【标题】Addressing Optimism Bias in Sequence Modeling for Reinforcement Learning
【作者团队】Adam Villaflor, Zhe Huang, Swapnil Pande, John Dolan, Jeff Schneider
【发表日期】2022.7.21
【论文链接】https://arxiv.org/pdf/2207.10295.pdf
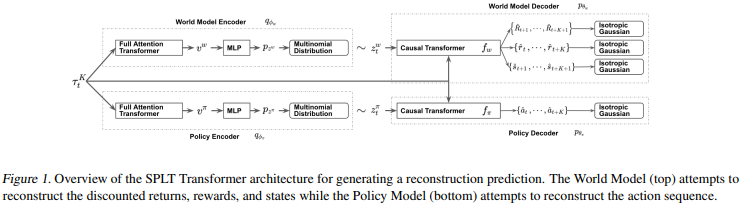
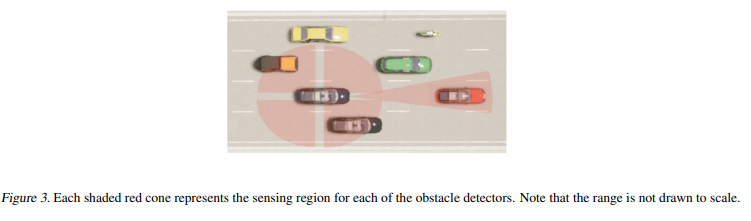
【推荐理由】基于 Transformer 神经网络架构的自然语言处理 (NLP) 取得了令人瞩目的成果,这激发了研究人员探索将离线强化学习 (RL) 视为通用序列建模问题。最近基于这种范式的工作在几个主要是确定性的离线 Atari 和 D4RL 基准测试中取得了最先进的结果。然而,由于这些方法将状态和行动联合建模为一个单一的排序问题,它们难以解开政策和世界动态对回报的影响。因此,在对抗性或随机环境中,这些方法会导致过度乐观的行为,这在自动驾驶等安全关键系统中可能是危险的。本文通过明确解开策略和世界模型来解决这种乐观偏见,这使该方法能够在测试时搜索对环境中多种可能的未来具有鲁棒性的策略。并在模拟中展示了该方法在各种自动驾驶任务中的卓越性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢