
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:用单张图像集合学习生成自然场景的无限穿越视频、通过自监督静态-动态解缠从单幅图像看到3D物体、全景场景图生成、基于交替优化的可解释视频超分辨率、神经人脸渲染数据集、面向舞蹈动作合成的霹雳舞比赛数据集、离散键值瓶颈、从消息传递角度重新审视基于因子分解模型、现实Bug定位基准
1、[CV] InfiniteNature-Zero: Learning Perpetual View Generation of Natural Scenes from Single Images
Z Li, Q Wang, N Snavely, A Kanazawa
[Google Research & Cornell University & UC Berkeley]
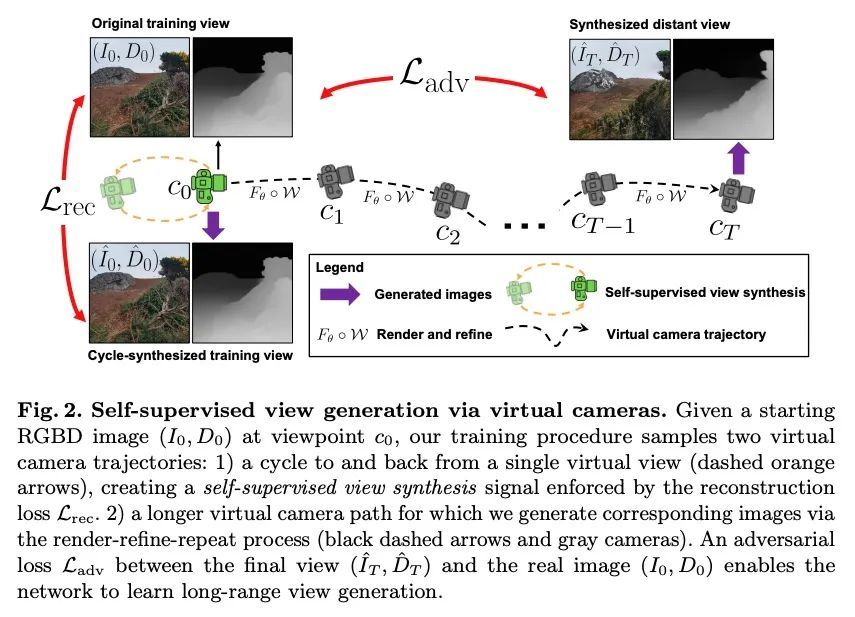
InfiniteNature-Zero:用单张图像集合学习生成自然场景的无限穿越视频。本文提出一种方法,用于学习从单个视图开始生成自然景物的无界飞越视频。这种能力是从单照片集合中学习的,不需要相机的姿态,甚至不需要每个场景的多个视图。为实现这一目标,本文提出一种新的自监督视图生成训练范式,对虚拟摄像机轨迹进行采样和渲染,包括循环的摄像机路径,使模型能从单视图集合中学习稳定的视图生成。测试时,尽管从未见过视频,但该方法可采用单一图像,生成由数百个具有逼真和多样化内容的新视图组成的长相机轨迹。将所提出方法与最近最先进的需要摆放多视图视频的监督视图生成方法进行了比较,并展示了卓越的性能和合成质量。
We present a method for learning to generate unbounded flythrough videos of natural scenes starting from a single view. This capability is learned from a collection of single photographs, without requiring camera poses or even multiple views of each scene. To achieve this, we propose a novel self-supervised view generation training paradigm where we sample and render virtual camera trajectories, including cyclic camera paths, allowing our model to learn stable view generation from a collection of single views. At test time, despite never having seen a video, our approach can take a single image and generate long camera trajectories comprised of hundreds of new views with realistic and diverse content. We compare our approach with recent state-of-the-art supervised view generation methods that require posed multi-view videos and demonstrate superior performance and synthesis quality. Our project webpage, including video results, is at infinite-nature-zero.github.io.
https://arxiv.org/abs/2207.11148




2、[CV] Seeing 3D Objects in a Single Image via Self-Supervised Static-Dynamic Disentanglement
P Sharma, A Tewari, Y Du, S Zakharov, R Ambrus, A Gaidon, W T. Freeman, F Durand...
[MIT & Toyota Research Institute] (2022)
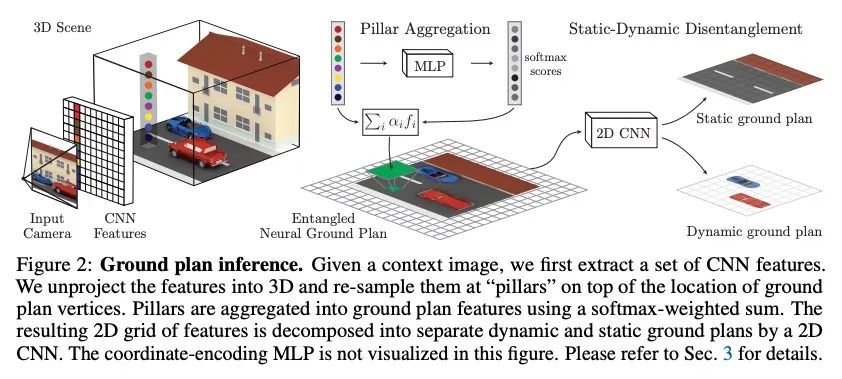
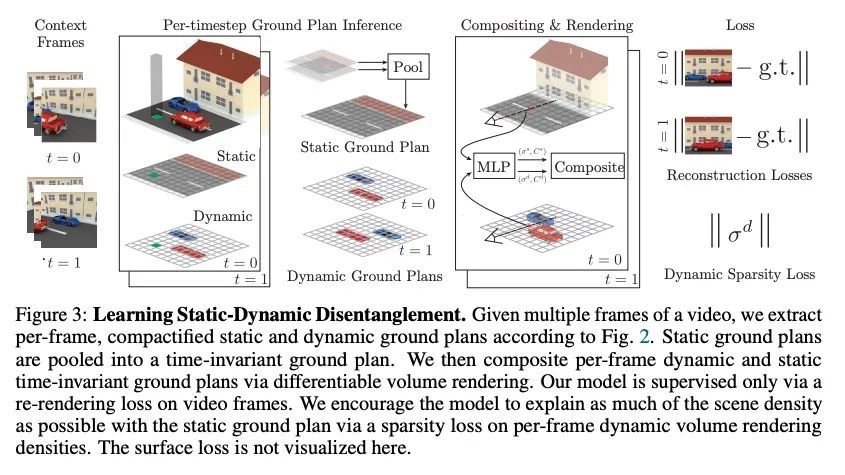
通过自监督静态-动态解缠从单幅图像看到3D物体。人类的感知能可靠地识别3D场景中可移动和不可移动的部分,并通过不完全观察完成物体和背景的3D结构。人不是通过标记的样本来学习这种技能,而是仅通过观察物体的移动来学习。本文提出一种方法,在训练时观察无标签的多视角视频,并学习将复杂场景的单图像观察,如有汽车的街道,映射到3D神经场景表示,该表示被分解为可移动和不可移动的部分,同时合理地完成其3D结构。通过2D神经地平面图分别对可移动和不可移动的场景部分进行参数化。神经地平面是与地平面对齐的特征的2D网格,可被局部解码为3D神经辐射场。该模型通过神经渲染进行自监督训练。实验证明分解的3D表示的固有结构能在街道规模的3D场景中用简单的启发式方法完成各种下游任务,如提取以物体为中心的3D表示、新视图合成、实例分割和3D边框预测,突出了其作为数据高效3D场景理解模型的骨干价值。这种解缠进一步实现了通过对象操作(如删除、插入和刚体运动)进行场景编辑。
Human perception reliably identifies movable and immovable parts of 3D scenes, and completes the 3D structure of objects and background from incomplete observations. We learn this skill not via labeled examples, but simply by observing objects move. In this work, we propose an approach that observes unlabeled multiview videos at training time and learns to map a single image observation of a complex scene, such as a street with cars, to a 3D neural scene representation that is disentangled into movable and immovable parts while plausibly completing its 3D structure. We separately parameterize movable and immovable scene parts via 2D neural ground plans. These ground plans are 2D grids of features aligned with the ground plane that can be locally decoded into 3D neural radiance fields. Our model is trained self-supervised via neural rendering. We demonstrate that the structure inherent to our disentangled 3D representation enables a variety of downstream tasks in street-scale 3D scenes using simple heuristics, such as extraction of objectcentric 3D representations, novel view synthesis, instance segmentation, and 3D bounding box prediction, highlighting its value as a backbone for data-efficient 3D scene understanding models. This disentanglement further enables scene editing via object manipulation such as deletion, insertion, and rigid-body motion.
https://arxiv.org/abs/2207.11232



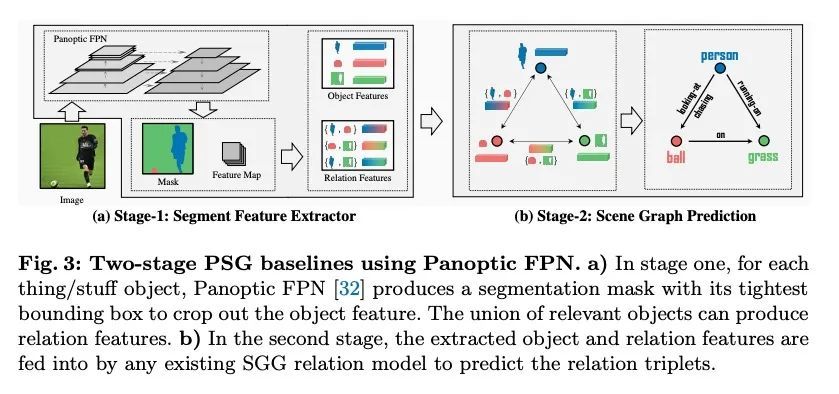
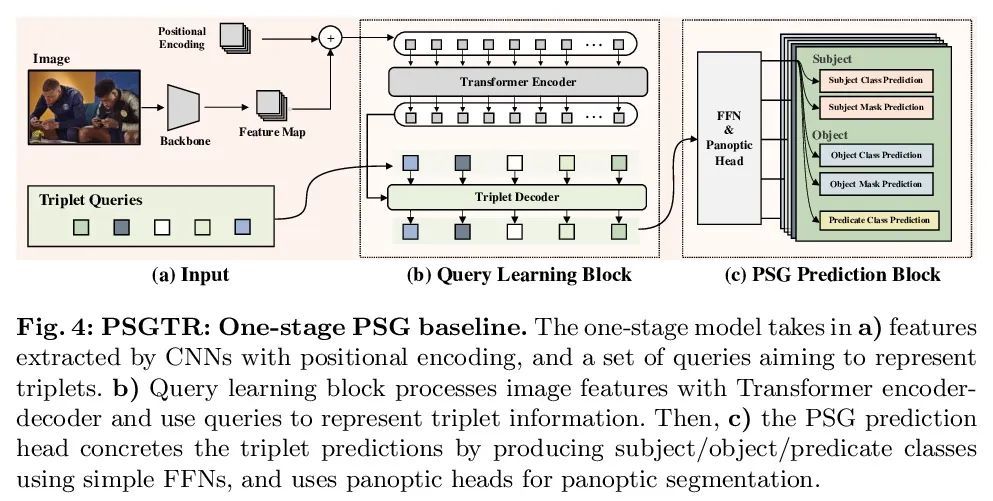
3、[CV] Panoptic Scene Graph Generation
J Yang, Y Z Ang, Z Guo, K Zhou, W Zhang, Z Liu
[Nanyang Technological University & SenseTime Research]
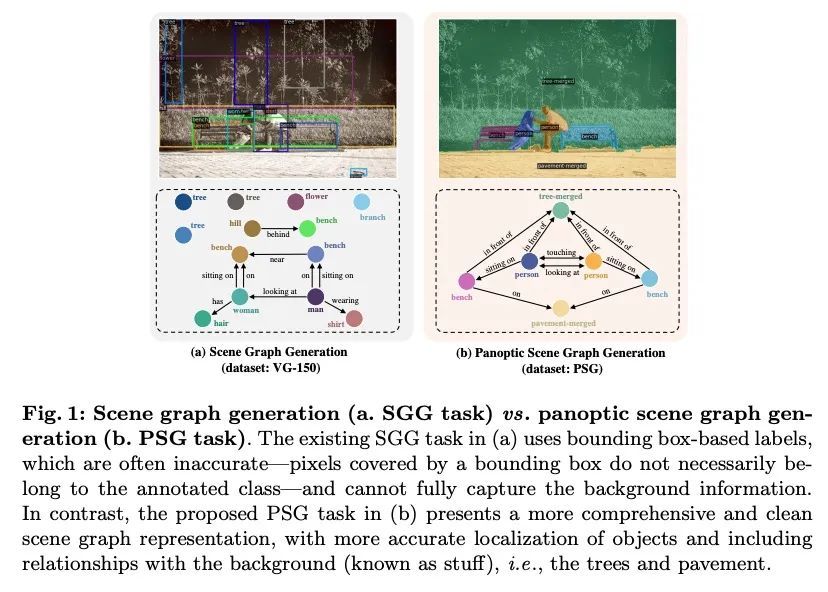
全景场景图生成。现有研究从检测的角度解决场景图生成(SGG)——图像中场景理解的一项关键技术,用边框检测物体,然后预测它们的配对关系。本文认为,这样的范式导致了一些问题,阻碍了该领域的发展。例如,当前数据集中基于边框的标签通常包含像毛发这样的冗余类,并且遗漏了对理解上下文至关重要的背景信息。本文提出全景场景图生成(PSG),一个新的问题任务,要求模型在全景分割的基础上生成一个更全面的场景图表示,而不是刚性的边框。创建了一个高质量的PSG数据集,其中包含来自COCO和Visual Genome的49k个良好标注的交叠图像,供社区跟踪其进展。为进行基准测试,本文建立了四个两阶段基线,这些基线是根据SGG的经典方法修改的,还有两个单阶段基线,称为PSGTR和PSGFormer,基于高效的Transformer检测器,即DETR。PSGTR用一组查询来直接学习三联体,而PSGFormer则以两个Transformer解码器的查询形式分别对对象和关系进行建模,然后采用类似提示的关系-对象匹配机制。
Existing research addresses scene graph generation (SGG) -- a critical technology for scene understanding in images -- from a detection perspective, i.e., objects are detected using bounding boxes followed by prediction of their pairwise relationships. We argue that such a paradigm causes several problems that impede the progress of the field. For instance, bounding box-based labels in current datasets usually contain redundant classes like hairs, and leave out background information that is crucial to the understanding of context. In this work, we introduce panoptic scene graph generation (PSG), a new problem task that requires the model to generate a more comprehensive scene graph representation based on panoptic segmentations rather than rigid bounding boxes. A high-quality PSG dataset, which contains 49k well-annotated overlapping images from COCO and Visual Genome, is created for the community to keep track of its progress. For benchmarking, we build four two-stage baselines, which are modified from classic methods in SGG, and two one-stage baselines called PSGTR and PSGFormer, which are based on the efficient Transformer-based detector, i.e., DETR. While PSGTR uses a set of queries to directly learn triplets, PSGFormer separately models the objects and relations in the form of queries from two Transformer decoders, followed by a prompting-like relation-object matching mechanism. In the end, we share insights on open challenges and future directions.
https://arxiv.org/abs/2207.11247


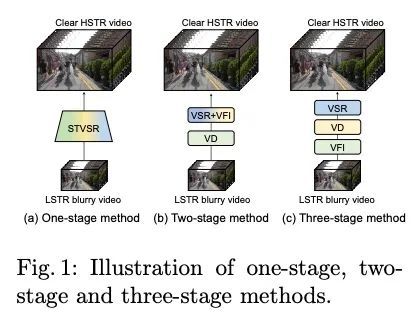
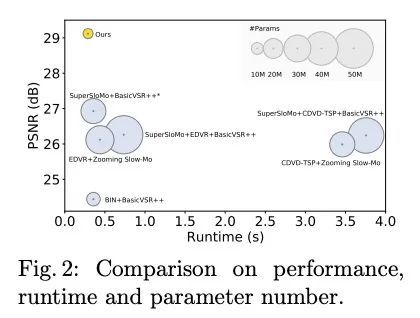
4、[CV] Towards Interpretable Video Super-Resolution via Alternating Optimization
J Cao, J Liang, K Zhang, W Wang, Q Wang, Y Zhang, H Tang, L V Gool
[ETH Zurich]
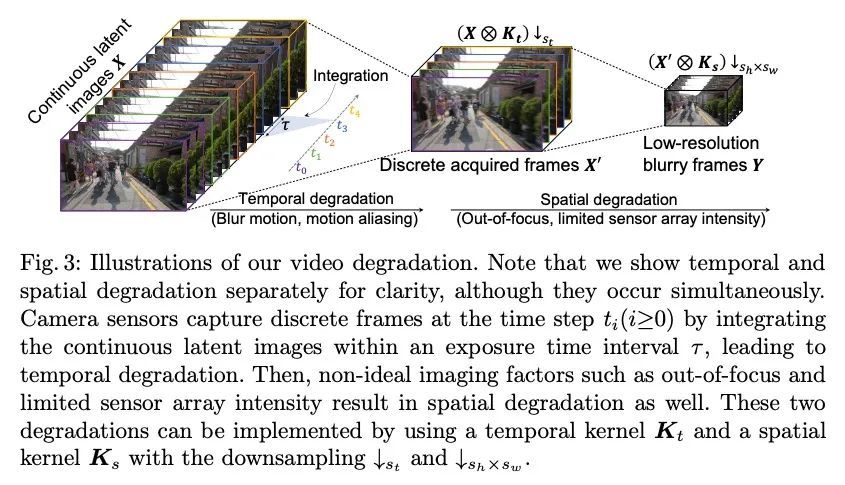
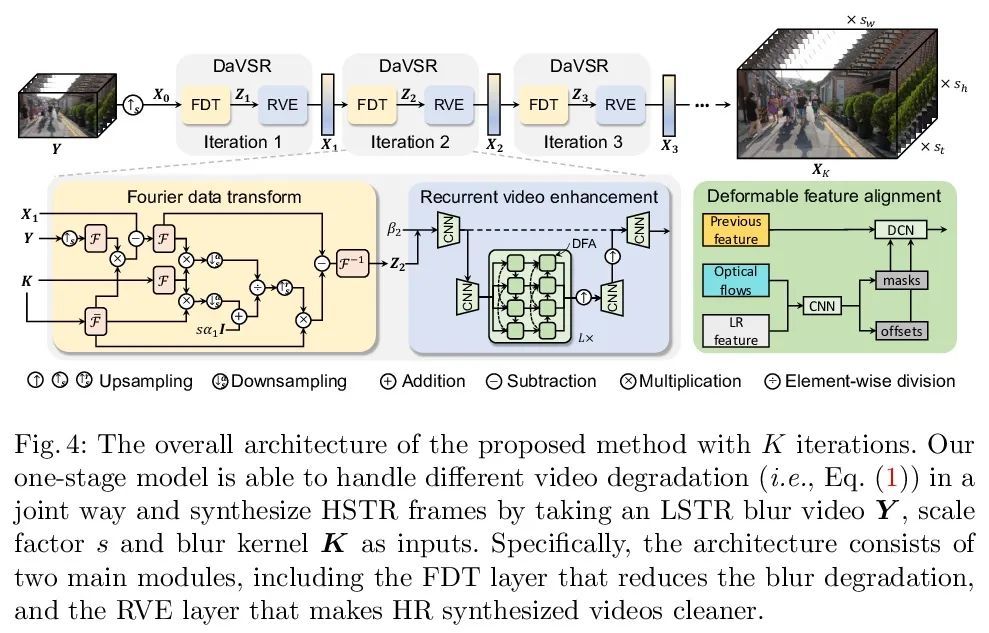
基于交替优化的可解释视频超分辨率。本文研究了一个实用的时空视频超分辨率(STVSR)问题,该问题旨在从低帧率低分辨率模糊视频中生成高帧率高分辨率的视频。当用低帧率和低分辨率摄像机记录快速动态事件时,经常会出现这样的问题,拍摄的视频会出现三种典型的问题:i)由于物体/摄像机在曝光时间内的运动而出现运动模糊;ii)当事件的时间频率超过时间采样的奈奎斯特极限时,运动混叠不可避免;iii)由于空间采样率低,高频细节丢失。这些问题可通过三个独立的子任务级联来缓解,包括视频去模糊、帧插值和超分辨率,然而,这将无法捕捉到视频序列之间的空间和时间相关性。为解决这个问题,本文提出一种可解释的STVSR框架,利用基于模型和学习的方法。将STVSR表述为一个联合的视频去模糊、帧插值和超分辨率问题,并以另一种方式将其作为两个子问题解决。对于第一个子问题,本文推导出一个可解释的分析解决方案,并将其作为一个傅里叶数据转换层。为第二个子问题提出了一种递归视频增强层,以进一步恢复高频细节。大量实验证明了所提出方法在定量指标和视觉质量方面的优越性。
In this paper, we study a practical space-time video superresolution (STVSR) problem which aims at generating a high-framerate high-resolution sharp video from a low-framerate low-resolution blurry video. Such problem often occurs when recording a fast dynamic event with a low-framerate and low-resolution camera, and the captured video would suffer from three typical issues: i) motion blur occurs due to object/camera motions during exposure time; ii) motion aliasing is unavoidable when the event temporal frequency exceeds the Nyquist limit of temporal sampling; iii) high-frequency details are lost because of the low spatial sampling rate. These issues can be alleviated by a cascade of three separate sub-tasks, including video deblurring, frame interpolation, and super-resolution, which, however, would fail to capture the spatial and temporal correlations among video sequences. To address this, we propose an interpretable STVSR framework by leveraging both modelbased and learning-based methods. Specifically, we formulate STVSR as a joint video deblurring, frame interpolation, and super-resolution problem, and solve it as two sub-problems in an alternate way. For the first sub-problem, we derive an interpretable analytical solution and use it as a Fourier data transform layer. Then, we propose a recurrent video enhancement layer for the second sub-problem to further recover highfrequency details. Extensive experiments demonstrate the superiority of our method in terms of quantitative metrics and visual quality.
https://arxiv.org/abs/2207.10765

5、[CV] Multiface: A Dataset for Neural Face Rendering
C Wuu, N Zheng, S Ardisson, R Bali, D Belko, E Brockmeyer, L Evans, T Godisart, H Ha, A Hypes, T Koska, S Krenn...
[Meta Reality Labs Research]
Multiface:神经人脸渲染数据集。近年来,逼真的人脸化身已经取得了长足的进步,但由于缺乏公开的、高质量的数据集,包括密集多视角相机捕捉和丰富的人脸表情,这一领域的研究受到限制。本文提出Multiface,一个新的多视角、高分辨率人脸数据集,从Reality Labs Research的13个身份中收集而来,用于神经人脸渲染。本文构建了Mugsy,一个大规模的多摄像头装置,用于捕捉高分辨率的人脸表现的同步视频。Multiface的目标是弥补学术界在获得高质量数据方面的差距,并实现VR远程呈现的研究。随着数据集的发布,本文对不同模型架构对模型的插值能力的影响进行了消融研究。以条件VAE模型作为基线,结果发现,增加空间偏差、纹理翘曲场和残差连接可以提高新视图合成的性能。
Photorealistic avatars of human faces have come a long way in recent years, yet research along this area is limited by a lack of publicly available, high-quality datasets covering both, dense multi-view camera captures, and rich facial expressions of the captured subjects. In this work, we present Multiface, a new multi-view, high-resolution human face dataset collected from 13 identities at Reality Labs Research for neural face rendering. We introduce Mugsy, a large scale multi-camera apparatus to capture high-resolution synchronized videos of a facial performance. The goal of Multiface is to close the gap in accessibility to high quality data in the academic community and to enable research in VR telepresence. Along with the release of the dataset, we conduct ablation studies on the influence of different model architectures toward the model’s interpolation capacity of novel viewpoint and expressions. With a conditional VAE model [8] serving as our baseline, we found that adding spatial bias, texture warp field, and residual connections improves performance on novel view synthesis. Our code and data is available at: https:// github.com/facebookresearch/multiface.
https://arxiv.org/abs/2207.11243





另外几篇值得关注的论文:
[CV] BRACE: The Breakdancing Competition Dataset for Dance Motion Synthesis
BRACE:面向舞蹈动作合成的霹雳舞比赛数据集
D Moltisanti, J Wu, B Dai, C C Loy
[University of Edinburgh & Nanyang Technological University & Shanghai AI Laboratory]
https://arxiv.org/abs/2207.10120




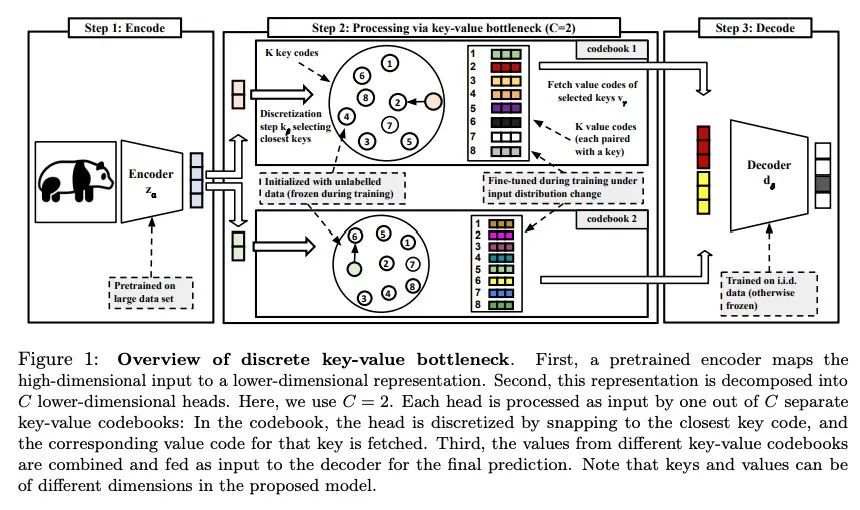
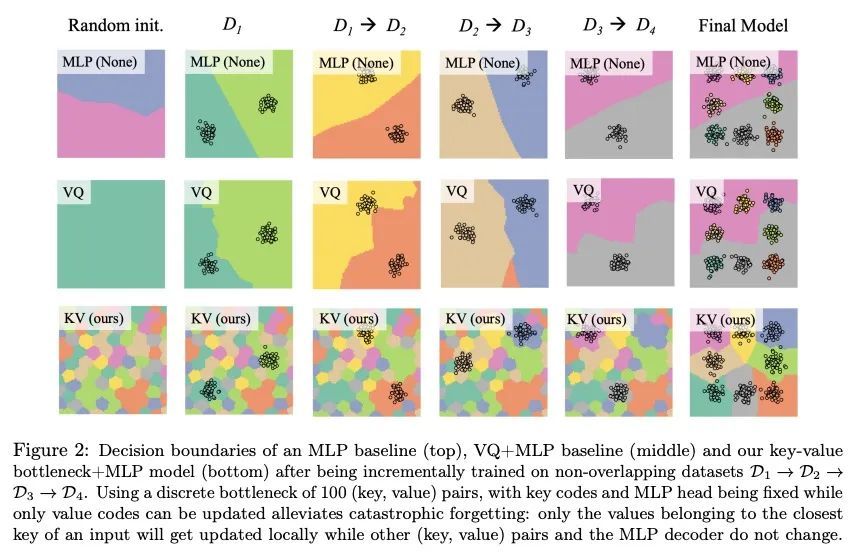
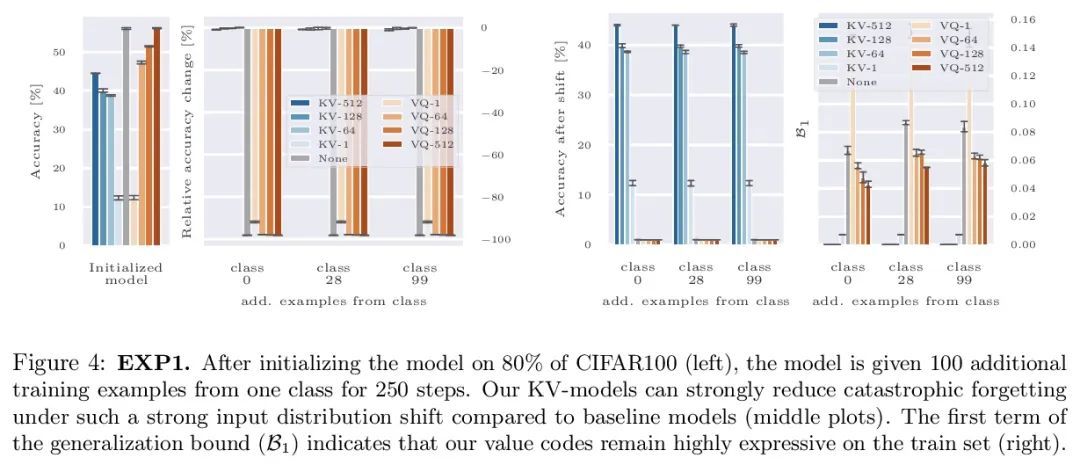
[LG] Discrete Key-Value Bottleneck
离散键值瓶颈
F Träuble, A Goyal, N Rahaman, M Mozer, K Kawaguchi, Y Bengio, B Schölkopf
[Max Planck Institute for Intelligent Systems & Mila & Google Research & National University of Singapore]
https://arxiv.org/abs/2207.11240

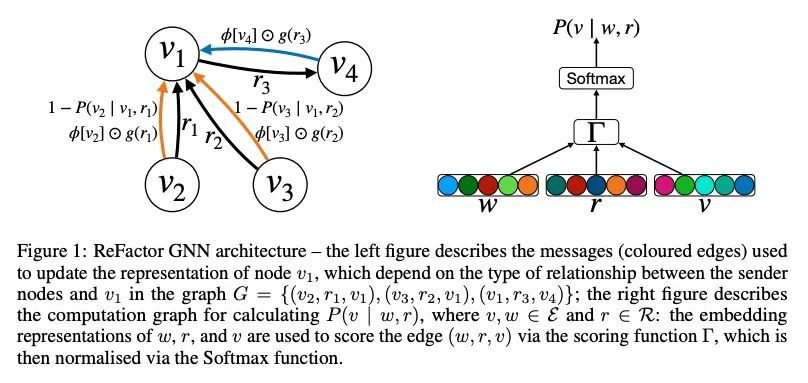
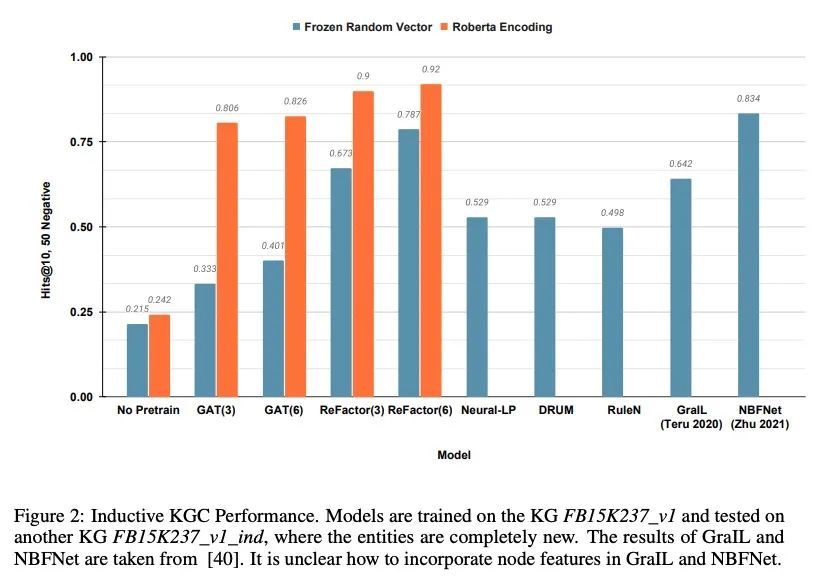
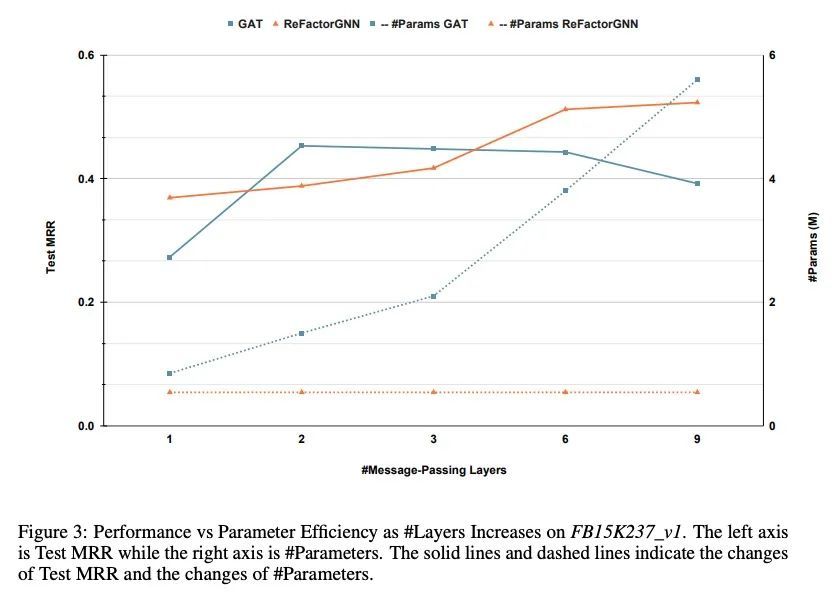
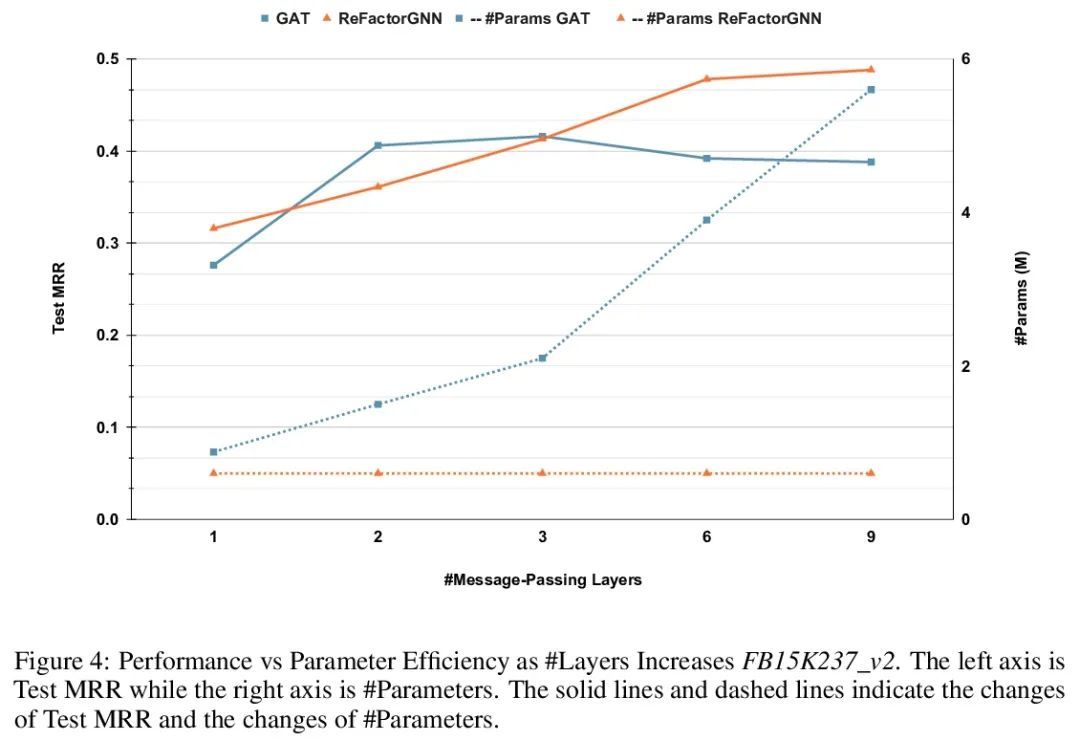
[LG] ReFactorGNNs: Revisiting Factorisation-based Models from a Message-Passing Perspective
ReFactorGNNs:从消息传递角度重新审视基于因子分解模型
Y Chen, P Mishra, L Franceschi, P Minervini...
[UCL Centre for Artificial Intelligence & Meta AI & Amazon Web Services]
https://arxiv.org/abs/2207.09980

[LG] BigIssue: A Realistic Bug Localization Benchmark
BigIssue:现实Bug定位基准
P Kassianik, E Nijkamp, B Pang, Y Zhou, C Xiong
[Salesforce Research]
https://arxiv.org/abs/2207.10739


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢