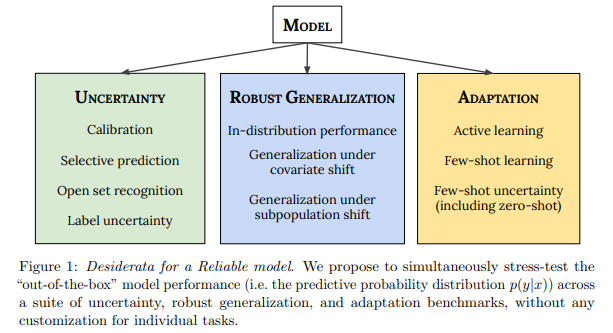
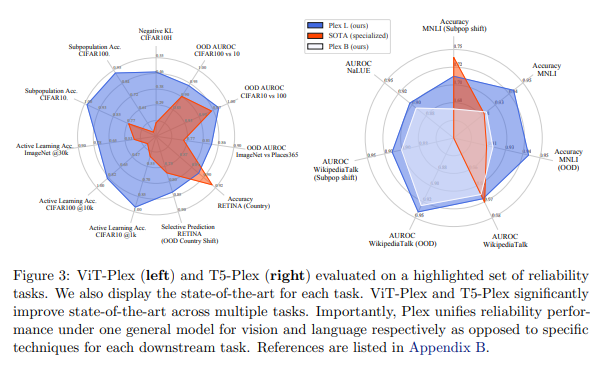
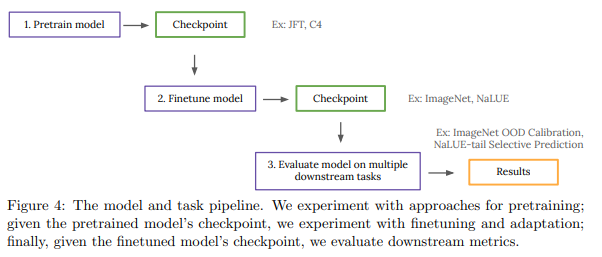
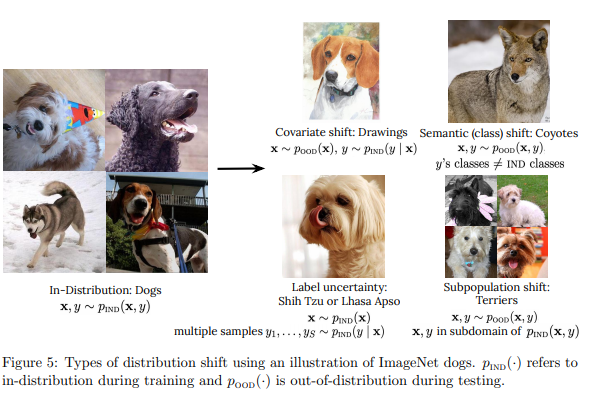
简介:基于预训练大型模型的扩展、本文研究视觉和语言领域模型可靠性的实现。人工智能最近的一个趋势是使用预训练模型来处理语言和视觉任务,它们取得了非凡的性能,但也有令人费解的失败。因此,以多种方式探索这些模型的能力对该领域至关重要。在本文中,作者探讨了模型的可靠性,作者将可靠模型定义为不仅可以实现强大的预测性能,而且在许多涉及不确定性的决策任务(例如:选择性预测、开放集识别)中表现良好的模型,稳健的泛化(例如:准确性和适当的评分规则,例如:分布内和分布外数据集的对数似然)和适应(例如,主动学习、少数样本不确定性)。作者在 40 个数据集上设计了 10 种类型的任务,以评估视觉和语言领域可靠性的不同方面。为了提高可靠性,作者开发了 ViT-Plex 和 T5-Plex,分别针对视觉和语言模式进行了预训练的大型模型扩展。Plex 极大地提高了可靠性任务的最新技术水平、并简化了传统协议,因为Plex 提高了开箱即用的性能、并且不需要为每个任务设计分数或调整模型。作者展示了对高达 1B 参数的模型大小和高达 4B 示例的预训练数据集大小的缩放效果。作者还展示了 Plex 在具有挑战性的任务上的能力,包括零样本开放集识别、主动学习和会话语言理解中的不确定性。

论文下载:https://arxiv.org/pdf/2207.07411.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢