
深度学习模型的训练就像是「黑箱操作」,知道输入是什么、输出是什么,但中间过程就像个黑匣子,这使得研究人员可能花费大量时间找出模型运行不正常的原因。假如有一款可视化的工具,能够帮助研究人员更好地理解模型行为,这应该是件非常棒的事。
近日,Google 研究人员发布了一款语言可解释性工具 (Language Interpretability Tool, LIT),这是一个开源平台,用于可视化和理解自然语言处理模型。
论文地址:https://arxiv.org/pdf/2008.05122.pdf 项目地址:https://github.com/PAIR-code/lit
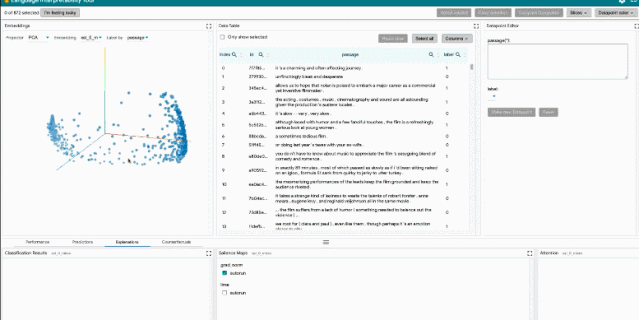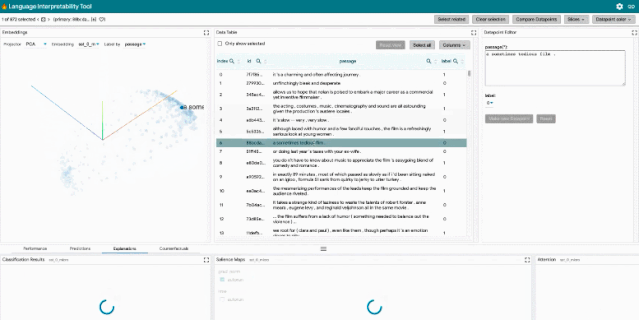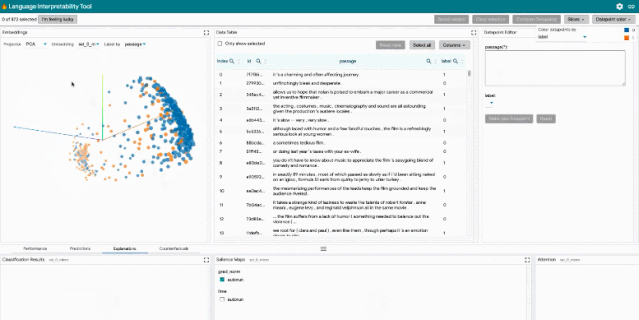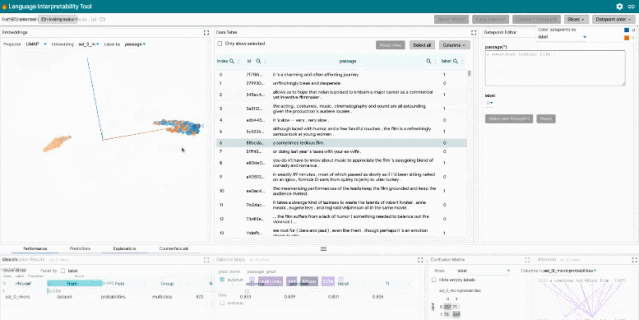 LIT 重点关注模型行为的核心问题,包括:为什么模型做出这样的预测?什么时候性能不佳?在输入变化可控的情况下会发生什么?LIT 将局部解释、聚合分析和反事实生成集成到一个流线型的、基于浏览器的界面中,以实现快速探索和错误分析。
LIT 重点关注模型行为的核心问题,包括:为什么模型做出这样的预测?什么时候性能不佳?在输入变化可控的情况下会发生什么?LIT 将局部解释、聚合分析和反事实生成集成到一个流线型的、基于浏览器的界面中,以实现快速探索和错误分析。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢