
在机器学习领域,通过扩大模型规模来提高其性能已经得到了许多成功的经验。事实上通过诸如视觉识别、自然语言处理等许多人工智能子领域积累的经验,都观察到一个规律,即深度学习的误差随着训练数据集大小、模型大小或计算量按照幂律规律而减小,这一规律被称为神经缩放定律。
尽管在这一规律的推动下,深度学习的性能在近年来实现了突飞猛进的发展。但是从另一个角度看,这种幂律缩放也导致了巨量的资源消耗,包括数据收集、计算以及能源消耗等各个方面。
而且按照幂律缩放规律来提高深度学习的性能是一种非常不可持续的策略,有时仅仅是为了将误差降低一个百分之一,需要投入的训练数据规模和计算量或许就要增加一个数量级 。
例如,如果希望让某个大型视觉预训练模型在著名的视觉数据集 ImageNet 上的准确度提高几个百分点,有时需要再增加 20 亿个预训练数据点。
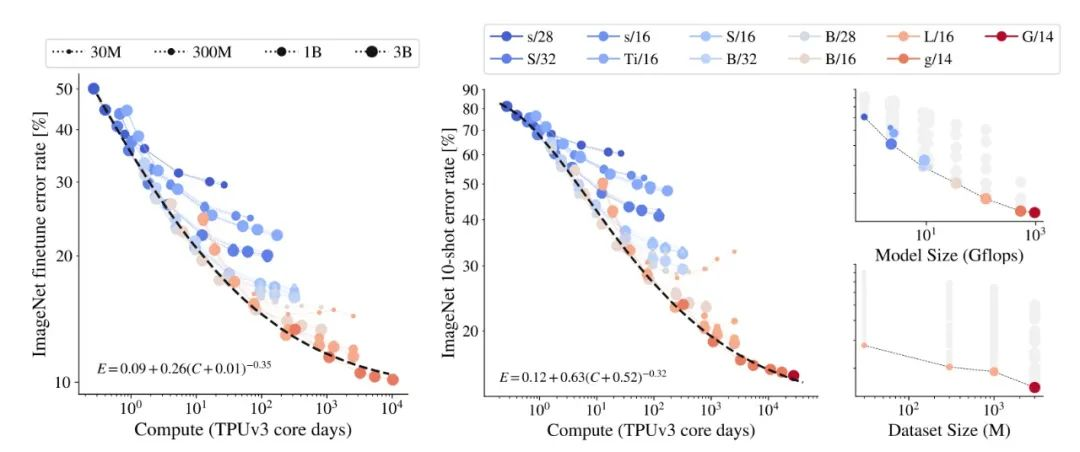
▲图|视觉预训练模型在视觉数据集 ImageNet 上的准确度提高几个百分点,所需的计算量成幂律增加(来源:arXiv)
是否有一种方法可以突破幂律缩放规则,而不是像之前那样,误差每降低一个百分点,就需要多收集 10 倍以上的训练样本或计算量呢?
最近,Meta AI 的研究人员发现,通过对训练样本的精心挑选,原则上可以在规模更小的、经过剪裁的数据集上,通过训练实现同样的性能,尤其是误差方面。该研究还证明,指数缩放在理论和实践上都是可实现的,尤为重要的是该论文发现目前普遍认为的误差与模型大小之间呈幂律缩放规律造成了训练数据量的高度冗余。
这一研究由来自斯坦福大学应用物理系的本·索舍尔(Ben Sorscher)以及来自德国蒂宾根大学的罗伯特·吉尔霍斯(Robert Geirhos)在 Meta AI 实验室实习期间,联合 Meta AI 工程师沙尚克·谢卡尔(Shashank Shekhar)等人共同完成。
该研究成果也以《超越神经缩放定律:通过数据剪裁突破幂律缩放规则》(Beyond neural scaling laws: beating power law scaling via data pruning)为题的论文发表在了 arXiv 上。
根据该研究,按照以下两条原则对数据进行裁剪,将很可能有效地突破幂律缩放规则。
其一,不同模型的最佳数据裁剪策略是根据初始数据量而变化的,对于初始数据量丰富的模型来说,应保留最困难的样本;而对于那些初始数据稀缺的模型来说,则应当将更简单的样本保留。
其二,通过对初始数据的裁剪,误差随模型大小呈指数缩放是可以实现的;而且可以实现的帕累托最优误差的裁减参数,还可以表达为与初始数据集的大小之间的函数关系。
在这一研究中,数据裁剪的方法不仅从理论上得到了推断,更从实践中得到了验证。研究人员分别在用于视觉识别的多个业界广泛认可的包括 SVHN、CIFAR-10 以及 ImageNet 等数据集上,按照上述方法进行数据裁剪,并对残差神经网络 ResNet 进行训练。
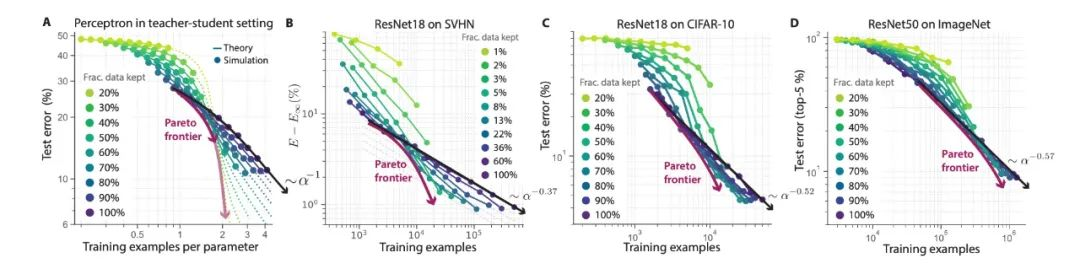
▲图|通过数据剪裁,在 SVHN、CIFAR-10 以及 ImageNet 等数据集上训练残差神经网络 ResNet 模型时,都实现了误差随模型大小呈指数缩放(来源:arXiv)
在这些数据集中,都通过数据剪裁实现了误差随模型大小呈指数缩放。
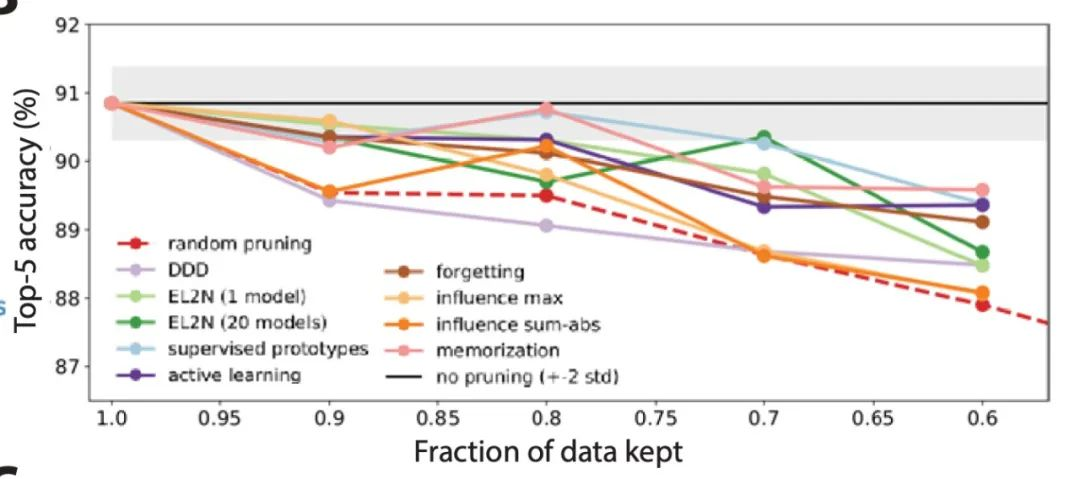
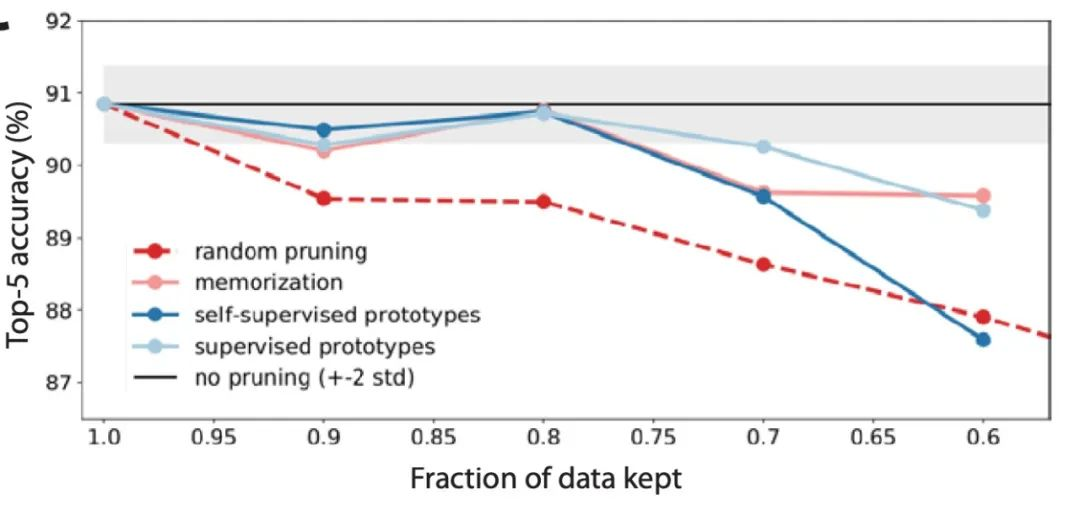
▲图|在 ImageNet 数据集上对 10 种不同的数据裁剪指标进行大规模的基准测试研究(来源:arXiv)
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢