
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:社交媒体上谣言超级传播者的识别和刻画、语言模型级联、推荐系统中的人文价值建设、迁移学习分布外泛化的评估、归纳偏差对缩放的影响、面向分布外目标分割的实例感知观察器网络、教量子比特唱歌、用于点云自上而下实例分割的神经双边过滤、可泛化的基于图块的神经渲染
1、[SI] Identification and characterization of misinformation superspreaders on social media
M R. DeVerna, R Aiyappa, D Pacheco, J Bryden, F Menczer
[Indiana University]
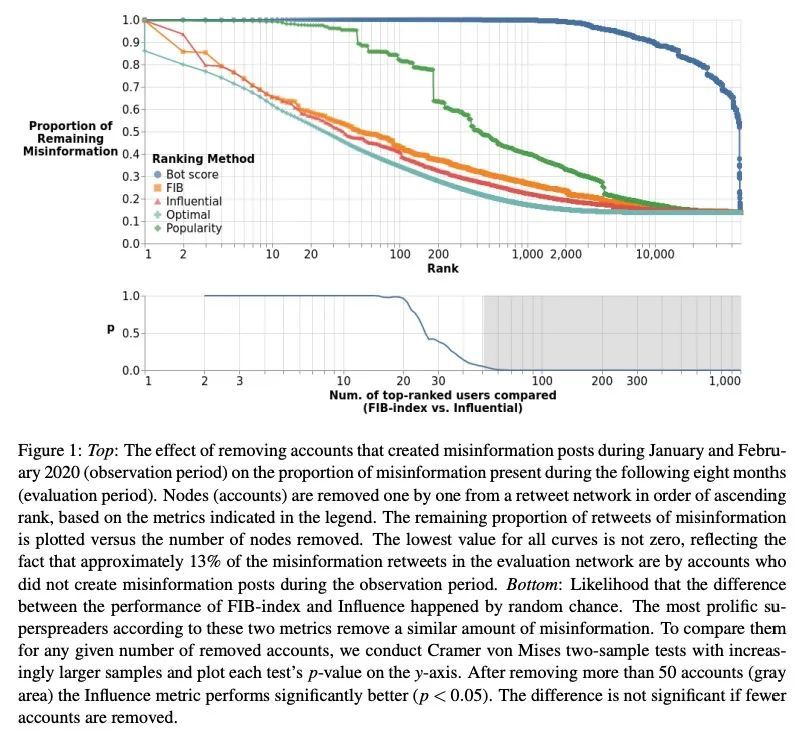
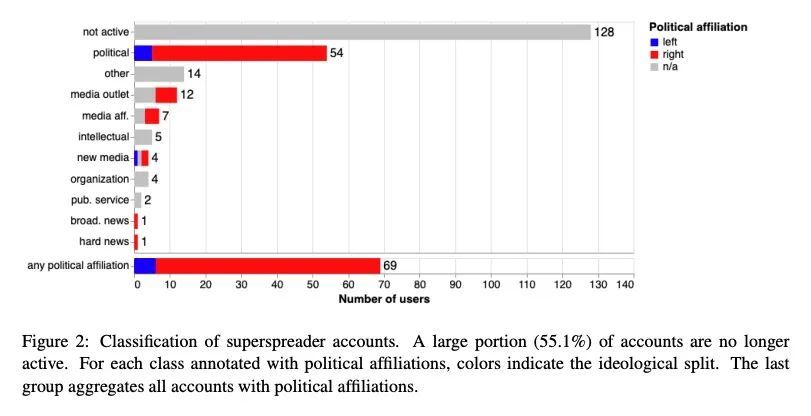
社交媒体上谣言超级传播者的识别和刻画。世界上的数字信息生态系统仍在与谣言(错误信息)的传播作斗争。之前的工作表明,持续传播大量低可信度内容的用户——所谓的超级传播者——是这个问题的中心。本文定量化证实了这一假设,并引入了简单的指标来预测未来几个月的顶级谣言超级传播者。进行了一次定性审查,以确定最多产的超级传播者的特征,分析他们的分享行为。超级传播者包括拥有大量粉丝的学者、低信誉的媒体机构、与这些媒体机构相关的个人账户,以及一系列有影响力的人。他们主要是政治性的,比分享错误信息的典型用户使用更多的有毒语言。本文还发现了令人担忧的证据,表明Twitter可能忽略了突出的超级传播者。希望这项工作能够促进公众对不良行为者的理解,并促进采取措施,减轻他们对健康的数字话语的负面影响。
The world’s digital information ecosystem continues to struggle with the spread of misinformation. Prior work has suggested that users who consistently disseminate a disproportionate amount of lowcredibility content — so-called superspreaders — are at the center of this problem. We quantitatively confirm this hypothesis and introduce simple metrics to predict the top misinformation superspreaders several months into the future. We then conduct a qualitative review to characterize the most prolific superspreaders and analyze their sharing behaviors. Superspreaders include pundits with large followings, low-credibility media outlets, personal accounts affiliated with those media outlets, and a range of influencers. They are primarily political in nature and use more toxic language than the typical user sharing misinformation. We also find concerning evidence suggesting that Twitter may be overlooking prominent superspreaders. We hope this work will further public understanding of bad actors and promote steps to mitigate their negative impacts on healthy digital discourse.
https://arxiv.org/abs/2207.09524



2、[CL] Language Model Cascades
D Dohan, W Xu, A Lewkowycz, J Austin, D Bieber, R G Lopes, Y Wu, H Michalewski, R A. Saurous, J Sohl-dickstein, K Murphy, C Sutton
[Google Research & Alphabet]
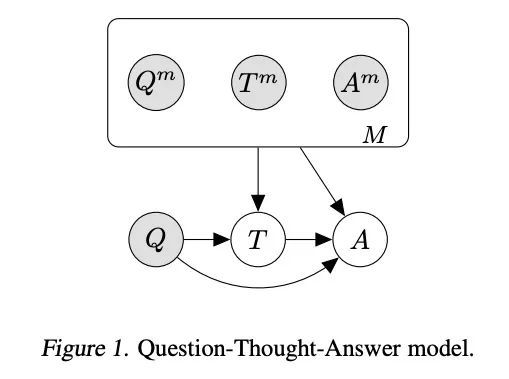
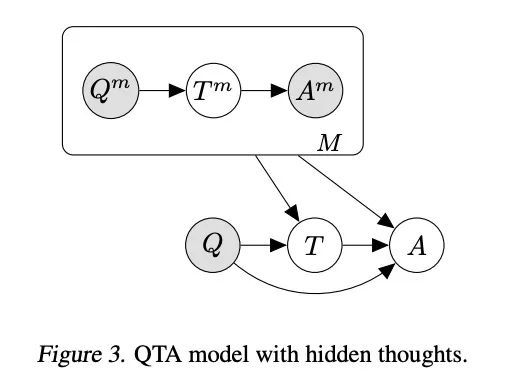
语言模型级联。提示模型已经展示了令人印象深刻的少样本学习能力。在测试时与单个模型的重复交互,或将多个模型组合在一起,进一步扩大了能力。这些组合是概率模型,可以用随机变量的图模型语言表达,其值是复杂的数据类型,如字符串。具有控制流和动态结构的案例需要来自概率编程的技术,这些技术允许用统一的语言实现不同的模型结构和推理策略。本文从这个角度对现有的几种技术进行了形式化,包括scratchpads/思维链、验证器、STaR、选择推理和工具使用。把产生的程序称为语言模型级联。
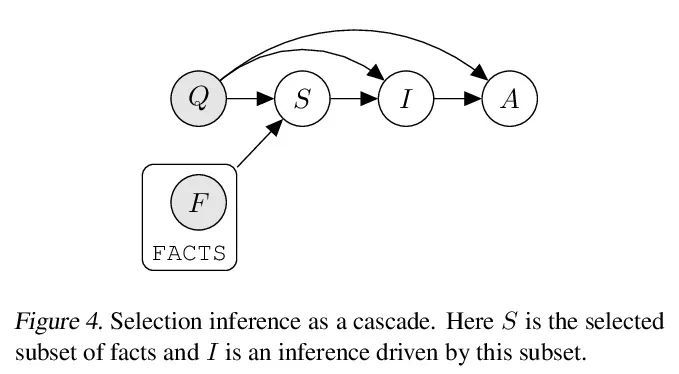
Prompted models have demonstrated impressive few-shot learning abilities. Repeated interactions at test-time with a single model, or the composition of multiple models together, further expands capabilities. These compositions are probabilistic models, and may be expressed in the language of graphical models with random variables whose values are complex data types such as strings. Cases with control flow and dynamic structure require techniques from probabilistic programming, which allow implementing disparate model structures and inference strategies in a unified language. We formalize several existing techniques from this perspective, including scratchpads / chain of thought, verifiers, STaR, selection-inference, and tool use. We refer to the resulting programs as language model cascades.
https://arxiv.org/abs/2207.10342


3、[IR] Building Human Values into Recommender Systems: An Interdisciplinary Synthesis
J Stray, A Halevy, P Assar, D Hadfield-Menell, C Boutilier, A Ashar...
[UC Berkeley & Meta AI & MIT & Google Research & Spotify Inc...]
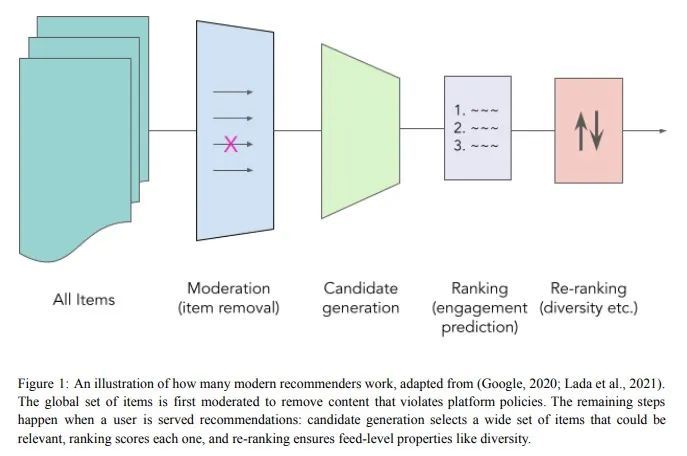
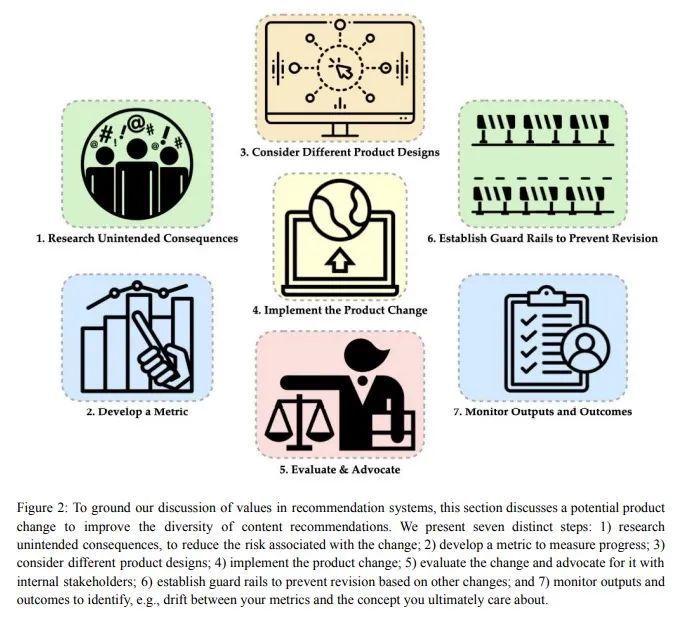
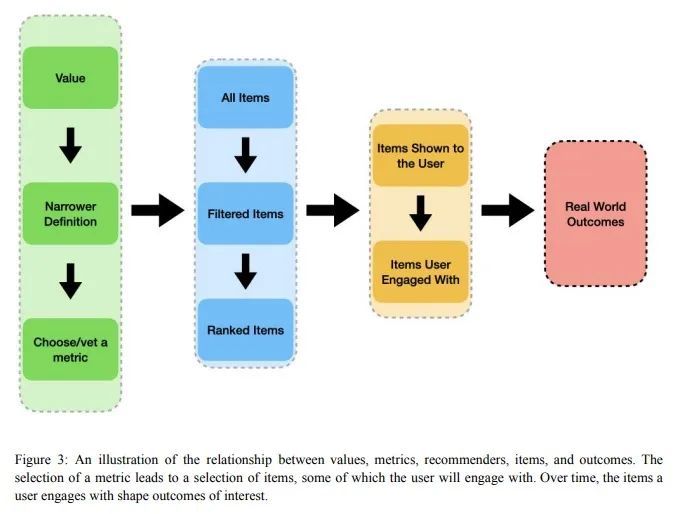
推荐系统中的人文价值建设:跨学科综合报告。推荐系统是在世界许多最大的平台和应用程序中选择、过滤和个性化内容的算法。因此,他们对个人和社会的积极和消极影响已经被广泛地理论化和研究。本文的首要问题是如何确保推荐系统能够实现它们所服务的个人和社会的价值。以一种有原则的方式解决这个问题需要推荐器设计和操作的技术知识,同时也关键取决于来自不同领域的见解,包括社会科学、伦理学、经济学、心理学、政策和法律。本文是一个多学科的努力,从不同的角度综合了理论和实践,目的是提供一种共同的语言,阐明当前的设计方法,并确定开放的问题。它并不是对这个大空间的全面调查,而是由本文不同的作者群所确定的一组亮点。本文收集了一组与不同领域的推荐系统最相关的价值,然后从当前的行业实践、测量、产品设计和政策方法的角度对它们进行了研究。重要的开放性问题包括定义价值和解决权衡的多方利益相关者过程、更好的价值驱动的测量、人们使用的推荐器控制、非行为的算法反馈、长期结果的优化、推荐器效果的因果推断、学术-产业研究合作以及跨学科的政策制定。
Recommender systems are the algorithms which select, filter, and personalize content across many of the world’s largest platforms and apps. As such, their positive and negative effects on individuals and on societies have been extensively theorized and studied. Our overarching question is how to ensure that recommender systems enact the values of the individuals and societies that they serve. Addressing this question in a principled fashion requires technical knowledge of recommender design and operation, and also critically depends on insights from diverse fields including social science, ethics, economics, psychology, policy and law. This paper is a multidisciplinary effort to synthesize theory and practice from different perspectives, with the goal of providing a shared language, articulating current design approaches, and identifying open problems. It is not a comprehensive survey of this large space, but a set of highlights identified by our diverse author cohort. We collect a set of values that seem most relevant to recommender systems operating across different domains, then examine them from the perspectives of current industry practice, measurement, product design, and policy approaches. Important open problems include multi-stakeholder processes for defining values and resolving trade-offs, better values-driven measurements, recommender controls that people use, non-behavioral algorithmic feedback, optimization for long-term outcomes, causal inference of recommender effects, academic-industry research collaborations, and interdisciplinary policy-making.
https://arxiv.org/abs/2207.10192


4、[LG] Assaying Out-Of-Distribution Generalization in Transfer Learning
F Wenzel, A Dittadi, P V Gehler, C Simon-Gabriel, M Horn, D Zietlow, D Kernert, C Russell...
[AWS Tübingen & Technical University of Denmark]
迁移学习分布外泛化的评估。由于分布外泛化是一个普遍存在的问题,在不同的项目中研究了各种代理目标(例如,校准、对抗性鲁棒性、算法腐坏、跨漂移不变性),从而产生了不同的建议。虽然有相同的愿望目标,但这些方法从未在相同的实验条件下对真实数据进行过测试。本文对之前的工作采取统一的观点,强调了通过经验解决的信息差异,并就如何衡量一个模型的鲁棒性以及如何改进提供了建议。为此,本文收集了172个公开可用的数据集对,用于训练和分布外评估准确性、校准误差、对抗性攻击、环境不变性和合成腐坏。对超过31000个网络进行了微调,这些网络来自九种不同的架构,在多样本和少样本的设置下。研究结果证实,分布内和分布外的准确度倾向于联合增加,它们的关系在很大程度上取决于数据集,而且总的来说比之前较小规模的研究所假设的更细微和更复杂。
Since out-of-distribution generalization is a generally ill-posed problem, various proxy targets (e.g., calibration, adversarial robustness, algorithmic corruptions, invariance across shifts) were studied across different research programs resulting in different recommendations. While sharing the same aspirational goal, these approaches have never been tested under the same experimental conditions on real data. In this paper, we take a unified view of previous work, highlighting message discrepancies that we address empirically, and providing recommendations on how to measure the robustness of a model and how to improve it. To this end, we collect 172 publicly available dataset pairs for training and out-of-distribution evaluation of accuracy, calibration error, adversarial attacks, environment invariance, and synthetic corruptions. We fine-tune over 31k networks, from nine different architectures in the manyand few-shot setting. Our findings confirm that inand out-of-distribution accuracies tend to increase jointly, but show that their relation is largely dataset-dependent, and in general more nuanced and more complex than posited by previous, smaller scale studies.
https://arxiv.org/abs/2207.09239


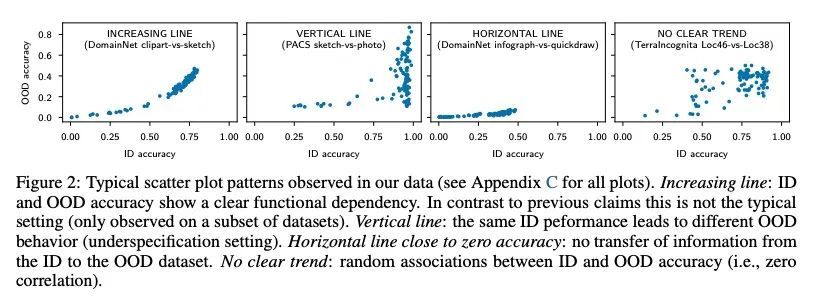


5、[LG] Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling?
Y Tay, M Dehghani, S Abnar, H W Chung, W Fedus, J Rao, S Narang, V Q. Tran, D Yogatama, D Metzler
[Google Research & DeepMind]
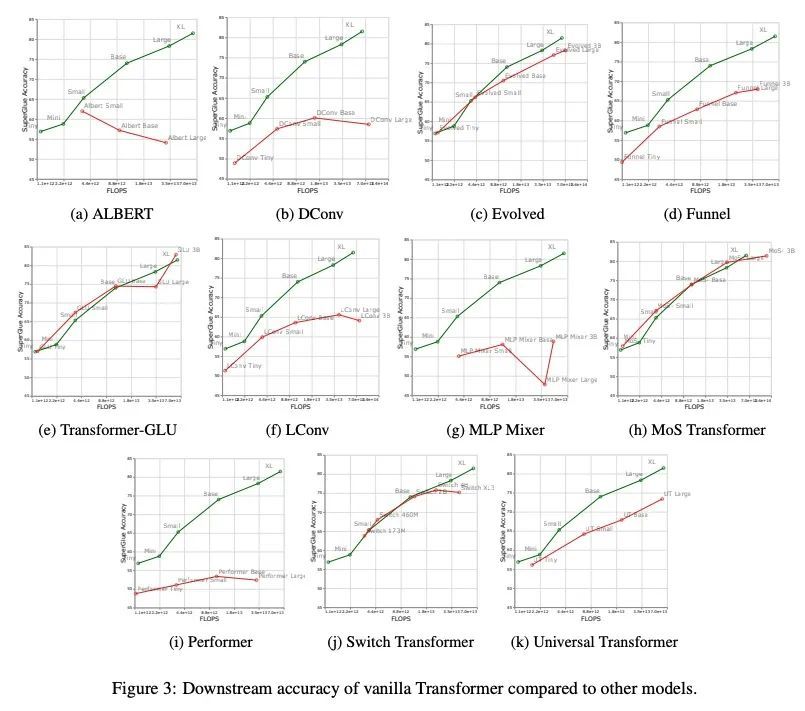
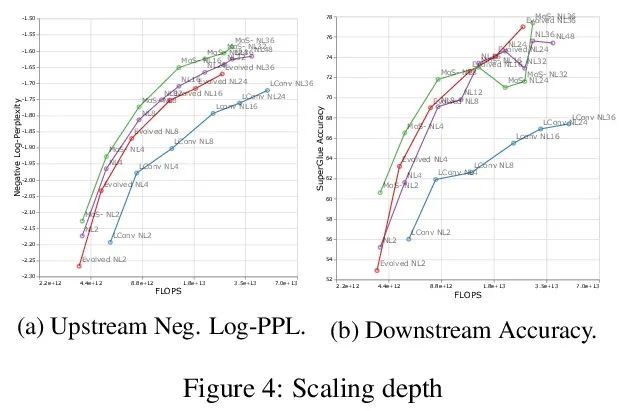
缩放律与模型架构:归纳偏差对缩放的影响。人们对Transformer模型的缩放特性很感兴趣。然而,在研究不同的归纳偏差和模型结构的缩放特性的影响方面,还没有做很多工作。模型架构是否有不同的扩展性?如果是这样,归纳偏差是如何影响扩展行为的?这如何影响上游(预训练)和下游(迁移)?本文对十种不同的模型架构的扩展行为进行了系统研究,如Transformer、Switch Transformer、Universal Transformer、动态卷积、Performer和最近提出的MLP-Mixer。通过广泛的实验,本文表明:(1)在进行扩展时,结构确实是一个重要的考虑因素;(2)性能最好的模型在不同的尺度上会有波动。本文相信,这项工作中的发现对目前社区评估模型架构的方式有重大影响。
There have been a lot of interest in the scaling properties of Transformer models (Kaplan et al., 2020). However, not much has been done on the front of investigating the effect of scaling properties of different inductive biases and model architectures. Do model architectures scale differently? If so, how does inductive bias affect scaling behaviour? How does this influence upstream (pretraining) and downstream (transfer)? This paper conducts a systematic study of scaling behaviour of ten diverse model architectures such as Transformers, Switch Transformers, Universal Transformers, Dynamic convolutions, Performers, and recently proposed MLP-Mixers. Via extensive experiments, we show that (1) architecture is an indeed an important consideration when performing scaling and (2) the best performing model can fluctuate at different scales. We believe that the findings outlined in this work has significant implications to how model architectures are currently evaluated in the community.
https://arxiv.org/abs/2207.10551



另外几篇值得关注的论文:
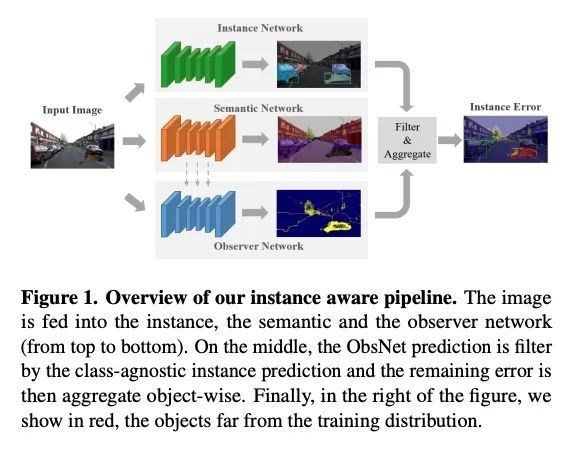
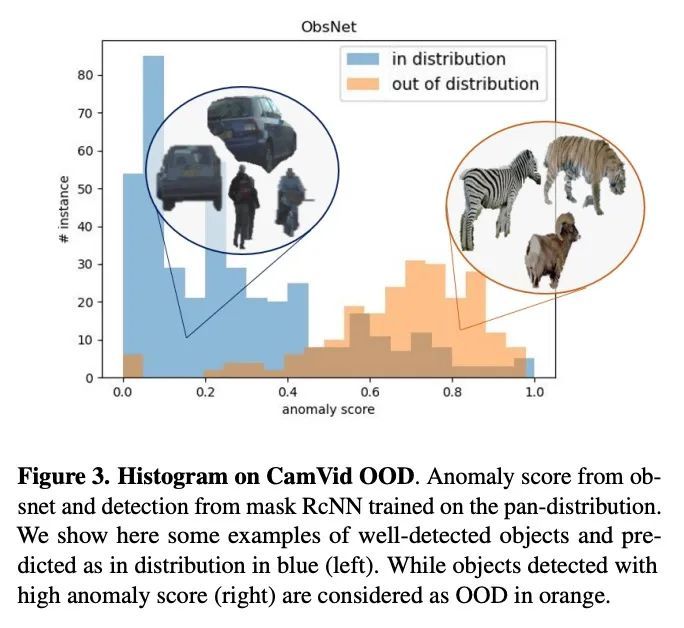
[CV] Instance-Aware Observer Network for Out-of-Distribution Object Segmentation
面向分布外目标分割的实例感知观察器网络
V Besnier, A Bursuc, D Picard, A Briot
[Valeo & Univ Gustave Eiffel]
https://arxiv.org/abs/2207.08782



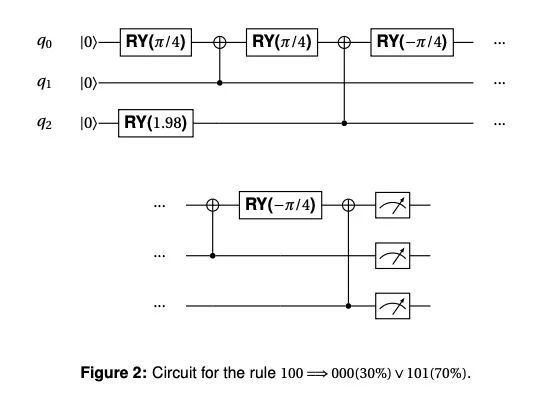
[AI] Teaching Qubits to Sing: Mission Impossible?
教量子比特唱歌:不可能的任务?
E R Miranda, B N. Siegelwax
[University of Plymouth]
https://arxiv.org/abs/2207.08225




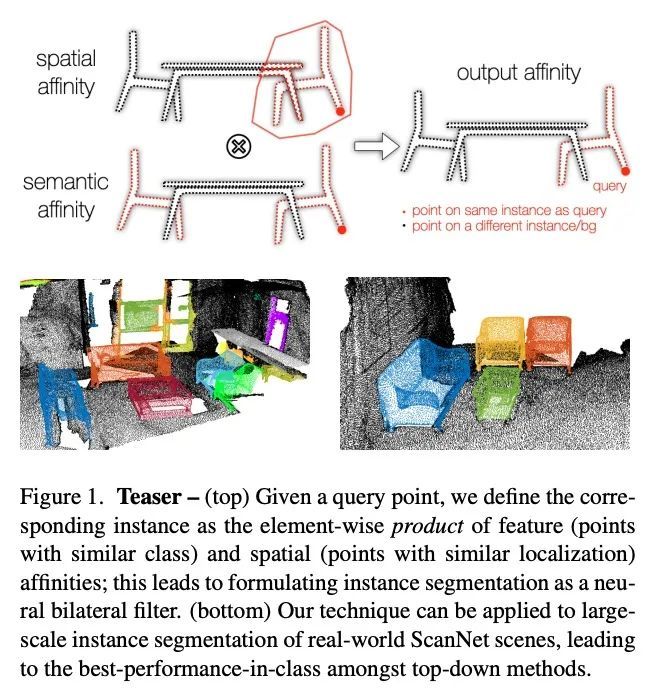
[CV] NeuralBF: Neural Bilateral Filtering for Top-down Instance Segmentation on Point Clouds
NeuralBF:用于点云自上而下实例分割的神经双边过滤
W Sun, D Rebain, R Liao, V Tankovich, S Yazdani, K M Yi, A Tagliasacchi
[University of British Columbia & Google Research]
https://arxiv.org/abs/2207.09978




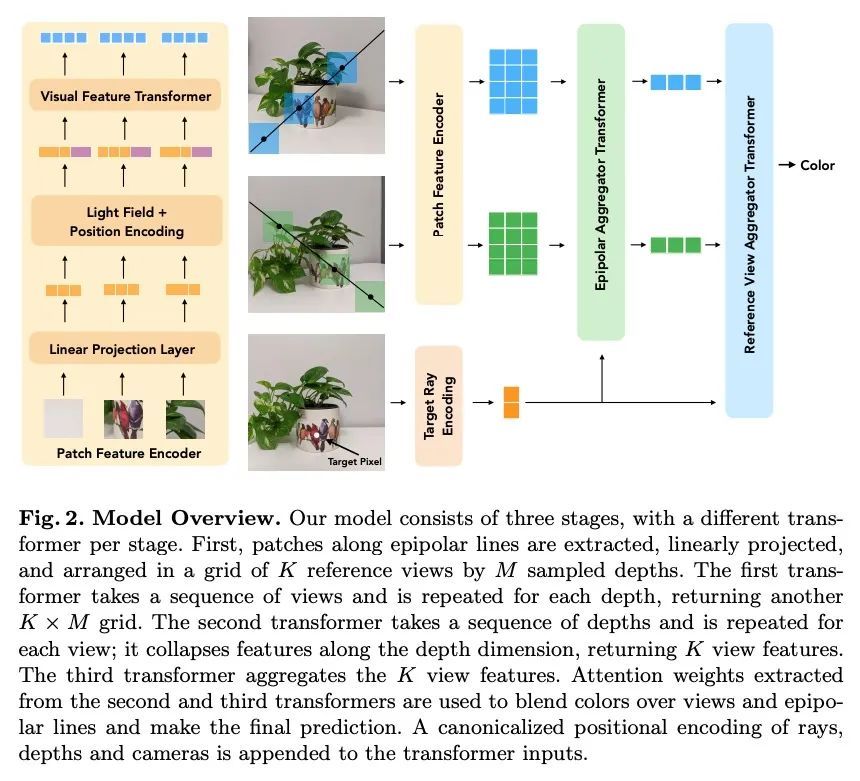
[CV] Generalizable Patch-Based Neural Rendering
可泛化的基于图块的神经渲染
M Suhail, C Esteves, L Sigal, A Makadia
[University of British Columbia & Google]
https://arxiv.org/abs/2207.10662




内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢